本文簡介:本文使用Python制作爬蟲,來爬取《英雄聯盟》《王者榮耀》《神之浩劫》等游戲官方網站的英雄皮膚圖片。可以作為新手爬蟲的練手實戰案例!!
愛打游戲的各位肯定也是對游戲里面制作精美,嫵媚無比或是帥氣逼人的皮膚有一種莫名的熱愛吧哈哈哈哈!對于騰訊的這三款MOBA游戲,其中《王者榮耀》和《英雄聯盟》大部分人可能都不會陌生,反正沒玩過肯定也聽過。對于MOBA游戲,總會讓人感嘆:不怕神一樣的對手,就怕豬一樣的隊友。。。。。。當然自己也有一頓操作猛如虎,一看操作0-5的經歷。
在瀏覽這些游戲官方網站的時候發現英雄的皮膚很好看,例如這一張:
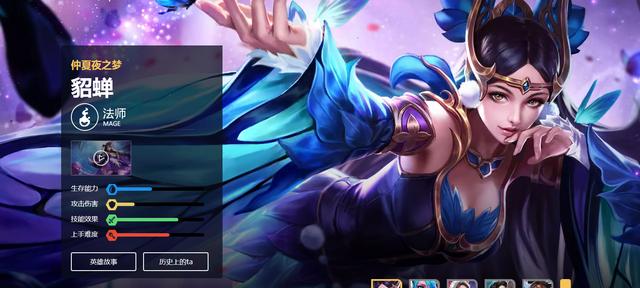
想拿這張來做電腦壁紙,于是就打開開發者工具找到了這張壁紙的地址下載下來。但是我還想要趙云的其他皮膚壁紙,還想要其他英雄的所有皮膚壁紙,還想要《英雄聯盟》《神之浩劫》的皮膚壁紙,這樣就用到爬蟲啦!!
- 這里主要講解《王者榮耀》的爬取方法,其他類似。《王者榮耀》所有英雄
首先進入所有英雄列表,你會看到下圖:
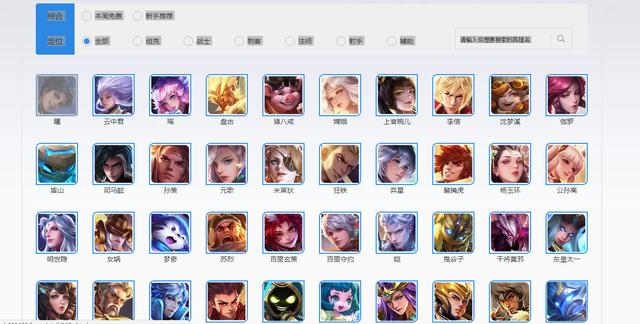
在這個網頁中包含了所有的英雄,頭像及英雄名稱。
- 單個英雄
點擊其中一個英雄的頭像,例如第一個“虞姬”,進去后如下圖:
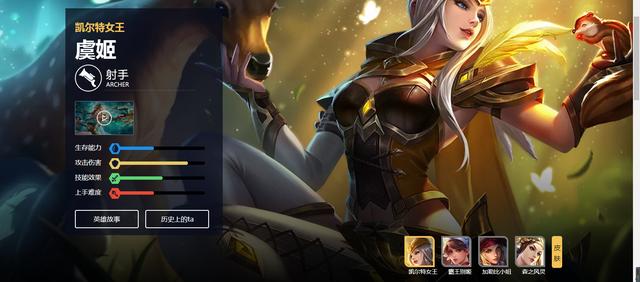
- “虞姬”里面有兩個皮膚圖片(如右下角所示)。我們就是要抓取這樣的圖片(注意:不是右下角那四張小圖,而是如上圖所示中的大圖)。在這個網頁中查看“虞姬”的網址,可以看到網址是:https://pvp.qq.com/web201605/herodetail/174.shtml。其實網址中174.shtml以前的字符都是不變的,變化的只是174.shtml。那么174是什么呢?乍一看毫無意義,其實它是“虞姬”這個英雄所對應的數字(我也不知道為啥這樣對應!!)。也就是說,要想爬取圖片你就應該進入每個英雄皮膚圖片所在的網址。就像上圖所示的“虞姬”。而要爬取所有英雄的圖片,就應該有所有單個英雄的網址。所有英雄的網址的關鍵就是每個英雄對應的數字。那么這些數字怎么找呢?英雄數字
在所有英雄列表中,打開瀏覽器的開發者工具(F12),刷新,找到一個json格式的文件,如圖所示:
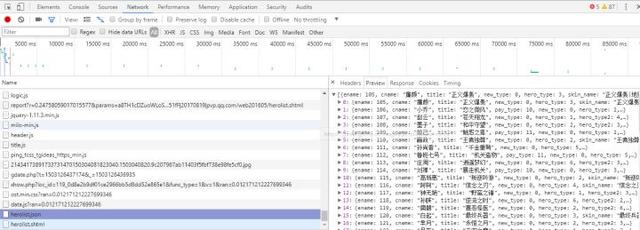
這時就會看到所有英雄對應的數字了。在上圖所示的Headers中可以找到該json文件對應的網址形式。將其導入Python,把這些數字提取出來,然后模擬出所有英雄的網址即可(網址的格式在上一小節中已經提過了)。
前面幾個小節的代碼如下(我的是Ubuntu(Linux)系統):
#爬取王者榮耀英雄圖片#導入所需模塊import requestsimport reimport os#導入json文件(里面有所有英雄的名字及數字)url='http://pvp.qq.com/web201605/js/herolist.json' #英雄的名字jsonhead={'User-Agent':'換成你自己的head'}html = requests.get(url,headers = head)html=requests.get(url)html_json=html.json()#提取英雄名字和數字hero_name=list(map(lambda x:x['cname'],html_json)) #名字hero_number=list(map(lambda x:x['ename'],html_json)) #數字- 下載圖片
現在可以進入所有英雄的網址了,可以爬取網址下的圖片了。進入一個英雄的網址,打開開發者工具,在NetWork下刷新并找到英雄的皮膚圖片(記住是大圖)。如圖所示:
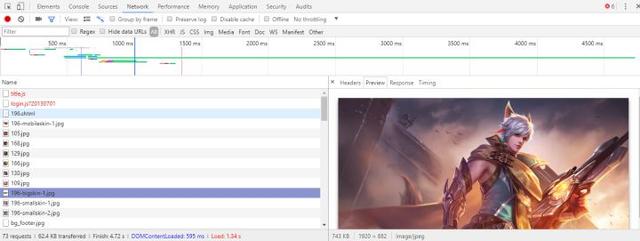
然后在Headers中查看該圖片的網址。會發現皮膚圖片是有規律的。我們可以用這樣的方式來模擬圖片網址:'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(v)+'/'+str(v)+'-bigskin-'+str(u)+'.jpg',在該網址中只有str(v)與str(u)是改變的(str( )是Python中的一個函數),str(v)是英雄對應的數字,str(u)只是圖片編號,例如第一個圖片就是1,第二個就是2,第三個。。。。。。而一個英雄的皮膚應該不會超過12個(如果你不放心可以將這個值調到20等)。既然英雄皮膚的網址也有了,下面就是下載了!!
