前面有多篇文章介紹過MySQL InnoDB的相關知識,今天我們要更深入一些,看看它們的內部原理和機制是如何實現的。
一、內存管理
我們知道,MySQl是一個存儲系統,數據最后都寫在磁盤上。我們以前也提到過,磁盤的速度特別是大容量的磁盤受磁頭臂的影響,速度相對內存慢很多。所以Innodb實現了自己的緩存機制。
首先我們先看下Innodb對內存是如何使用和劃分的,然后我們再看看它是如何保存熱數據的。
1、主要模塊和組成
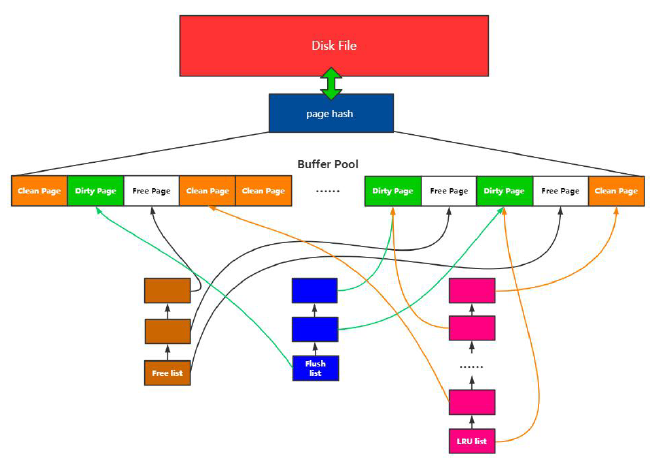
(1) Buffer Pool
預分配的內存池
(2) Page
Buffer Pool的最小單位
(3) Free list
空閑Page組成的鏈表
(4) Flush list
臟頁鏈表
(5) Page hash 表
維護內存Page和文件Page的映射關系
(6) LRU
內存淘汰算法
以上三種鏈表LRU list、Free list、Flush list 和內存池、Page hash?以及磁盤文件之間的映射關系如下圖所示:
2、LRU算法
LRU,Least Recent Used,最近最少使用。每次將剛使用過的頁面插到LRU隊列的最前端,那么最少使用的排在尾端,當緩存不夠時,淘汰尾端的頁。
很多文件系統和開源庫的內存淘汰算法都用到了LRU,以前有不少文章都提到過。
但是LRU的缺陷是,有時會無法淘汰真正的冷數據,尾端的數據可能暫時沒使用而已,不代表不使用頻繁,不代表不是熱數據。所以很多系統對LRU進行了優化。
比如Redis加了LFU(least?frequently?used最不經常使用)配合LRU一起使用。
那么InnoDB存儲引擎是如何改進的呢?如下圖,它將LRU分成兩部分,中間的分割點叫做midpoint,新讀取的頁不再是加入到最頭部,而是midpoint后面的位置,即后半截的頭部。
那么midpoint的位置是如何計算的呢,在默認配置下,離LRU整個頭部的5/8處。當然這個比例是可以根據實際業務進行設置的。但總之,可以真正將 冷熱數據分離 ,熱數據在前,冷數據在后。
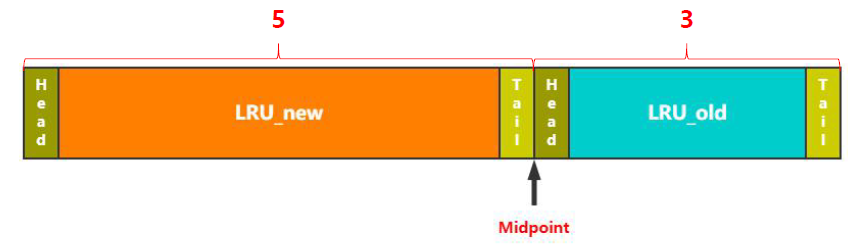
那么這兩個區的數據如何移動的呢,即冷熱數據如何切換的呢?
