注:本文原創,轉載請標明出處。
歡迎轉發、關注微信公眾號:Q的博客。 不定期發送干貨,實踐經驗、系統總結、源碼解讀、技術原理。
本文目的
筆者期望通過系列文章幫助讀者深入理解Raft協議并能付諸于工程實踐中,同時解讀不易理解或容易誤解的關鍵點。
該系列會從原理、源碼、實踐三個部分為大家講解Raft算法,本文為《Raft實戰》系列第二篇:
原理部分我們會結合 Raft 論文講解 Raft 算法思路,整體分篇會遵循 Raft 的模塊化思想,分別講解 Leader election、Log replication、Safety、Cluster membership change、Log compaction 等。
源碼部分我們會通過分析 hashicorp/raft 來學習一個工業界的 Raft 實現,hashicorp/raft 是 Consul 的底層依賴。
實踐部分我們會基于 hashicorp/raft 來實現一個簡單的分布式 kv 存儲,以此作為系列的收尾。
什么是選主
選主(Leader election)就是在分布式系統內抉擇出一個主節點來負責一些特定的工作。在執行了選主過程后,集群中每個節點都會識別出一個特定的、唯一的節點作為leader。
我們開發的系統如果遇到選主的需求,通常會直接基于 zookeeper 或 etcd 來做,把這部分的復雜性收斂到第三方系統。然而作為 etcd 基礎的 raft 自身也存在“選主”的概念,這是兩個層面的事情:基于 etcd 的選主指的是利用第三方 etcd 讓集群對誰做主節點的決策達成一致,技術上來說利用的是 etcd 的一致性狀態機、lease 以及 watch 機制,這個事情也可以改用單節點的 MySQL/Redis 來做,只是無法獲得高可用性;而 raft 本身的選主則指的是在 raft 集群自身內部通過票選、心跳等機制來協調出一個大多數節點認可的主節點作為集群的 leader 去協調所有決策。
當你的系統利用 etcd 來寫入誰是主節點的時候,這個決策也在 etcd 內部被它自己集群選出的主節點處理并同步給其它節點。
Raft 為什么要進行選主?
按照論文所述,原生的 Paxos 算法使用了一種點對點(peer-to-peer)的方式,所有節點地位是平等的。在理想情況下,算法的目的是制定一個決策,這對于簡化的模型比較有意義。但在工業界很少會有系統會使用這種方式,當有一系列的決策需要被制定的時候,先選出一個 leader 節點然后讓它去協調所有的決策,這樣算法會更加簡單快速。
