一、行式數據庫和列式數據庫的對比
1、存儲比較
行式數據庫存儲在hdfs上式按行進行存儲的,一個block存儲一或多行數據。而列式數據庫在hdfs上則是按照列進行存儲,一個block可能有一列或多列數據。
2、壓縮比較
對于行式數據庫,必然按行壓縮,當一行中有多個字段,各個字段對應的數據類型可能不一致,壓縮性能壓縮比就比較差。
對于列式數據庫,必然按列壓縮,每一列對應的是相同數據類型的數據,故列式數據庫的壓縮性能要強于行式數據庫。
3、查詢比較
假設執行的查詢操作是:select id,name from table_emp;
對于行式數據庫,它要遍歷一整張表將每一行中的id,name字段拼接再展現出來,這樣需要查詢的數據量就比較大,效率低。
對于列式數據庫,它只需找到對應的id,name字段的列展現出來即可,需要查詢的數據量小,效率高。
假設執行的查詢操作是:select * from table_emp;
對于這種查詢整個表全部信息的操作,由于列式數據庫需要將分散的行進行重新組合,行式數據庫效率就高于列式數據庫。
但是,在大數據領域,進行全表查詢的場景少之又少,進而我們使用較多的還是列式數據庫及列式儲存。
二、stored as file_format 詳解
1、建一張表時,可以使用“stored as file_format”來指定該表數據的存儲格式,hive中,表的默認存儲格式為TextFile。

2、TEXTFILE、SEQUENCEFILE、RCFILE、ORC等四種儲存格式及它們對于hive在存儲數據和查詢數據時性能的優劣比較
TEXTFILE: 只是hive中表數據默認的存儲格式,它將所有類型的數據都存儲為String類型,不便于數據的解析,但它卻比較通用。不具備隨機讀寫的能力。支持壓縮。
SEQUENCEFILE: 這種儲存格式比TEXTFILE格式多了頭部、標識、信息長度等信息,這些信息使得其具備隨機讀寫的能力。支持壓縮,但壓縮的是value。(存儲相同的數據,SEQUENCEFILE比TEXTFILE略大)
RCFILE(Record Columnar File): 現在水平上劃分為很多個Row Group,每個Row Group默認大小4MB,Row Group內部再按列存儲信息。由facebook開源,比標準行式存儲節約10%的空間。
ORC: 優化過后的RCFile,現在水平上劃分為多個Stripes,再在Stripe中按列存儲。每個Stripe由一個Index Data、一個Row Data、一個Stripe Footer組成。每個Stripes的大小為250MB,每個Index Data記錄的是整型數據最大值最小值、字符串數據前后綴信息,每個列的位置等等諸如此類的信息。這就使得查詢十分得高效,默認每一萬行數據建立一個Index Data。ORC存儲大小為TEXTFILE的40%左右,使用壓縮則可以進一步將這個數字降到10%~20%。
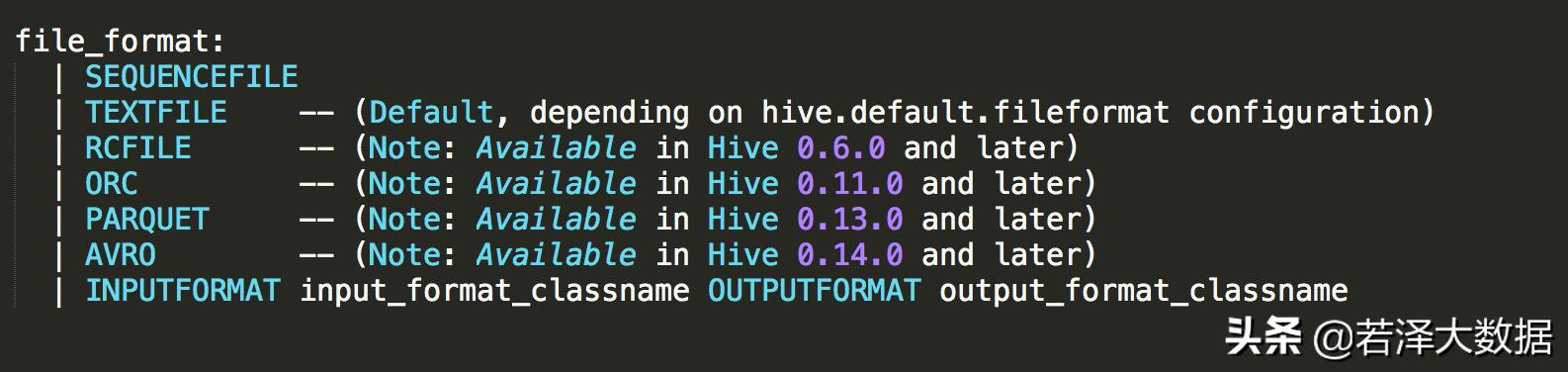
ORC這種文件格式可以作用于表或者表的分區,可以通過以下幾種方式進行指定:

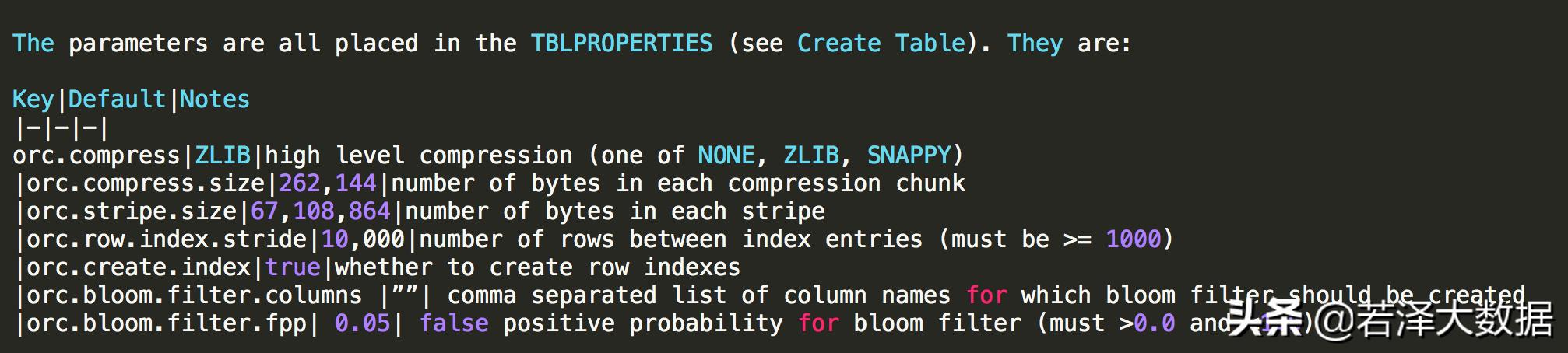
示例:創建帶壓縮的ORC存儲表

PARQUET: 存儲大小為TEXTFILE的60%~70%,壓縮后在20%~30%之間。
注意:
- 不同的存儲格式不僅表現在存儲空間上的不同,對于數據的查詢,效率也不一樣。因為對于不同的存儲格式,執行相同的查詢操作,他們訪問的數據量大小是不一樣的。
- 如果要使用TEXTFILE作為hive表數據的存儲格式,則必須先存在一張相同數據的存儲格式為TEXTFILE的表table_t0,然后在建表時使用"insert into table table_stored_file_ORC select from table_t0;"創建。或者使用"create table as select from table_t0;"創建。











)







)