上面我們提到了,剛插入的頁放在old區的頭部,那么如果該頁確實訪問頻繁,不能一直呆在該位置吧。
InnoDB引入了參數innodb_old_blocks_time,如果old區的數據在該時間范圍內沒有被淘汰出去,就可以移到new區,加入到new區的頭部。這也叫做 made young 。
而如果在old呆的時間不夠innodb_old_blocks_time,而且緩存不夠時,就會面臨直接淘汰,這就叫做 made not young 。這種情況,可以發生在全表掃描的時候,保證了new區的數據才是真正的熱數據!
當然數據也有可能從 new區移動到old區 ,只是相對比較簡單了,直接移動midpoint指向的位置即可。即new區的尾巴變成了old區的頭部。
二、事務
1、 MySQL事務基本概念
事務特性
A(Atomicity原子性):全部成功或全部失敗
I(Isolation隔離性):并行事務之間互不干擾
D(Durability持久性):事務提交后,永久生效
C(Consistency一致性):通過AID保證
并發問題
臟讀(Drity Read):讀取到未提交的數據。 中間所有變化的值都可能讀到 。
不可重復讀(Non-repeatable read):兩次讀取結果不同。讀取已提交的(不一樣的值), 讀到的值變化數量比臟讀要少 。
幻讀(Phantom Read):select 操作得到的結果所表征的數據狀態 影響(無法支撐)后續的業務操作。
網上有人這樣區分,臟讀是讀取修改的數據,幻讀是讀取新提交的數據。我認為也可以,或許phantom表示 虛幻的新數據 (所以無法支撐后續操作),而drity代表了修改的意思呢?
所以,不可重復讀重點在于update和delete,而幻讀的重點在于insert。
隔離級別
Read Uncommitted(讀取未提交內容):最低隔離級別,會讀取到其他事務未提交的數據;存在 臟讀 的問題 。
Read Committed(讀取提交內容):事務過程中可以讀取到其他事務已提交的數據;存在 不可重復讀 的問題 。
Repeatable Read(可重復讀):每次讀取相同結果集,不管其他事務是否提交;存在 幻讀 的問題 。
Serializable(串行化):事務排隊,隔離級別最高,性能最差。
2、MySQL事務實現原理