此外,和其它一致性算法相比,raft 賦予了 leader 節點更強的領導力,稱之為 Strong Leader。比如說日志條目只能從 leader 節點發送給其它節點而不能反著來,這種方式簡化了日志復制的邏輯,使 raft 變得更加簡單易懂。
Raft選主過程
下圖的節點狀態轉移圖,我們在前一篇文章已經看到了,但只是做了簡單的描述,接下來我們會結合具體的Leader election細節來深刻理解節點的狀態轉換。
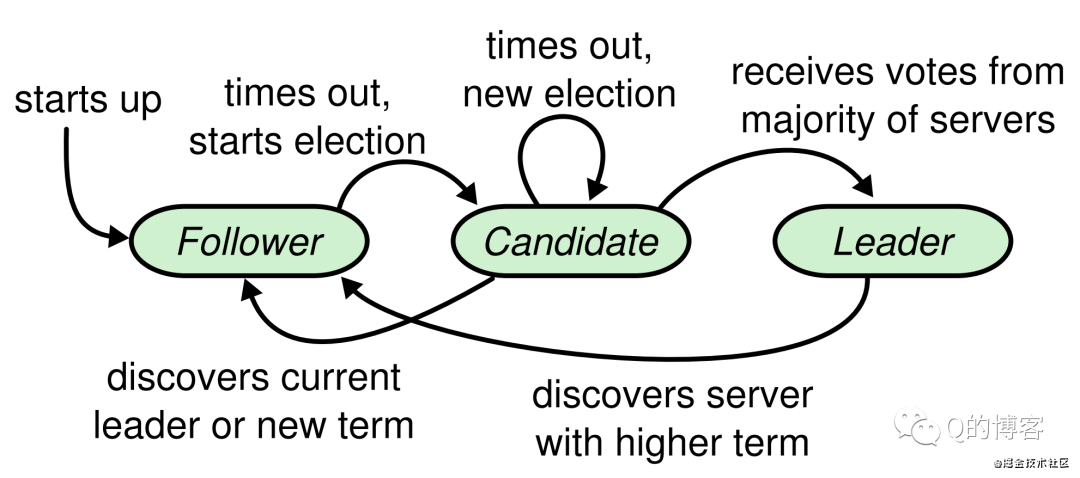
*圖名:節點狀態圖
Follower狀態轉移過程
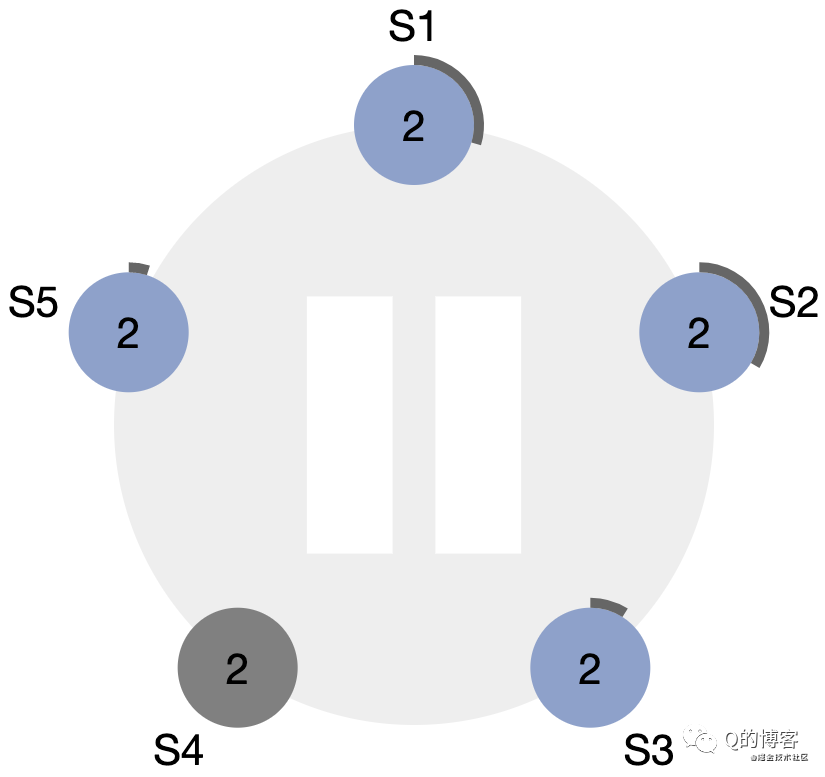
Raft 的選主基于一種心跳機制,集群中每個節點剛啟動時都是 follower 身份(Step: starts up),leader 會周期性的向所有節點發送心跳包來維持自己的權威,那么首個 leader 是如何被選舉出來的呢?方法是如果一個 follower 在一段時間內沒有收到任何心跳,也就是選舉超時,那么它就會主觀認為系統中沒有可用的 leader,并發起新的選舉(Step: times out, starts election)。