下載的代碼如下(有些地址要換成你自己的):
def main(): #用于下載并保存圖片 ii=0 for v in hero_number: os.mkdir("/home/wajuejiprince/圖片/WZRY/"+hero_name[ii]) #換成你自己的 os.chdir("/home/wajuejiprince/圖片/WZRY/"+hero_name[ii]) #換成你自己的 ii=ii+1 for u in range(12): onehero_links='http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(v)+'/'+str(v)+'-bigskin-'+str(u)+'.jpg' im = requests.get(onehero_links) if im.status_code == 200: iv=re.split('-',onehero_links) open(iv[-1], 'wb').write(im.content)執行完上面的代碼后只需要執行main函數就行了
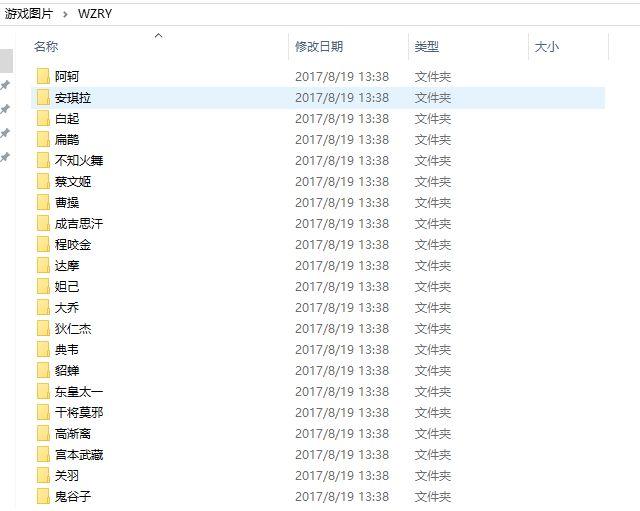
main()爬取下來的圖片是這樣,每個文件夾里面是該英雄對應的圖片,如下圖:
- 《英雄聯盟》(美服)(兩種方法)
這兩種方法的區別就在于:第一種不用觀察圖片規律,直接提取圖片網址;第二種和抓取《王者榮耀》類似,都是模擬圖片地址。
- 第一種
這一種是在提取圖片網址的時候直接使用正則表達式來匹配出圖片網址。代碼如下:
#導入模塊import requestsimport refrom bs4 import BeautifulSoupimport os得到英雄的名字:
url='http://ddragon.leagueoflegends.com/cdn/6.24.1/data/en_US/champion.json' #json里面含有所有英雄的名字def get_hero_name(url): head={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/59.0.3071.109 Chrome/59.0.3071.109 Safari/537.36'} html = requests.get(url,headers = head) heml_json=html.json() hero_name=heml_json['data'].keys() list_of_nameMax=list(hero_name) #此時的英雄名字的首字母是大寫 list_of_nameMin=[] #此時的名字就是小寫了 for ii in list_of_nameMax: name=ii.lower() list_of_nameMin.append(name) return list_of_nameMin 定義下載一個英雄圖片的函數:
def get_onehero_img(name): #下載一個英雄的所有皮膚圖片 url2='http://gameinfo.na.leagueoflegends.com/en/game-info/champions/'+name+'/' head={'User-Agent':'你自己的headers'} html = requests.get(url2,headers=head) contents=html.text soup=BeautifulSoup(contents) hero_img=soup.findAll('img') reg=re.compile(r'"http://ddragon.leagueoflegends.com/cdn/img/.*?.jpg"',re.S) hero_img_links=re.findall(reg,str(hero_img)) return hero_img_links下載保存圖片(保存地址要改):
