HTTP
為什么會出現 HTTP 協議,從 HTTP1.0 到 HTTP3 經歷了什么?HTTPS 又是怎么回事?
HTTP 是一種用于獲取類似于 HTML 這樣的資源的 應用層通信協議, 他是萬維網的基礎,是一種 CS 架構的協議,通常來說,HTTP 協議一般由瀏覽器等 “客戶端” 發起,發起的這個請求被稱為 Request, 服務端接受到客戶端的請求后,會返回給客戶端所請求的資源,這一過程被稱為 Response,在大部分情況下,客戶端和服務器之間還可能存在許多 proxies,他們的作用可能各不相同,有些可能作為網關存在,有些可能作為緩存存在。

HTTP 協議有三個基本的特性:
- 簡單:HTTP 的協議和報文是簡單,易于理解和閱讀的(HTTP/2 已經改用二進制傳輸數據,但 HTTP 整體還是簡單的)
- 可拓展的:請求和響應都包括 “Header” 和 “Body” 兩部分,我們可以通過添加頭部字段輕松的拓展 HTTP 的功能
- 無狀態的:服務端不保存客戶端狀態,也就是說每一次請求的服務端來說都是唯一無差別的,我們只能通過 Cookie 等技術創建有狀態的會話。
HTTP 的歷史
HTTP 的歷史可以追溯到萬維網剛被發明的時候,1989年, Tim Berners-Lee 博士寫了一份關于建立一個通過網絡傳輸超文本系統的報告。該系統起初被命名為 Mesh,在隨后的1990年項目實施期間被更名為萬維網(*World Wide Web)。他以現有的 TCP IP 協議為基礎建造, 由四個部分組成:
- 用來表示超文本文檔的文本格式,即超文本標記語言(HTML)
- 一個用來傳輸超文本的簡單應用層協議,即超文本傳輸協議(HTTP)
- 一個用來顯示或編輯超文本文檔的客戶端,即網絡瀏覽器,而第一個瀏覽器則被稱為 WorldWideWeb
- 一個用于提供可訪問文檔的服務,httpd 的前身.
這四部分在 1990 年底完成,這時候的 HTTP 協議還很簡單,后來為了于其他版本的協議區分,最初的 HTTP 協議被記為 HTTP/0.9,
后來,隨著計算機技術的發展,HTTP 協議也隨著 HTTP/1.0, HTTP/1.1, HTTP/2 等關鍵版本更迭變得更加高效實用。
HTTP/0.9 on-line
最初的 0.9 版本也被稱為單行協議(on-line), 基于 TCP 協議,該版本下只有一個可用的請求方法:GET, 請求格式也相當簡單:
GET /index.html
它表示客戶端請求 index.html 的內容,0.9 版本的 HTTP 響應也同樣簡單,他只允許響應 HTML 格式的字符串,如:
<html><h1> ..... </h1>
</html>
這一階段的響應甚至沒有響應頭,也沒有響應碼或錯誤代碼,一旦出現問題,服務端會響應一段特殊的 HTML 字符串以便客戶端查看。 服務端在發送完數據后,就會立刻關閉 TCP 連接。
HTTP/1.0
0.9 版本的 HTTP 協議太過于簡單甚至是簡陋,而隨著瀏覽器和服務器的應用被擴展到越來越多的領域,0.9 版本的協議已經不能適應,直到 1996年11月,RFC 1945 定義了 HTTP/1.0, 但他并不是官方標準,該版本的 HTTP 協議較 0.9 版本有了一下改變:
-
版本號被添加到了請求頭上,像下面這樣:
GET /mypage.html HTTP/1.0 -
引入了 HTTP頭的概念,無論是請求還是響應,允許傳輸元數據,這使得協議更加靈活和具有拓展性。
-
請求方法拓展到了 GET,HEAD,POST
-
在新 HTTP 頭(
Content-Type)的幫助下,可以傳輸不止 HTML 的任意格式的數據。 -
響應時帶上了狀態碼,使得瀏覽器能夠知道響應的狀態并作出響應的處理。
-
…
HTTP/1.1
同 0.9 版本一樣,1.0 版本下,TCP 連接是不能復用的,數據發送完后服務端會立刻關閉連接,但由于建立 TCP 連接的代價較大,所以 1.0 版本的 HTTP 協議并不是足夠高效,加上 HTTP/1.0 多種不同的實現方式在實際運用中顯得有些混亂,自1995年就開始了 HTTP 的第一個標準化版本的修訂工作,到1997年初,HTTP1.1 標準發布。
