今天由于gedit的編碼格式導致LCD顯示屏的問題,開始沒有想到后來才發現,在這記錄一下
#include <stdio.h>
#include <unistd.h>
#include <stdio.h>
#include <fcntl.h>
#include <linux/fb.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <sys/wait.h>
#include <sys/ipc.h>#define FB_NAME "/dev/fb0" //打開的幀緩沖設備名
unsigned char *fbp = 0; //文件映射的虛擬地址指針
long screensize; //沒幀圖像的大小
struct fb_var_screeninfo vinfo; //打開的幀緩沖設備的可變參數
struct fb_fix_screeninfo finfo; //打開的幀緩沖設備的不可變參數
int fp; //打開的文件描述符void show_point(unsigned int x, unsigned int y, unsigned int c)
{unsigned int location;//每個像素點的位數/8=每個像素占用的字節數location = x * (vinfo.bits_per_pixel / 8) + y * finfo.line_length;/*直接賦值來改變屏幕上某點的顏色注明:這幾個賦值是針對每像素四字節來設置的,如果針對每像素2 字節,比如RGB565,則需要進行轉化*/*(fbp + location) = c & 0xff; /* 藍色的色深 */ *(fbp + location + 1) = c >> 8 & 0xff; /* 綠色的色深*/ *(fbp + location + 2) = c >> 16 & 0xff; /* 紅色的色深*/*(fbp + location + 3) = c >> 24 & 0xff; /* 是否透明*/
}
int fB_init (void)
{fp = open (FB_NAME, O_RDWR);if (fp < 0) {printf("打開幀緩沖設備失敗\r\n");return -1;}printf("打開幀緩沖設備成功\r\n");if (ioctl(fp, FBIOGET_FSCREENINFO, &finfo)) {printf("獲得幀緩沖設備的固定參數失敗\r\n");return -1;} if (ioctl(fp, FBIOGET_VSCREENINFO, &vinfo)) {printf("獲得幀緩沖設備的可變參數失敗\r\n");return -1;}printf("識別到當前屏幕尺寸為:%d*%d 色深:%d\r\n",vinfo.xres,vinfo.yres,vinfo.bits_per_pixel);// 計算單幀畫面占多少字節screensize = vinfo.xres * vinfo.yres * (vinfo.bits_per_pixel / 8); //把fp所指的文件中從開始到screensize大小//的內容給映射出來,得到一個指向這塊空間//的指針fbp = (unsigned char *) mmap (0, screensize, PROT_READ | PROT_WRITE, MAP_SHARED, fp, 0);if (NULL == fbp) {printf ("把文件映射到虛擬內存失敗\r\n");return -1;}return 0;}
void fb_close(void )
{munmap (fbp, screensize); /*解除映射*/close (fp); /*關閉文件*/
}void Read_from_HZK16( const unsigned char *s, char* chs)
{FILE *fp;unsigned long offset;//根據內碼找出漢字在HZK16中的偏移位置offset = ((s[0] - 0xa1) * 94 + (s[1] - 0xa1)) * 32;printf("s[0]=%d\n",s[0]);printf("s[1]=%d\n",s[1]);printf("offset=%d\n",offset);//打開字庫文件if((fp = fopen("HZK16", "r")) == NULL)return; //文件指針偏移到要找的漢字處fseek(fp, offset, SEEK_SET); //讀取該漢字的字模fread(chs, 32, 1, fp); fclose(fp);
}void show_chinese_16x16(unsigned int x, unsigned int y, unsigned int fc, unsigned int bc, const unsigned char * chs)
{int i, j;char data[32];Read_from_HZK16(chs, data); //去字庫中讀取漢字字模for (i = 0; i < 32; i++) //顯示32個點{if (i % 2 == 0)y++; //每行兩字節,16X16點陣for (j = 7; j >= 0; j--) {if (data[i] & (0x1 << j))//描繪前景色 {show_point(x + (7 - j) + (i % 2) * 8, y, fc); //由高到低,} else //描繪背景色;{ show_point(x + (7 - j) + (i % 2) * 8, y, bc);}}}
}
int main(void)
{fB_init (); //初始化幀緩沖設備show_chinese_16x16(0, 0, 0xf80000ff, 0x0, "中");show_chinese_16x16(16, 0, 0xf80000ff, 0x0, "華");fb_close(); //關閉幀緩沖設備return 0;
}
上面是我在tiny4412開發板上測試LCD屏的代碼,但是當我改變顯示的數據時出現了問題,顯示的不是我想顯示的字,很奇怪啊!為什么會這樣,兩個一模一樣的代碼卻表現出來不一樣的結果。
開始考慮是從字庫取模時的問題,但是仔細檢查并沒有發現錯誤,然后把正確代碼和錯誤代碼的偏移量打印出來,僅僅看出來兩個的偏移量不同,目前為止還是找不到原因。
從串口的顯示發現了端倪,看圖:
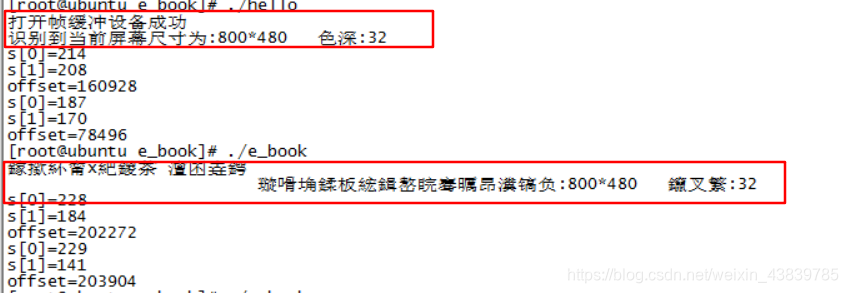
一模一樣的代碼,為什么一個是正確,一個是亂碼,考慮是我使用gedit編輯保存的,應該是編碼格式的問題,修改文件的編碼格式
在LINUX上進行編碼轉換時,可以利用iconv命令實現,這是針對文件的,即將指定文件從一種編碼轉換為另一種編碼。
iconv命令用法如下:
iconv [選項...] [文件...]
-
1.輸入/輸出格式規范:
-f, --from-code=名稱 原始文本編碼
-t, --to-code=名稱 輸出編碼 -
2.列舉所有已知的字符集 -l, --list
-
3.輸出控制:
-c 從輸出中忽略無效的字符
-o, --output=FILE 輸出文件
-s, --silent 關閉警告
--verbose 打印進度信息
例子:
iconv -f utf-8 -t gb2312 e_book.c> e_book1.c
mv e_book1.c e_book.c
修改字符編碼后查看
file e_book.c
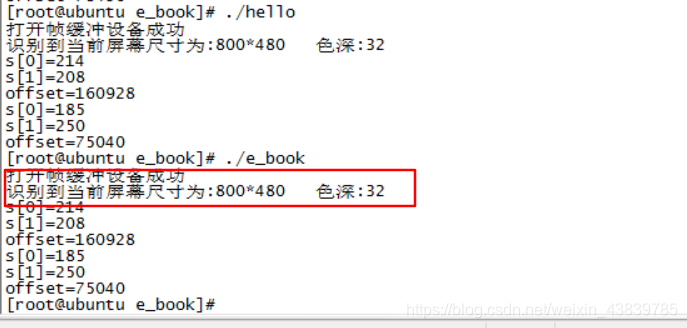
如圖:

此時再次顯示就正確了。
本文章僅供學習交流用禁止用作商業用途,文中內容來水枂編輯,如需轉載請告知,謝謝合作
微信公眾號:zhjj0729
微博:文藝to青年



)
)





)

)






