
上一篇文章介紹了如何構建Space L實體網絡的模型,這一篇是對上一篇文章的一個補充優化。
以下部分摘自上一篇文章:
邢八寶:如何建立復雜網絡實體網絡的Space L模型??zhuanlan.zhihu.com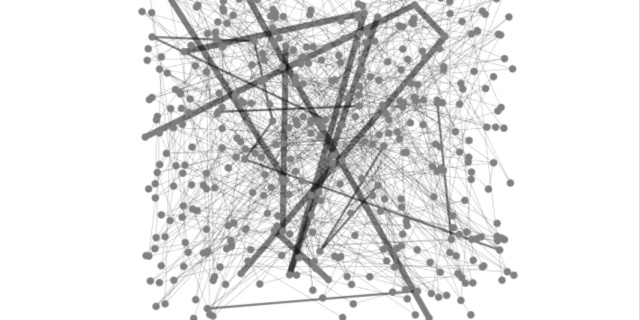
地鐵網絡,一般都有三四百個節點,線路十幾條左右,看地鐵圖的是一個眼花繚亂。若是人工統計出來數據也是一項大工程。看著就想放棄,但其實掌握一定的方法并沒有那么的費勁。
按線路進行節點的統計,先編號,然后去除掉重合的節點
統計連接關系時有一定的規則:比如從左往右統計、從上往下統計,這樣可以避免重復統計
不要直接列出鄰接矩陣,先統計出連接關系生成鄰接表,然后再轉成鄰接矩陣
關于鄰接表,最好再檢查一遍
以上工作最好分成數天進行,否則負荷工作效率低且出錯率較高
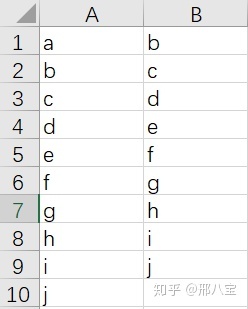
可以看到,建模時候最頭疼的就是數據的處理問題,運用以上的經驗可以提升我們的效率,但是治標不治本,依舊會浪費掉我們大量的時間。其實,如果不考慮換乘站(重復節點),連接關系還是比較好統計的,比如一條線路有10個站點,按順序分別為a、b、c….j,那么連接關系可以表示為下圖的1-9列:
最近有一個需求,要統計某市的公交網絡,有300多條線路,大概有3000多節點。如果此時還按之前的辦法:人工統計線路中的站點,然后進行編號的話,那整個工程量不僅巨大,并且在統計過程中也很容易出錯。
所以可以讓程序幫助我們去識別站點名稱,然后依次給它們編號,這樣就可以生成直接使用鄰接表。
具體處理方式,可以大概分為以下幾個步驟:
% 1.從xls文件中,讀取數據(或者直接新建數據)% rawDataNum是讀取到的數值,可以是權重,數據類型:double% rawDataStr是讀取到的字符串,是鄰接表,數據類型:cell?% 2.用b接收rawDataStr中的所有不重復的字符串,數據類型 cell?% 3.因為cell類型矩陣中存儲的是字符串數據,不好處理% 所以需要把b和rawDataStr轉換為string數組b_str和raw_str% 注意這里可以檢查一下b_str中的字符串?%4.進行數據處理test = [];?for i = 1:length(b_str)for j = 1:length(raw_str)%判斷條件if(raw_str(j,1) == b_str(i,1))test(j,1) = i;end?%判斷條件if(raw_str(j,2) == b_str(i,1))test(j,2) = i;end?endend%這時就可以得到鄰接表test?%判斷是否為無權網絡,判斷標準rawDataNum是否為空,這與你的初始數據有關if(length(rawDataNum) ~= 0)test = [test rawDataNum];elsedisp('無權網絡') end?%這一步就是把鄰接表test直接轉換為鄰接矩陣A,%可以參照:如何建立復雜網絡實體網絡的Space L模型中的函數A = ainc2adj( test );% 判斷是否有孤立節點if(length(find(~sum(A))))disp('存在孤立節點') end測試鄰接表:
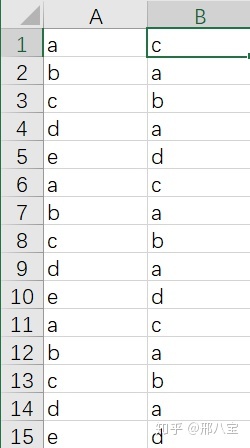
結果:
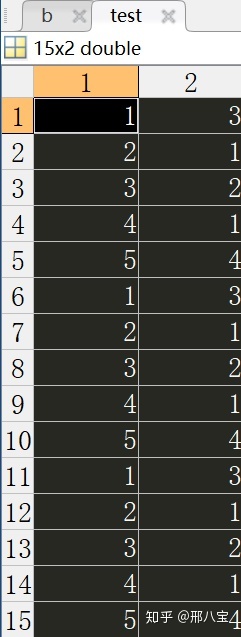
節點編號與名稱對應關系:
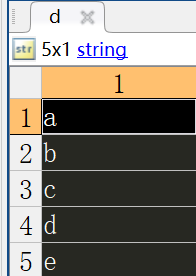
可以看到效果還是不錯的,而且不僅限于交通網絡。對于一些較大型的實體網絡,比如作者合作網絡、社交網絡,應該也會有不錯的效果。歡迎大家與我進行交流。
給大家推薦一個非常好的科研網站,可以使用免費Web of Science、zhi網、IEEE、EI等賬號。親測好用。這個網站擁有眾多的數據庫,法律的、醫學的、工科的,等等。【親測好用!】2020中國知網免費入口_知網免費賬號_Web of Science免費入口 - 80圖書館
該文章首發于:
XuXing’s blog?xuxing0430.github.io復雜網絡相關內容可以訪問:
復雜網絡?xuxing0430.github.io


