1.1 版本的改進包括:
-
支持長連接:在 HTTP1.1 中默認開啟 Connection: keep-alive,允許在一個 TCP 連接上傳輸多個 HTTP 請求和響應,減少了建立和關閉連接造成的性能消耗。
-
支持
pipline: HTTP/1.1 還支持流水線(pipline)工作,流水線是指在同一條長連接上發出連續的請求,而不用等待應答返回。這樣可以避免連接延遲。 -
支持響應分塊:對于比較大的響應,HTTP/1.2 通過
Transfer-Encoding首部支持將其分割成多個任意大小的分塊,每個數據塊在發送時都會附上塊的長 度,最后用一個零長度的塊作為消息結束的標志。 -
新的緩存控制機制:HTTP/1.1定義的
Cache-Control頭用來區分對緩存機制的支持情況,同時,還提供If-None-Match,ETag,Last-Modified,If-Modified-Since等實現緩存的驗證等工作。 -
允許不同域名配置到同一IP的服務器上:在 HTTP/1.0 時,認為每臺服務器綁定一個唯一的 IP,但隨著技術的進步,一臺服務器的多個虛擬主機會共享一個IP,為了區分同一服務器上的不同服務,HTTP/1.1 在請求頭中加入了
HOST字段,它指明了請求將要發送到的服務器主機名和端口號,這是一個必須字段,請求缺少該字段服務端將會返回 400. -
引入內容協商機制,包括語言,編碼,類型等,并允許客戶端和服務器之間約定以最合適的內容進行交換。
-
使用了 100 狀態碼:HTTP/1.0 中,定義:
o 1xx: Informational - Not used, but reserved for future use在 2.0 版本時,使用了這個保留的狀態碼,用來表示臨時響應。
HTTPS
HTTP/1.1 之后,對 HTTP 協議的拓展變得更加簡單,但 HTTP 依然存在一個天然的缺陷就是明文傳輸數據,直到 1994 年底,網景公司在 TCP/IP 協議棧的基礎上添加了 SSL 層用來加密傳輸,后來,在標準化的過程中, SSL 成了 TLS (Transport Layer Security 傳輸層安全協議),基于 HTTPS 通信的客戶端和服務器在建立完 TCP 連接之后會協商通信密鑰,在之后的通信過程中, 客戶端和服務器會使用該密鑰對數據進行對稱加密,以防數據被竊取或篡改。(密鑰協商階段會使用非對稱加密)。
HTTP/2
HTTP/1.1 雖然允許連接復用和以流水線方式運作,但在一個 TCP 連接里面,所有數據依然還是按序發送的,服務器只能處理完一個請求再去處理另一個請求,如果第一個請求非常慢,就會造成后面的請求長時間阻塞,這被稱為 隊頭阻塞(Head-of-line blocking),2009 年,谷歌公開了自行研發的 SPDY 協議,它基于 HTTPS,并采用多路復用解決了隊頭阻塞的問題,同時,它還使用了 Header 壓縮等技術大大降低了延時并提高了帶寬利用率,在之后的 2015 到 2019 年間,谷歌在自家瀏覽器上實踐和證明了這個協議,SPDY 也成了 HTTP/2 的基石。
2015 年 5 月, HTTP/2 正式標準化,他與 1.x 版本 不同在于:
- 1.x 版的 HTTP 協議傳輸的是文本信息,這對開發者很友好,但卻浪費了計算機的性能,HTTP/2 改成了基于二進制而不再是基于文本的協議,
- 這是一個復用協議。并行的請求能在同一個鏈接中處理,移除了HTTP/1.x中順序和阻塞的約束。
- 壓縮了headers。因為headers在一系列請求中常常是相似的,其移除了重復和傳輸重復數據的成本。
- 其允許服務器在客戶端緩存中填充數據,通過一個叫服務器推送的機制來提前請求。
雖然 HTTP/2 2015 年就被標準化,在到目前為止,HTTP/1.1 任然被廣泛使用,據 MySSL 的最新統計,截至 2020 年 12 月,已有 65.84% 的站點支持了 HTTP/2.
