
引言
模型優化是機器學習算法實現中最困難的挑戰之一。機器學習和深度學習理論的所有分支都致力于模型的優化。
機器學習中的超參數優化旨在尋找使得機器學習算法在驗證數據集上表現性能最佳的超參數。超參數與一般模型參數不同,超參數是在訓練前提前設置的。舉例來說,隨機森林算法中樹的數量就是一個超參數,而神經網絡中的權值則不是超參數。
其它超參數有:
- 神經網絡訓練中的學習率
- 支持向量機中的 參數和 參數
- k 近鄰算法中的 參數
……
超參數優化找到一組超參數,這些超參數返回一個優化模型,該模型減少了預定義的損失函數,進而提高了給定獨立數據的預測或者分類精度。
分類算法中的超參數
超參數優化方法
超參數的設置對于模型性能有著直接影響,其重要性不言而喻。為了最大化模型性能,了解如何優化超參數至關重要。接下來介紹了幾種常用的超參數優化方法。
1.手動調參
很多情況下,工程師們依靠試錯法手動對超參數進行調參優化,有經驗的工程師能夠很大程度上判斷超參數如何進行設置能夠獲得更高的模型準確性。但是,這一方法依賴大量的經驗,并且比較耗時,因此發展出了許多自動化超參數優化方法。
2. 網格化尋優(Grid Search)
網格化尋優可以說是最基本的超參數優化方法。使用這種技術,我們只需為所有超參數的可能構建獨立的模型,評估每個模型的性能,并選擇產生最佳結果的模型和超參數。
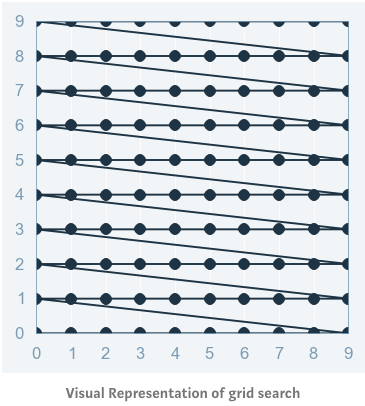
網格化尋優方法
以一個典型的核函數為 RBF 的 SVM 分類模型為例,其至少有兩個超參數需要優化——正則化常數 和 核函數參數 。這兩個超參數都是連續的,需要執行網格化尋優為每個超參數選擇合理取值。假設 。那么網格化尋優方法將對每一對( ,)賦值后的 SVM 模型進行訓練,并在驗證集上分別評估它們的性能(或者在訓練集內進行 cross-validation)。最終,網格化尋優方法返回在評估過程中得分最高的模型及其超參數。
通過以下代碼,可以實現上述方法:
首先,通過 sklearn 庫調用 GridSearchCV 。
from sklearn.datasets import load_iris
from sklearn.svm import SVC
iris = load_iris()
svc = SVR()
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVR
grid = GridSearchCV(estimator=SVR(kernel='rbf'),param_grid={'C': [0.1, 1, 100, 1000],'epsilon': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1, 5, 10],'gamma': [0.0001, 0.001, 0.005, 0.1, 1, 3, 5]},cv=5, scoring='neg_mean_squared_error', verbose=0, n_jobs=-1)然后擬合網格。
grid.fit(X,y)輸出結果。
#print the best score throughout the grid search
print grid.best_score_
#print the best parameter used for the highest score of the model.