從上我們可以看出事務有ACID四大特性,而“I”隔離性是通過鎖來實現的,我們下一節講述。那么其他三個特性主要通過undo/redo日志的機制來實現,這個知識點在前面有一篇文章中介紹和對比過。 現在我們站在事務實現的角度再來看看。
(1)undo log
回滾日志,顧名思義,是對事物rollback時使用。這是它核心的功能之一,但是它還有另一個非常重要的功能,MVCC。所以今天這里主要介紹它是如何在事務中發揮作用的。
MVCC
Multiversion concurrency control,多版本并發控制。當用戶讀取一行時,如果該記錄已經被其他事務占用,當前事務可以通過undo讀取之前的 行版本信息 ( 快照數據 ),以此實現 非鎖定讀 。 所以實現了非阻塞的讀操作,寫操作也只鎖定必要的行。即 解決讀-寫沖突。
快照數據就是當前行數據的歷史版本,每行記錄可能含有多個版本。那該讀取哪個版本呢?
首先,InnoDB的每行記錄或者說每條數據,除了記錄用戶定義的列之外,還有 兩個隱藏的列 :事務ID列 DB_TRX_ID 和回滾指針 DB_ROLL_PTR。 如果該表沒有定義主鍵,每行還會增加一個rowid列。 DB_TRX_ID是當時執行這條sql的事務id,DB_ROLL_PTR指向的就是undo log中修改前的行DB_ROW_ID。所以對同一條數據的修改,通過roll_pointer就形成了 undo log版本鏈 。
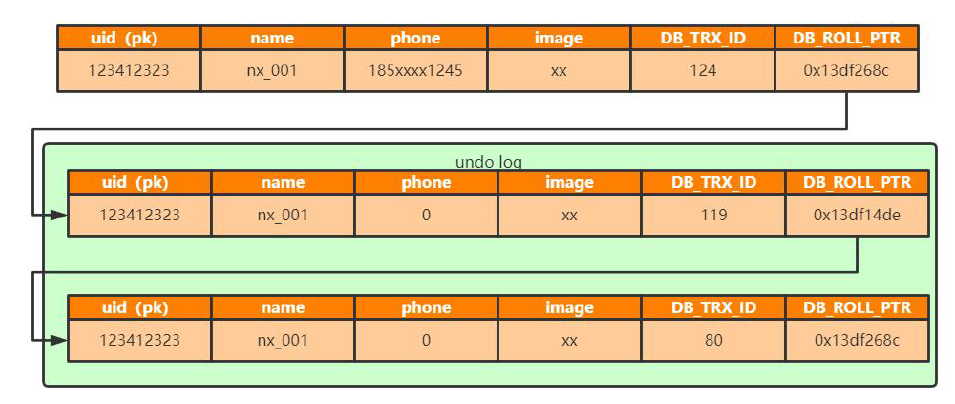
然后我們再來介紹下 Read View 快照讀。
一般情況下讀取數據時會生成一個Read View,對當前該行的可能正在進行的事務進行一個快照。
Read View中主要包含4個比較重要的內容:
m_ids:表示在生成Read View時當前系統中活躍的讀寫事務的事務id列表,簡稱 活躍列表 。
min_trx_id:表示在生成Read View時當前系統中活躍的讀寫事務中 最小的事務id ,也就是m_ids中的最小值。
max_trx_id:表示生成Read View時系統中應該分配給下一個事務的 id 值,,也就是m_ids中的 最大 值。
creator_trx_id:表示生成該Read View的事務的事務id。
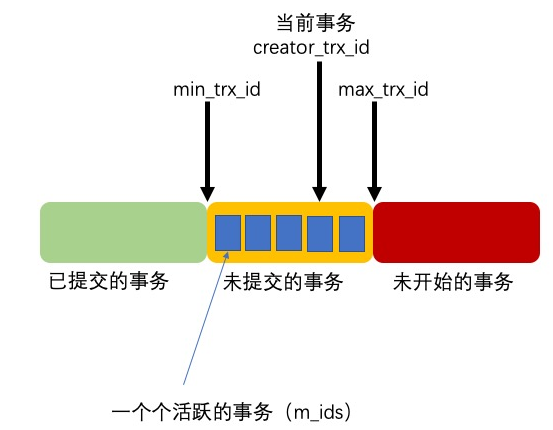
有了這些信息,這樣在訪問某條記錄時,只需要依次判斷undo log版本鏈中節點的事務ID 是否可見 ,如果可見即找到了所需要的行記錄。