這里有一個問題,即這個“選舉超時時間”該如何制定?如果所有節點在同一時刻啟動,經過同樣的超時時間后同時發起選舉,整個集群會變得低效不堪,極端情況下甚至會一直選不出一個主節點。Raft 巧妙的使用了一個隨機化的定時器,讓每個節點的“超時時間”在一定范圍內隨機生成,這樣就大大的降低了多個節點同時發起選舉的可能性。
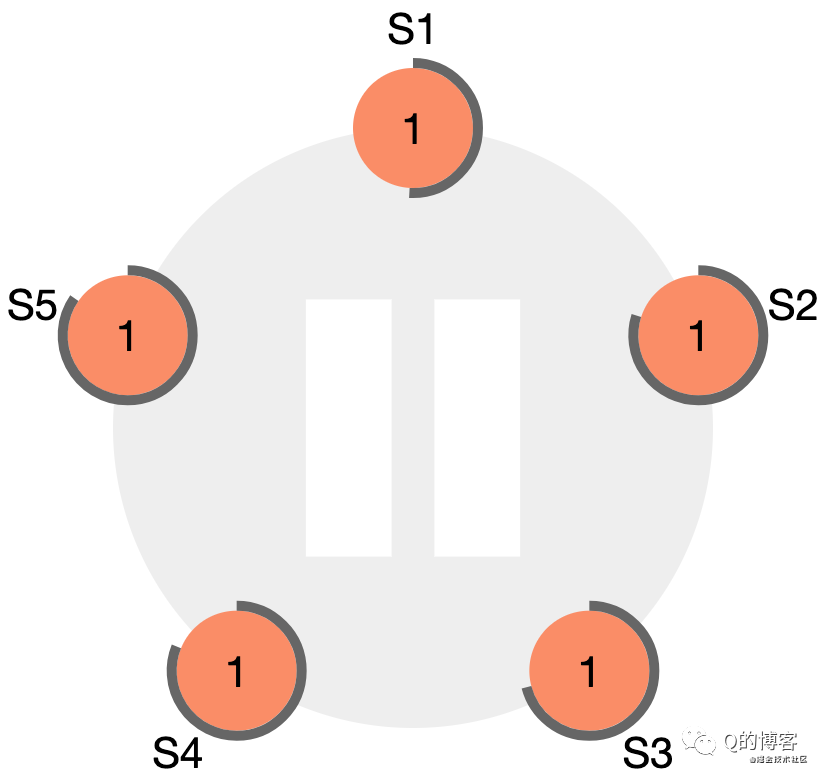
*圖解:一個五節點Raft集群的初始狀態,所有節點都是follower身份,term為1,且每個節點的選舉超時定時器不同
若 follower 想發起一次選舉,follower 需要先增加自己的當前 term,并將身份切換為 candidate。然后它會向集群其它節點發送“請給自己投票”的消息(RequestVote RPC)。
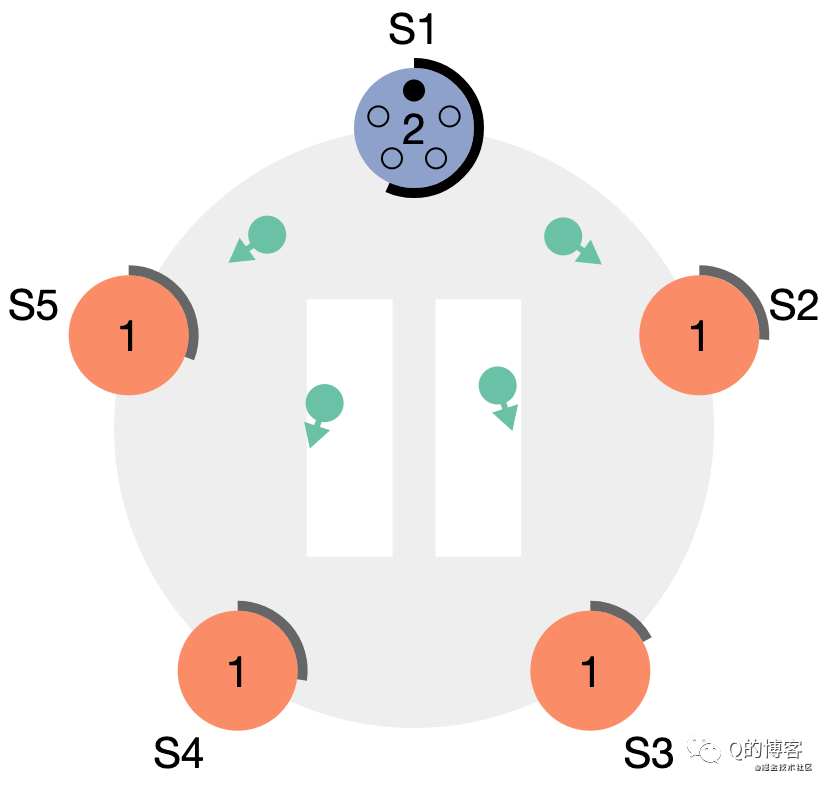
*圖解:S1 率先超時,變為 candidate,term + 1,并向其它節點發出拉票請求
Candicate狀態轉移過程
Follower 切換為 candidate 并向集群其他節點發送“請給自己投票”的消息后,接下來會有三種可能的結果,也即上面節點狀態圖中 candidate 狀態向外伸出的三條線。