print grid.best_param_網格化尋優的一個缺點是,當涉及到多個超參數時,計算數量呈指數增長。并且這一方法并不能保證搜索會找到完美的超參數值。
隨機尋優(Random Search)
通常并不是所有的超參數都有同樣的重要性,某些超參數可能作用更顯著。 而隨機尋優方法相對于網格化尋優方法能夠更準確地確定某些重要的超參數的最佳值。
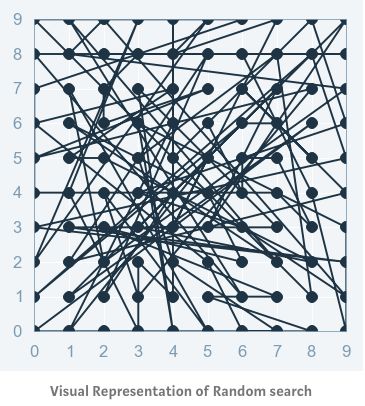
<br>隨機尋優方法
隨機尋優方法在超參數網格的基礎上選擇隨機的組合來進行模型訓練。 可以控制組合的數量,基于時間和計算資源的情況,選擇合理的計算次數。 這一方法可以通過調用 sklearn 庫中的 randomizedSearchCV 函數來實現。
盡管 RandomizedSearchCV 的結果可能不如GridSearchCV準確,但它令人意外地經常選擇出最好的結果,而且只花費GridSearchCV所需時間的一小部分。給定相同的資源,RandomizedSearchCV甚至可以優于的結果可能不如GridSearchCV準確。當使用連續參數時,兩者的差別如下圖所示。
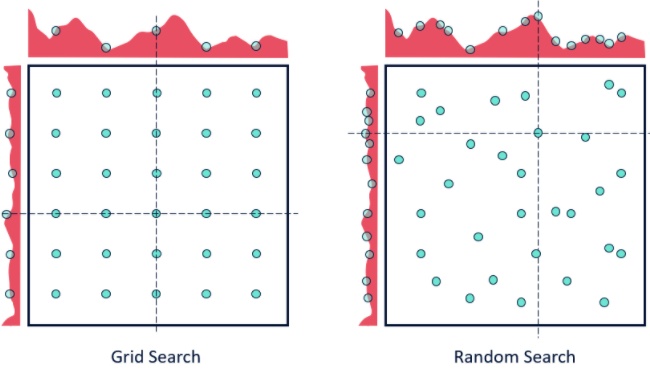
網格化尋優 VS 隨機尋優
隨機尋優方法找到最優參數的機會相對更高,但是這一方法適用于低維數據的情況,可以在較少迭代次數的情況下找到正確的參數集合,并且花費的時間較少。
通過以下代碼,可以實現上述方法:
首先,通過 sklearn 庫調用 RandomizedSearchCV 。
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestRegressor
iris = load_iris()
rf = RandomForestRegressor(random_state = 42)
from sklearn.model_selection import RandomizedSearchCV
random_grid = {'n_estimators': n_estimators,'max_features': max_features,'max_depth': max_depth,'min_samples_split': min_samples_split,'min_samples_leaf': min_samples_leaf,'bootstrap': bootstrap}
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 3, verbose=2, random_state=42, n_jobs = -1)# Fit the random search model然后進行計算。
rf_random.fit(X,y)輸出結果。
#print the best score throughout the grid search
print rf_random.best_score_
#print the best parameter used for the highest score of the model.
print rf_random.best_param_Output:
{'bootstrap': True,'max_depth': 70,'max_features': 'auto','min_samples_leaf': 4,'min_samples_split': 10,'n_estimators': 400}貝葉斯優化方法(Bayesian Optimization)
前面兩種方法能夠針對單獨超參數組合模型進行訓練,并評估各自的性能。每個模型都是獨立的,因此很易于進行并行計算。但是每個模型都是獨立的,也導致模型之間不具有指導意義,前一模型的計算結果并不能影響后一模型的超參數選擇。 而貝葉斯優化方法(順序優化方法的一種,sequential model-besed optimization, SMBO)則可以借鑒已有的結果進而影響后續的模型超參數選擇。
這也限制了模型訓練評估的計算次數,因為只有有望提高模型性能的超參數組合才會被進行計算。
貝葉斯優化是通過構造一個函數的后驗分布(高斯過程)來工作的,該后驗分布最好地描述了要優化的函數。隨著觀測次數的增加,后驗分布得到改善,算法更加確定參數空間中哪些區域值得探索,哪些區域不值得探索。
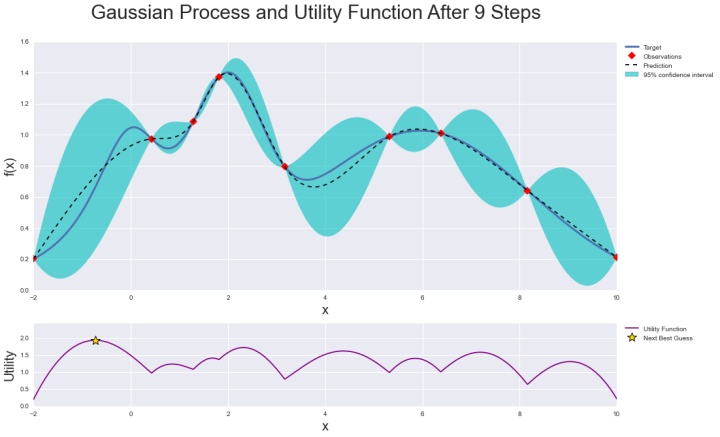
當反復迭代時,算法會在考慮到它對目標函數的了解的情況下,平衡它的探索和開發需求。在每個步驟中,高斯過程被擬合到已知的樣本(先前探索的點),后驗分布與探索策略(例如UCB(上置信限,upper confidence bound)或EI(預期改善, expected improvement))被用于確定下一個應該探索的點。
通過貝葉斯優化方法,可以更高效得探索超參數變量空間,降低優化時間。
基于梯度的優化方法(Gradient-based Optimization)
基于梯度的優化方法經常被用于神經網絡模型中,主要計算超參數的梯度,并且通過梯度下降算法進行優化。
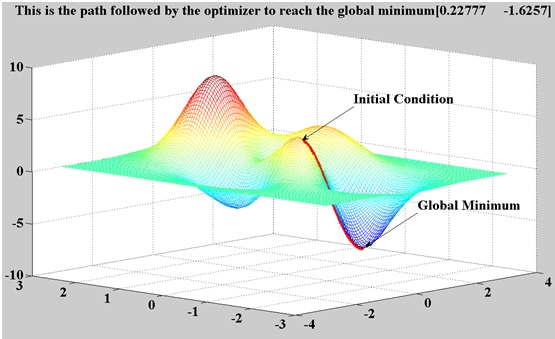
這一方法的應用場景并不廣泛,其局限性主要在于:
- 超參數優化通常不是一個平滑的過程
- 超參數優化往往具有非凸的性質
進化尋優(Evolutionary Optimization)
進化尋優方法的思想來源于生物學概念,由于自然進化是不斷變化的環境中發生的一個動態過程,因此適用于超參數尋優問題,因為超參數尋優也是一個動態過程。
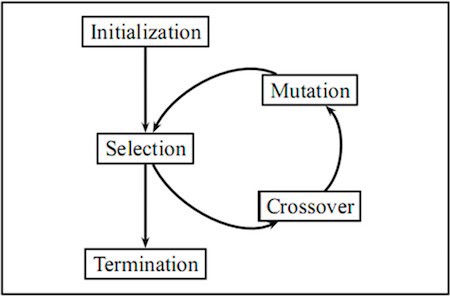
進化算法經常被用來尋找其他技術不易求解的近似解。優化問題往往沒有一個精確的解決方案,因為它可能太耗時并且計算資源占用很大。在這種情況下,進化算法通常可以用來尋找一個足夠的近似最優解。 進化算法的一個優點是,它們可以產生出不受人類誤解或偏見影響的解決方案。
作為一個一般性的經驗法則,任何時候想要優化調整超參數,優先考慮網格化尋優方法和隨機尋優方法!
總結
在本文中,我們了解到為超參數找到正確的值可能是一項令人沮喪的任務,并可能導致機器學習模型的欠擬合或過擬合。我們看到了如何通過使用網格化尋優、隨機尋優和其他算法來克服這一障礙。
作者:Nagesh Singh Chauhan
deephub翻譯組:Oliver Lee
關注公眾號 "deep-imba" 獲取更多人工智能干貨

![java游戲猿人時代_猿人時代增值版_JAVA游戲免費版下載_7723手機游戲[www.7723.cn]](http://pic.xiahunao.cn/java游戲猿人時代_猿人時代增值版_JAVA游戲免費版下載_7723手機游戲[www.7723.cn])










)






...)