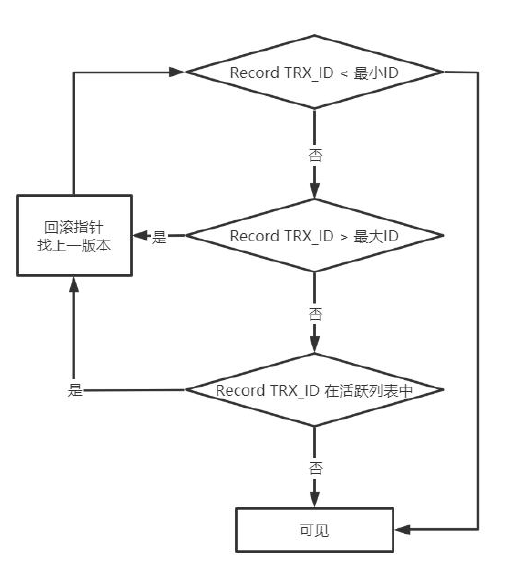
最后,READ COMMITTED和REPEATABLE READ兩種隔離級別對于快照數據生成的時機不一樣。
對于RC,在每次查詢語句執行的過程中,都關閉Read View, 再創建當前的一份Read View。這樣就會產生不可重復讀現象。
對于RR,創建事務trx結構的時候,就生成了當前的global Read View,一直維持到事務結束。在事務結束這段時間內每一次查詢都不會重新重建Read View,從而實現了可重復讀。
undo log分為兩種格式 ,處理不一樣。
insert undo log:用于回滾,提交即清理;不需要進行purge操作。
update undo log:用于回滾,同時實現快照讀,不能隨便刪除,所以需要等待purge線程來判斷何時刪除。它記錄的是對delete和update的操作產生的undo log。
注:以上來自書上的說法,網上有人把第一種說成delete undo log,包括insert和delete操作,供參考。
還需要補充一點的是,update undo log怎樣去清理, 應該是根據系統活躍的Read view中最小的活躍事務ID之前的即可清除。
(2)redo log
redo日志其實在《 MySQL的undo/redo日志和binlog日志,以及2PC 》文章中介紹比較多,也提到了XA事務的2PC。我們這里簡單介紹下普通事務的流程。
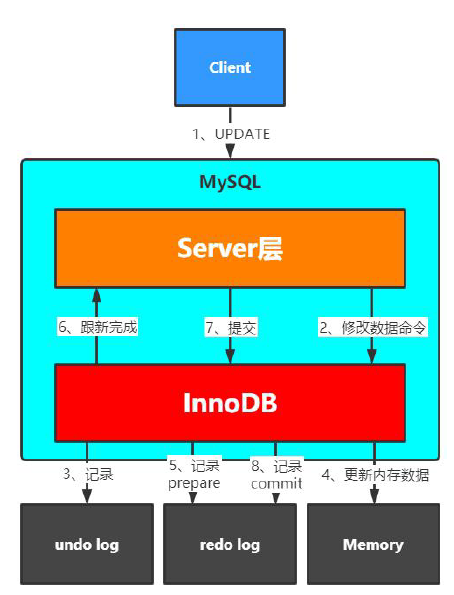
寫入流程仍然可以分為兩步,類似二階段提交:
記錄頁的修改,狀態為prepare
事務提交,講事務記錄為commit狀態
三、鎖
1、InnoDB鎖種類
(1) 類型
共享鎖(S)
讀鎖,可以同時被多個事務獲取,阻止其他事務對記錄的修改。
排他鎖(X)
寫鎖,只能被一個事務獲取,允許獲得鎖的事務修改數據。
而讀其實又可以分為 當前讀 (鎖定讀)和快照讀(非鎖定讀),而快照讀通過上一節描述的MVCC來實現。
當前讀, 讀取的是最新版本,所以需要對讀取的記錄加鎖,阻塞其他事務改動該記錄。當前讀又分為兩種方式:
select...for update,對讀取的行加X鎖;
select...lock in share mode ,對讀取的行加S鎖。
(2)鎖粒度
行級鎖
Record Lock,單個記錄上的鎖。
