轉自:https://blog.csdn.net/a745233700/article/details/80203340java
java調用tess4j識別圖像文字
Tesseract-OCR支持中文識別,而且開源和提供全套的訓練工具,是快速低成本開發的首選。前面記錄過在java中調用tesseract-orc,該方法的原理是經過在java中調用cmd命令行,來執行tesseract,可是該方式須要下載軟件,在電腦上安裝環境,移植性不高。git
而Tess4J則是Tesseract在Java PC上的應用。若是使用Tess4J只須要下載相關Jar包,導入項目,再把項目封裝好就能夠到處運行了,可移植性比較好。Tess4J在英文和數字識別中性能比較好,可是在中文識別中,不管速度仍是識別率仍是較弱,所以須要針對場景進行訓練,才能得到較好結果。github
這篇博客簡單記錄一下在java中經過調用tess4j的方式識別圖片的文字內容。maven
步驟:工具
(1)下載tess4j源碼包:https://sourceforge.net/projects/tess4j/性能
tessdata下默認為英語庫,中文庫下載地址:https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata測試
其余庫的下載地址:https://github.com/tesseract-ocr/tessdataui
下載完的tess4j資源包目錄以下:.net

(2)新建一個java工程:命令行
使用Build Path -> configure build path導入dist目錄下的tess4j.jar 和 lib目錄下的全部jar包,以下圖:
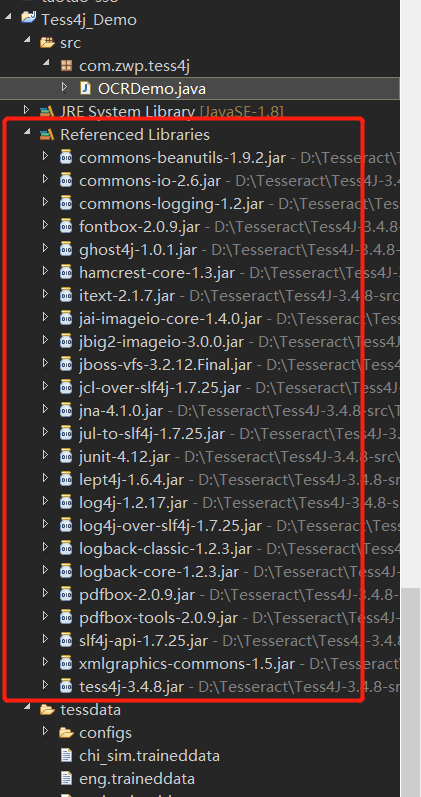
若是是maven工程則導入如下maven依賴。
net.sourceforge.tess4j
tess4j
3.2.1
(3)把tessdata文件夾復制到項目的根目錄下(與src目錄同級),以下圖:

若是tessdata目錄沒有配置到根目錄下,就須要在代碼中指定datePath。
(4)編寫測試類:
import java.io.File;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
/**
* 類說明 : tess4j測試類
*/
public class OCRDemo {
public static void main(String[] args) throws TesseractException {
ITesseract instance = new Tesseract();
//若是未將tessdata放在根目錄下須要指定絕對路徑
//instance.setDatapath("the absolute path of tessdata");
//若是須要識別英文以外的語種,須要指定識別語種,而且須要將對應的語言包放進項目中
instance.setLanguage("chi_sim");
// 指定識別圖片
File imgDir = new File("C://Users//1_20180208150251_x4hzz//1.png");
long startTime = System.currentTimeMillis();
String ocrResult = instance.doOCR(imgDir);
// 輸出識別結果
System.out.println("OCR Result: \n" + ocrResult + "\n 耗時:" + (System.currentTimeMillis() - startTime) + "ms");
}
}
(5)圖片素材與識別結果:

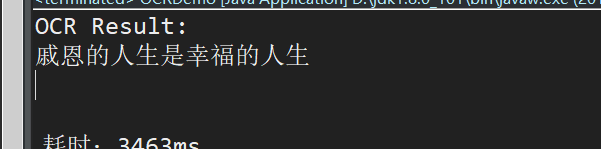
能夠看到,tess4j在中文識別時,不管速度仍是識別率仍是較弱,須要針對場景進行訓練,才能得到較好結果。
---------------------
做者:a745233700
來源:CSDN
原文:https://blog.csdn.net/a745233700/article/details/80203340
版權聲明:本文為博主原創文章,轉載請附上博文連接!
)





--啟蒙篇《MYSQL必知必會》)

)



函數詳解)




)
![圖書管理系統 java 源碼_[源碼和文檔分享]基于C語言和SQL SERVER數據庫實現的圖書管理系統...](http://pic.xiahunao.cn/圖書管理系統 java 源碼_[源碼和文檔分享]基于C語言和SQL SERVER數據庫實現的圖書管理系統...)
)