1. 選舉成功(Step: receives votes from majority of servers)
當candicate從整個集群的大多數(N/2+1)節點獲得了針對同一 term 的選票時,它就贏得了這次選舉,立刻將自己的身份轉變為 leader 并開始向其它節點發送心跳來維持自己的權威。
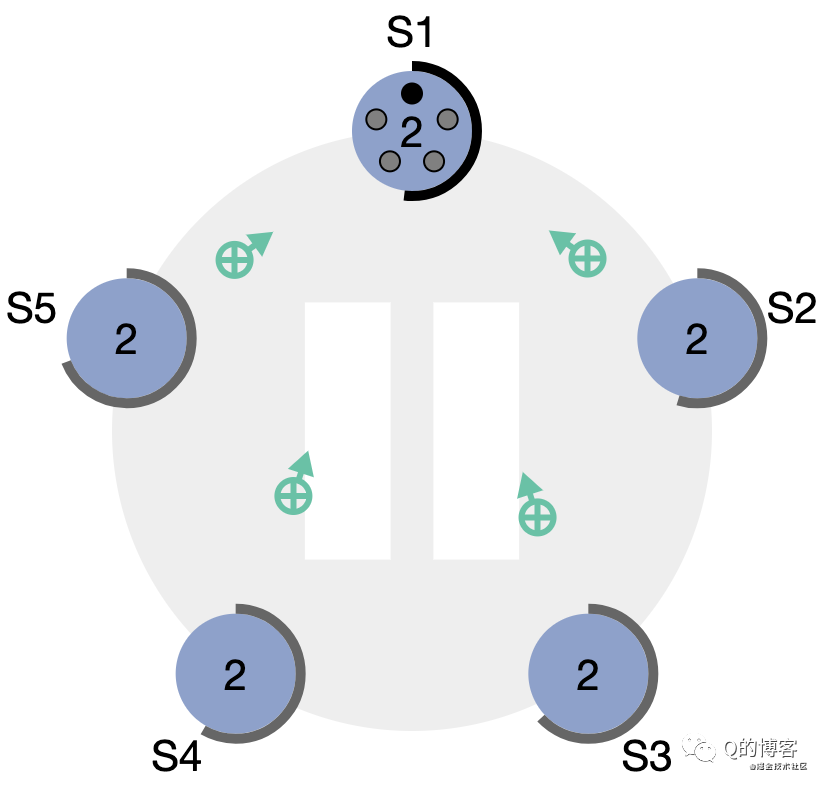
*圖解:“大部分”節點都給了S1選票
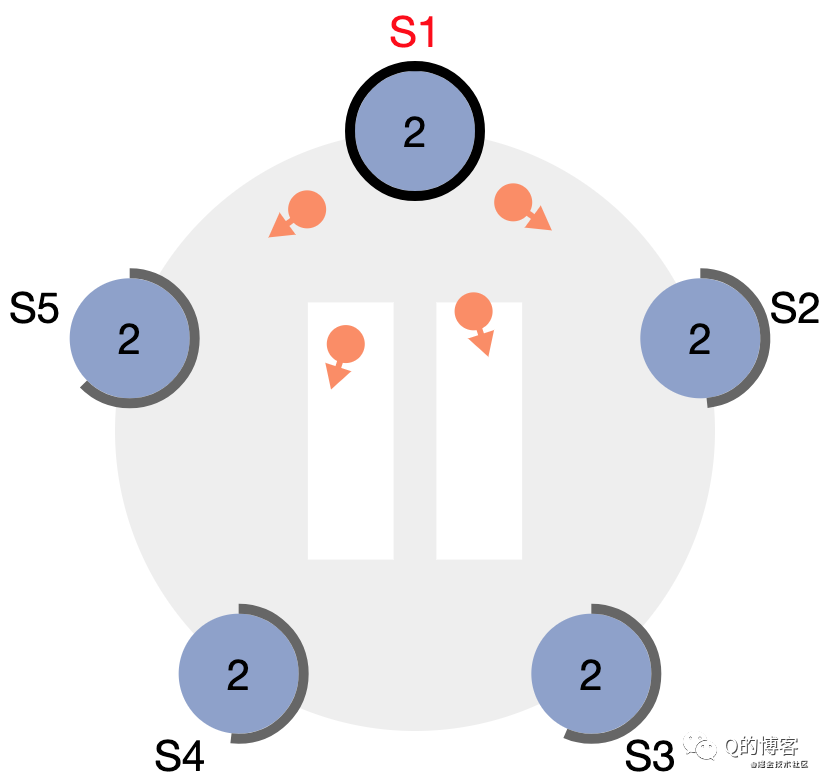
*圖解:S1變為leader,開始發送心跳維持權威
每個節點針對每個 term 只能投出一張票,并且按照先到先得的原則。這個規則確保只有一個 candidate 會成為 leader。
2. 選舉失敗(Step: discovers current leader or new term)
Candidate 在等待投票回復的時候,可能會突然收到其它自稱是 leader 的節點發送的心跳包,如果這個心跳包里攜帶的 term 不小于 candidate 當前的 term,那么 candidate 會承認這個 leader,并將身份切回 follower。