HTTP/3
HTTP/3 是即將到來的第三個主要版本的 HTTP 協議,在 HTTP/3 中,將棄用 TCP 協議,改為使用基于 UDP 的 QUIC 協議實現。QUIC(快速UDP網絡連接)是一種實驗性的網絡傳輸協議,由Google開發,該協議旨在使網頁傳輸更快。
在2018年10月28日的郵件列表討論中,IETF(互聯網工程任務組) HTTP和QUIC工作組主席 Mark Nottingham 提出了將 HTTP-over-QUIC 更名為 HTTP/3 的正式請求,以“明確地將其標識為HTTP語義的另一個綁定……使人們理解它與 QUIC 的不同”,并在最終確定并發布草案后,將 QUIC 工作組繼承到 HTTP 工作組, 在隨后的幾天討論中,Mark Nottingham 的提議得到了 IETF 成員的接受,他們在2018年11月給出了官方批準,認可 HTTP-over-QUIC 成為 HTTP/3。
2019年9月,HTTP/3支持已添加到 CloudFlare 和 Chrome 上。Firefox Nightly 也將在2019年秋季之后添加支持。
HTTP/1.1 細節
HTTP報文
HTTP 的報文都由消息頭和消息體兩部分組成,兩者之間以 CRLF(回車換行) 分割。
請求頭格式
請求頭第一行為請求行,其余為請求頭字段:如下:
POST /api/article/list HTTP/1.1
Host: junebao.top:8888
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0
Accept: application/json, text/plain, */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Content-Type: application/json;charset=utf-8
Content-Length: 32
Origin: https://junebao.top
Connection: keep-alive
Referer: https://junebao.top/
Cache-Control: max-age=0
請求行由三部分組成:
- 請求方法
- 請求資源的 url
- 協議版本
他們以空格分隔,RFC2068 定義了其中不同的請求方法,他們分別為 OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE,除此之外,后來還添加了一個 PATCH 方法。
| 方法 | 基本用法 | 請求 | 響應 | 冪等性 | 緩存 | 安全性 |
|---|---|---|---|---|---|---|
| OPTIONS | 獲取目的資源所支持的通信選項, 如檢測服務器所支持的請求方法或CORS預檢請求 | 不能攜帶請求體或數據 | 可以攜帶響應體,但一般有效數據被放在頭部如 Allow 等字段 | 冪等 | 不可緩存 | 安全 |
| GET | 用于獲取某個資源 | 參數一般攜帶在 URL 后面,沒有請求體 | 有響應體 | 冪等 | 可緩存 | 安全 |
| HEAD | 用于請求資源的頭部信息,如下載前獲取大文件的大小 | 沒有請求體 | 沒有響應體,響應頭應該與使用 GET 請求時的一樣 | 冪等 | 可緩存 | 安全 |
| POST | 將數據發送給服務器 | 數據放在請求體中 | 有響應體 | 不冪等 | 可緩存(包含新鮮信息時) | 不安全 |
| PUT | 使用請求中的負載創建或替換目標資源 | 數據放在請求體中 | 有響應體 | 冪等 | 不可緩存 | 不安全 |
| DELETE | 刪除指定資源 | 可以由請求體 | 可以由響應體 | 冪等 | 不可緩存 | 不安全 |
| TRACE | 回顯服務器收到的請求,主要用于測試或診斷。 | 無請求體 | 無響應體 | 冪等 | 不可緩存 | 不安全 |
| PATCH | 作為 PUT 的補充,用于修改已知資源的部分 | 有請求體 | 無響應體 | 非冪等 | 不可緩存 | 不安全 |
請求頭字段
RFC 2068 提供了 17 種請求頭字段,但 HTTP 協議是易于拓展的,我們可以根據自己的需要添加自己的請求頭,常見的請求頭字段包括:
| 字段 | 作用 | 示例 |
|---|---|---|
| HOST | 指明了要發送到的服務器的主機號和端口號,這是一個必須字段,缺失服務器一般會返回 400, 端口號默認 80 和 443 | Host: www.baidu.com |
| ACCEPT | 告知服務器客戶端可以處理的內容類型,用MIME類型來表示。 | Accept: text/html |
| User-Agent | 用戶代理標識 | |
| Cookies | 用于維持會話 | |
| … | … | … |
響應頭格式
Response = Status-Line*( general-header| response-header| entity-header )CRLF[ message-body ]
類似于請求頭,響應頭包括狀態行和響應頭字段兩部分組成。
狀態行包括協議版本,狀態碼,狀態描述三部分組成,類似:
http/2 200 ok
目前 http 使用的狀態碼分為 5 類:
- 1xx: 信息響應類
- 2xx: 正常響應類
- 3xx: 重定向類
- 4xx: 客戶端錯誤類
- 5xx: 服務端錯誤類
常見狀態碼
| 狀態碼 | 描述 | 作用 |
|---|---|---|
| 100 | Continue | 迄今為止的所有內容都是可行的,客戶端應該繼續請求 |
| 200 | Ok | 請求成功 |
| 201 | Created | 該請求已成功,并因此創建了一個新的資源。這通常是在POST請求,或是某些PUT請求之后返回的響應。 |
| 301 | Moved Permanently | 永久重定向 |
| 302 | Found | 臨時重定向 |
| 400 | Bad Request | 請求參數錯誤或語義錯誤 |
| 401 | Unauthorized | 請求未認證 |
| 403 | Forbidden | 拒絕服務 |
| 404 | Not Found | 資源不存在 |
| 429 | Too Many Requests | 超過請求速率限制(節流) |
| 500 | Internal Server Error | 服務端未知異常 |
| 501 | Not Implemented | 此請求方法不被服務端支持 |
| 502 | Bad Gateway | 網關錯誤 |
| 503 | Service Unavailable | 服務不可用 |
| 504 | Gateway Timeout | 網關超時 |
| 505 | HTTP Version Not Supported | HTTP 版本不被支持 |
無狀態的 HTTP
HTTP 是一個無狀態的協議,為了維持會話,每客戶端請求時,都應該攜帶一個 “憑證”,證明 who am i, 目前維持會話常用的技術有:cookie, session, token, 等
cookie
RFC 6265 定義了 Cookie 的工作方式, Cookie 是服務器發送給客戶端并存儲在本地的一小段數據,在用戶第一次登錄時,服務器生成 Cookie 并在響應頭里添加 Set-Cookie 字段,客戶端收到響應后,將 Set-Cookie 字段的值(Cookie)存儲在本地,以后每次請求時,客戶端會自動通過 Cookie 字段攜帶 Cookie。
Cookie 以鍵值的形式儲存,除了必須的 Name 和 Value,還可以為 Cookie 設置以下屬性:
- Domain:指定了哪寫主機可以接收該 Cookie,默認為 Origin, 不包含子域名。
- Path:規定了請求主機下的哪些路徑時要攜帶該 Cookie。
- Expires/Max-Age: 規定該 Cookie 過期時間或最大生存時間,該時間只與客戶端有關。
- HttpOnly: JavaScript
Document.cookieAPI 無法訪問帶有 HttpOnly 屬性的cookie,用于預防 XSS 攻擊;用于持久化會話的 Cookie 一般應該設置 HttpOnly 。 - Secure:標記為 Secure 的 Cookie 只能使用 HTTPS 加密傳輸給服務器,因此可以防止中間人攻擊,但 Cookie 天生具有不安全性,任何敏感數據都不應該使用 Cookie 傳輸,哪怕標記了 secure.