def main(): #用于下載并保存圖片 list_name=list_of_name for i in list_name: os.mkdir("/home/wajuejiprince/圖片/LOL/"+i) os.chdir("/home/wajuejiprince/圖片/LOL/"+i) ashe=get_onehero_img(i) for j in ashe: im=re.sub('"','',j) ir = requests.get(im) if ir.status_code == 200: ip=re.sub('"','',j) iu=re.split('/',im) open(iu[-1], 'wb').write(ir.content)執行:
if __name__ == "__main__": list_of_name=get_hero_name(url) main()- 第二種
import requestsimport reimport os得到英雄名字:
url='http://ddragon.leagueoflegends.com/cdn/6.24.1/data/en_US/champion.json' #json里面含有所有英雄的名字def get_hero_nameMax(url): head={'User-Agent':'你自己的headers'} html = requests.get(url,headers = head) heml_json=html.json() hero_name=heml_json['data'].keys() list_of_nameMax=list(hero_name) #此時的英雄名字的首字母是大寫 return list_of_nameMax下載圖片(保存地址要改):
onehero_links=[]list_of_nameMax=get_hero_nameMax(url)def main(): #用于下載并保存圖片 for fn in list_of_nameMax: os.mkdir("/home/wajuejiprince/圖片/LOL2/"+fn) os.chdir("/home/wajuejiprince/圖片/LOL2/"+fn) for v in range(20): onehero_links='http://ddragon.leagueoflegends.com/cdn/img/champion/splash/'+fn+'_'+str(v)+'.jpg' im = requests.get(onehero_links) if im.status_code == 200: iv=re.split('/',onehero_links) open(iv[-1], 'wb').write(im.content)執行:
main()- 《神之浩劫》(美服)
import requestsimport reimport osurl='https://www.smitegame.com/gods/'head={'User-Agent':'你的head'}html = requests.get(url,headers = head)reg=re.compile(r'href="(.*?)"> ',re.S) items2=re.findall(reg2,html_hero.text) del items2[0] return items2#每個英雄的名字hero_name=list(map(lambda x:re.split('/',x)[-2],hero_url))def main(): #用于下載并保存圖片 ii=0 for v in hero_url: os.mkdir("/home/wajuejiprince/圖片/Smite/"+hero_name[ii]) os.chdir("/home/wajuejiprince/圖片/Smite/"+hero_name[ii]) ii=ii+1 one_hero=[] one_hero=one_hero_picture(v) for u in one_hero: im = requests.get(u) if im.status_code == 200: iv=re.split('/',u) open(iv[-1], 'wb').write(im.content)main()對于《神之浩劫》的代碼有些英雄在json文件中的名字還不是該英雄網址的名字,記得應該是孫悟空等,只需將hero_name中這些英雄的名稱改對即可(我沒有改,所以沒有下全)。
- 最后--美圖欣賞
蔡文姬:

狄仁杰:

賈克斯:

阿格尼:

嫦娥:

敖廣:

ok,這樣想要的皮膚圖片就都出來啦!大家可以留言看看有沒有志同道合的喜愛同款皮膚的伙伴哈哈哈哈~












)


)


)