這說明其它節點已經成功贏得了選舉,我們只需立刻跟隨即可。但如果心跳包中的 term 比自己小,candidate 會拒絕這次請求并保持選舉狀態。
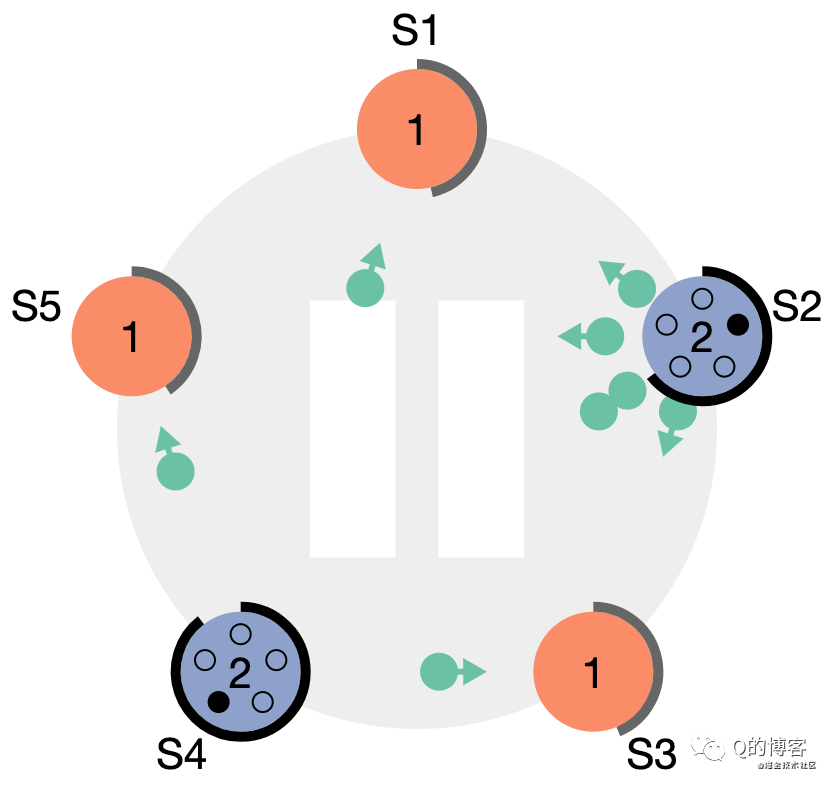
*圖解:S4、S2 依次開始選舉
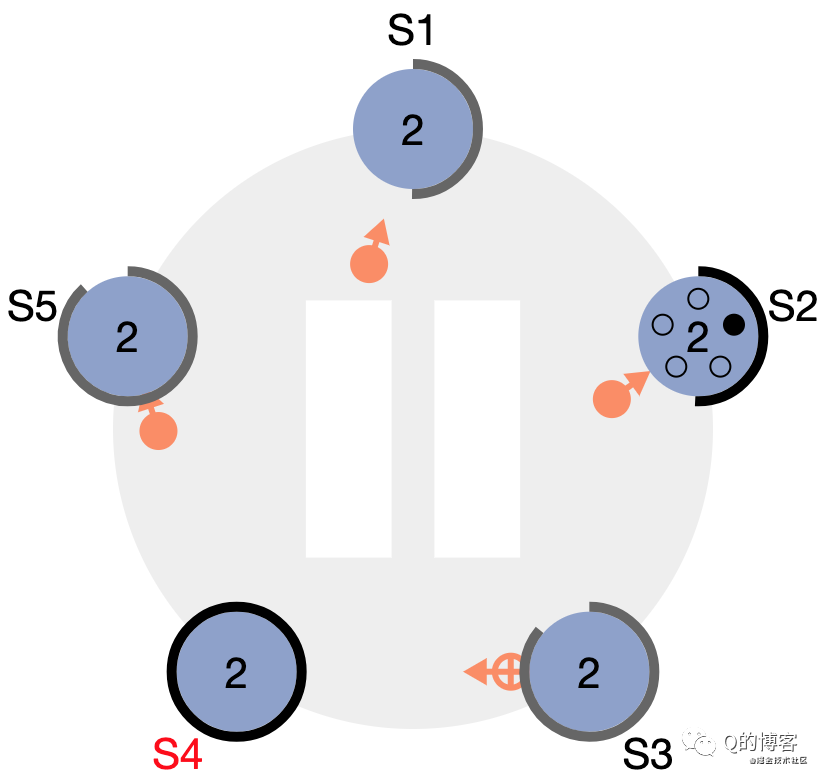
*圖解:S4 成為 leader,S2 在收到 S4 的心跳包后,由于 term 不小于自己當前的 term,因此會立刻切為 follower 跟隨S4
3. 選舉超時(Step: times out, new election)
第三種可能的結果是 candidate 既沒有贏也沒有輸。如果有多個 follower 同時成為 candidate,選票是可能被瓜分的,如果沒有任何一個 candidate 能得到大多數節點的支持,那么每一個 candidate 都會超時。此時 candidate 需要增加自己的 term,然后發起新一輪選舉。如果這里不做一些特殊處理,選票可能會一直被瓜分,導致選不出 leader 來。這里的“特殊處理”指的就是前文所述的隨機化選舉超時時間。