鎖直接加在索引記錄上面,鎖住的是key,所以必須是 聚簇索引或者二級索引是唯一索引。
間隙鎖
Gap Lock,間隙鎖,鎖定一個范圍,單不包含記錄本身。
InnoDB存儲引擎的隔離級別默認是Repeatable Read,所以引入了間隙鎖 解決 可重復讀模式下的 幻讀問題 。
GAP鎖不是加在記錄上, 鎖住的位置是兩條記錄之間的GAP; 保證 兩次當前讀 返回一致的記錄。
所以兩次當前讀之前,其他的事務 不會插入新的 滿足條件的記錄。
我們來整理下著兩者的關系和區別。
Record Lock針對的是索引必須具備唯一性;而GAP鎖針對的是索引不具備唯一性但需要保證可重復讀,也就是說如果發現數據有被其他事務修改的可能,那就把前后間隙都加上鎖。
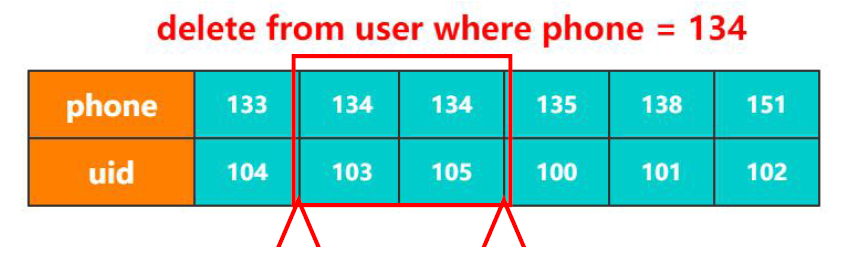
比如說如下圖,有個用戶表,uid為主鍵,那么就只需要103這條記錄加上行鎖即可。

但是如果我們變化下查詢條件(phone列上建立了二級索引),則除了對于這兩條記錄加鎖外,對前后的間隙也需要加鎖。當然這種情況是針對RR的隔離級別,如果隔離級別是RC或者更低,安全性就沒有這么高,系統會自動降級到行鎖。
Next-Key Lock,是Record Lock與Gap Lock的一個結合。理解了上述兩種鎖的原理,對于它而言就很容易了。
表級鎖
Table Lock,鎖定整張表。
主要用在運維的時候,對表格進行操作比如MDL或者元數據的操作 (meta data lock)等等。
當然有些情況下會觸發鎖升級: 全表掃描。全表掃描的觸發一般情況下是當前被查詢的字段沒有建立任何索引。
而表級鎖事實上是對所有記錄和所有的間隙都加上鎖。
所以全表掃描的效率非常低,要盡量避免。
2、InnoDB加鎖過程
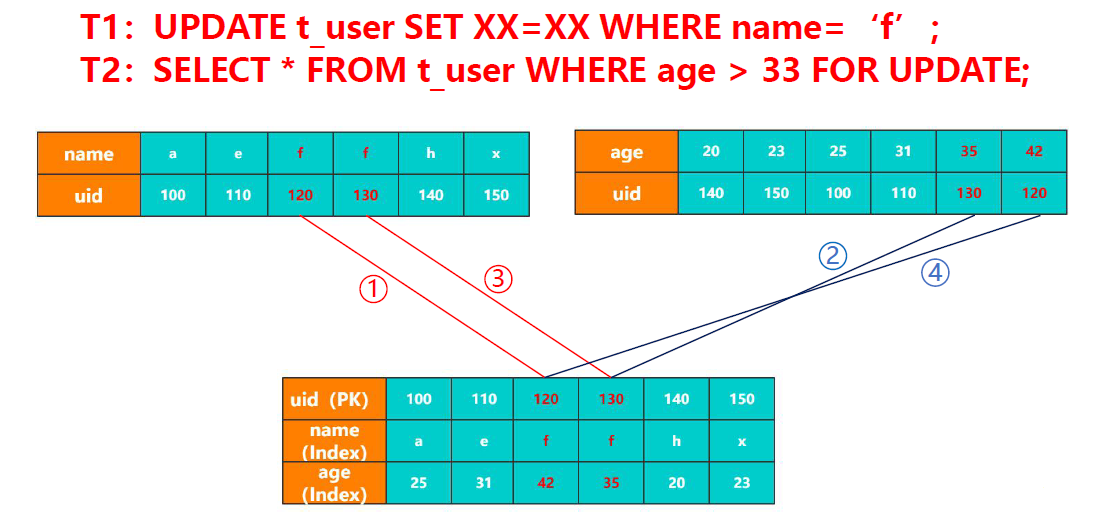
如下圖,當我們更新多條數據時,是一行一行的加鎖。
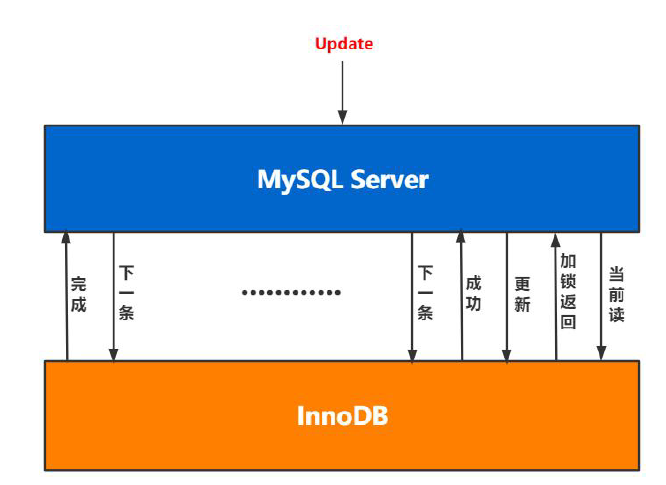
所以當同時出現對多條記錄交叉查詢時,很容易出現AB-BA死鎖,如下圖操作。
附錄
分庫分表的建議:
是否分表
建議單表不超過1KW
分表方式
取模:存儲均勻&訪問均勻
按時間:冷熱庫
分庫
按業務垂直分
水平查分多個庫
參考:
《MySQL技術內幕InnoDB存儲引擎》
內部培訓資料










)