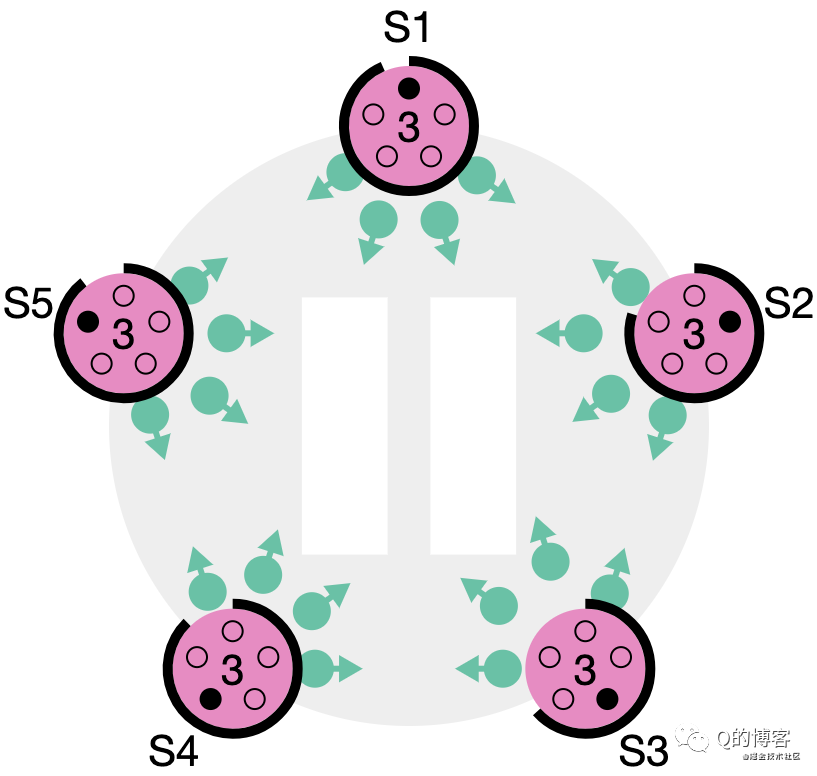
*圖解:S1~S5都在參與選舉
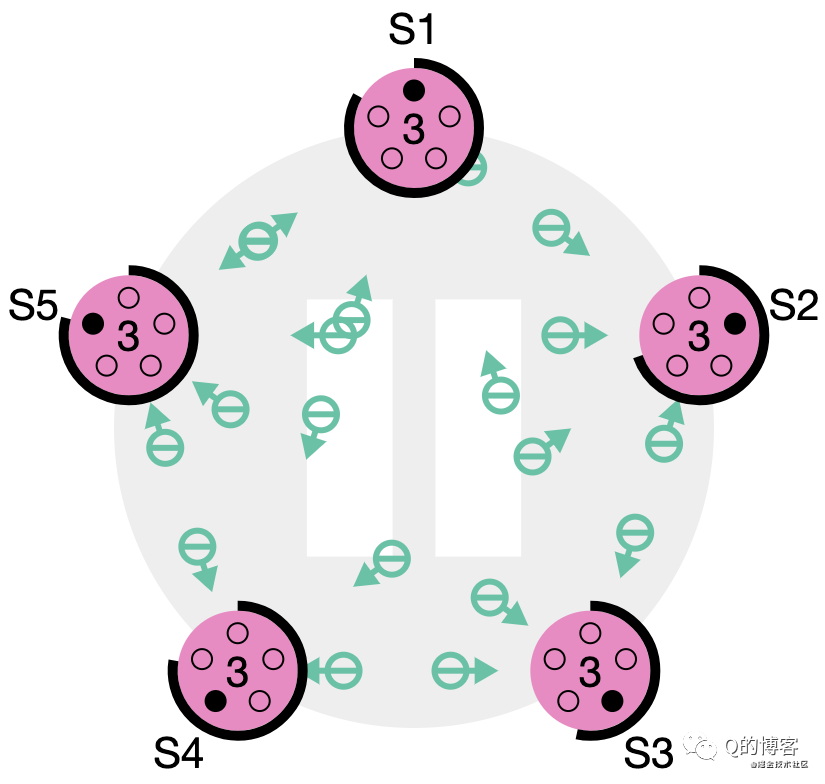
*圖解:沒有任何節點愿意給他人投票
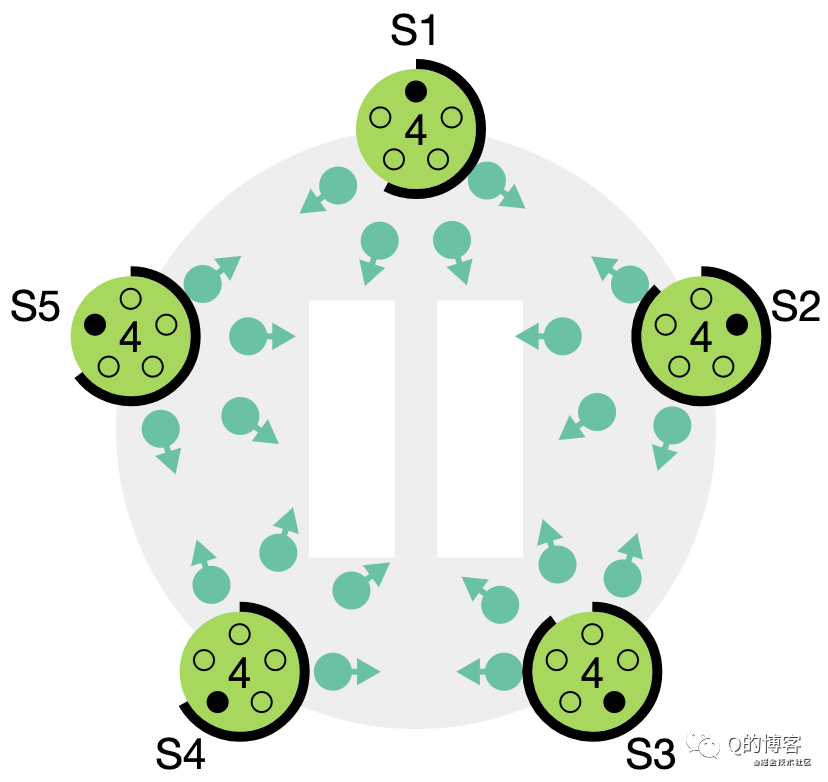
*圖解:如果沒有隨機化超時時間,所有節點將會繼續同時發起選舉……
以上便是 candidate 三種可能的選舉結果。
Leader 切換狀態轉移過程
節點狀態圖中的最后一條線是:discovers server with higher term。想象一個場景:當 leader 節點發生了宕機或網絡斷連,此時其它 follower 會收不到 leader 心跳,首個觸發超時的節點會變為 candidate 并開始拉票(由于隨機化各個 follower 超時時間不同),由于該 candidate 的 term 大于原 leader 的 term,因此所有 follower 都會投票給它,這名 candidate 會變為新的 leader。一段時間后原 leader 恢復了,收到了來自新leader 的心跳包,發現心跳中的 term 大于自己的 term,此時該節點會立刻切換為 follower 并跟隨的新 leader。
上述流程的動畫模擬如下:
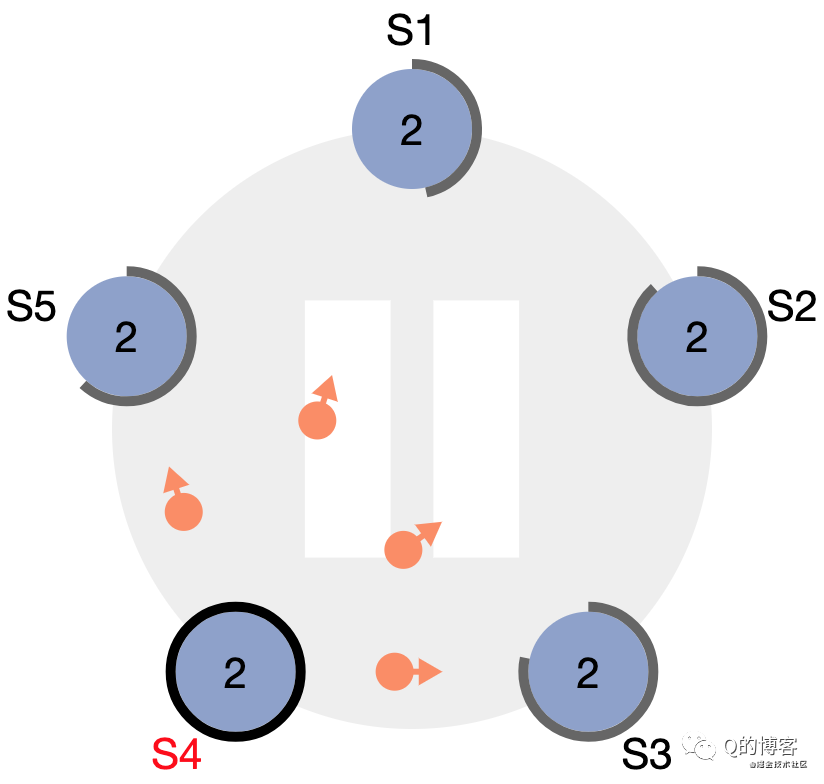
*圖解:S4 作為 term2 的 leader
*圖解:S4 宕機,S5 即將率先超時
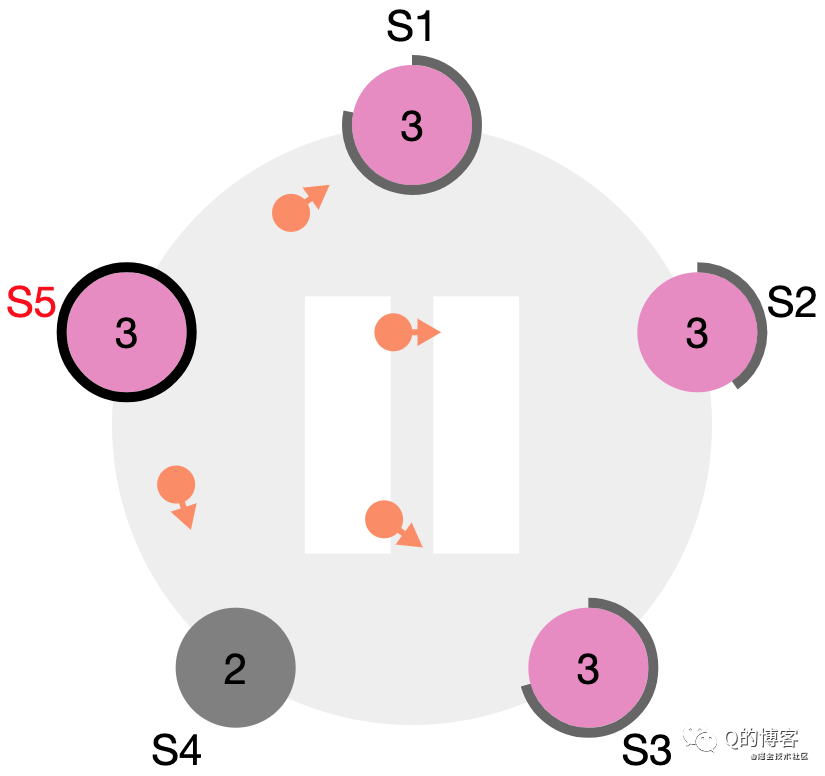
*圖解:S5 當選 term3 的 leader
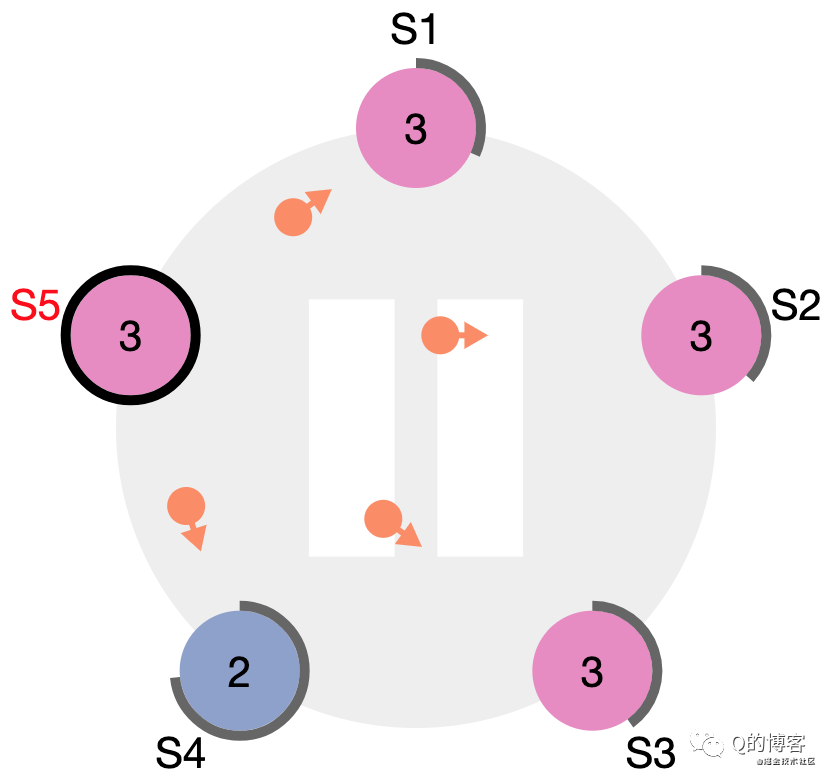
*圖解:S4 宕機恢復后收到了來自 S5 的 term3 心跳
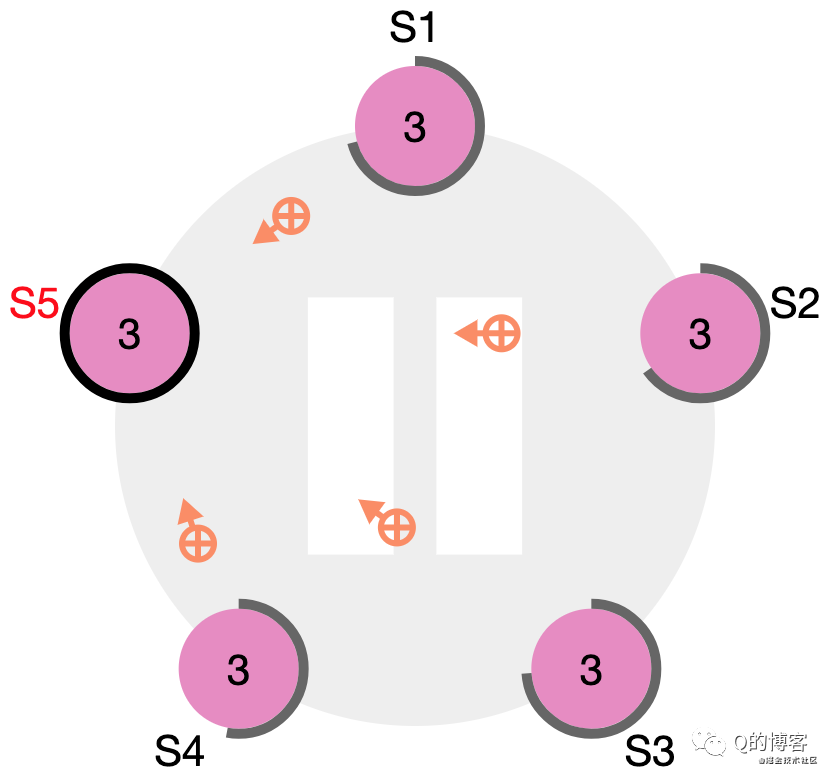
*圖解:S4 立刻變為 S5 的 follower
以上就是 raft 的選主邏輯,但還有一些細節(譬如是否給該 candidate 投票還有一些其它條件)依賴算法的其它部分基礎,我們會在后續“安全性”一篇描述。
當票選出 leader 后,leader 也該承擔起相應的責任了,這個責任是什么?就是下一篇將介紹的“日志復制”~
歡迎轉發、關注微信公眾號:Q的博客,不定期發送干貨,實踐經驗、系統總結、源碼解讀、技術原理。
)

)

)
)




)


...)

)

)