- Priority:
- SameSite:要求該 Cookie 在跨站請求時不會被發送,用來阻止 CSRF 攻擊,它有三種可選的值:
- None:在同站請求和跨站請求時都會攜帶上 Cookie
- Strict:只會在訪問同站請求時帶上 Cookie
- Lex:與 Strict 類似,但用戶從外部站點導航至URL時(例如通過鏈接)除外,新版瀏覽器一般以 Lex 為默認選項。
Cookie 被完全保存在客戶端,對客戶端用戶來說是透明的,用戶可以自己創建和修改 Cookie,所以將敏感信息(如用于持久化會話的用戶身份信息等)存放在 Cookie 中是十分危險的,如果不得已需要使用 Cookie 來存儲和傳遞這類信息,應該考慮使用 JWT 等類似機制。
由于 Cookie 的不安全性,絕大部分 Web 站點已經開始停止使用 Cookie 持久化會話,但 Cookie 在一些對安全性要求不高的場景下依然被廣泛使用,如:
- 個性化設置
- 瀏覽器用戶行為跟蹤。
了解更多:
超級 Cookie 和僵尸 Cookie
決戰僵尸 Cookie
SESSION
Cookie 不安全的根源在于它將會話信息保存在了客戶端,為此,就有了使用 Session 持久化會話的方案,用戶在第一次登錄時,服務器會將用戶會話狀態信息保存在服務器內存中,同時會為這段信息生成一串唯一索引,將這個索引作為 Cookie (Name 一般為 SESSION_IDSESSION_ID)返回給客戶端,客戶端下一次請求時,會自動攜帶這個 SESSION_ID, 服務器只需要根據 SESSION_ID 的值找到對應的狀態信息就可以知道這次請求是誰發起的。
SESSION 很大程度上還是依賴于 Cookie,但這時 Cookie 中保存的已經是一段對客戶端來說無意義的字符串了,因此使用 Session 能安全的實現會話持久化,但 Session 信息被保存在服務器內存中,可能造成服務器壓力過大,并且在分布式和前后端分離的環境下,Session 并不容易拓展。
TOKEN
Cookie 和 Session 都是開箱即用的 API,因此,他們不可避免地缺少靈活性,在一般開發中,往往采用更靈活地 Token,Token 與 Session 原理一致,都是將會話信息保存到服務器,然后向客戶端返回一個該信息的索引(token),但 Token 完全由開發者實現,可以根據需要將會話信息存儲在內存,數據庫,文件等地方,而對于該信息的索引,也可以根據具體需要選擇使用請求頭,請求體或者 Cookie 傳遞,也不必拘束于只 Cookie 傳遞。
JWT
全稱 json web token, 是一種客戶端存儲會話狀態的技術,它使用數字簽名技術防止了負荷信息被篡改,jwt 包含三部分信息:
- Header:包含 token 類型和算法名稱
- Payload:存儲的負載信息(敏感信息不應該明文存放在此)
- Signature:服務端使用私鑰對 Header 和 Payload 的簽名,防止信息被篡改。
這三部分原本都是 json 字符串,最終他們會經過 Base64 編碼后拼接到一起,使用 . 分割。
分布式解決方案
在分布式場景下,同一用戶的不同次請求可能會被打到不同的服務器上,這時如果還像單機時那樣存儲,就會出問題,一般的解決方案包括:
- 粘性 session:將用戶綁定到一臺服務器上,如 Nginx 負載均衡策略使用 ip_hash, 但這樣如果當前服務器發生故障,可能導致分配到這臺服務器上的用戶登錄信息失效,容錯度低。
- session 復制:一臺服務器的 session 改變,就廣播給所有服務器,但會影響服務器性能
- session 共享:把所有服務器的 session 放在一起,如使用 redis 等分布式緩存做 session 集群。
- 客戶端記錄狀態:使用諸如 JWT 之類的方法。
連接管理
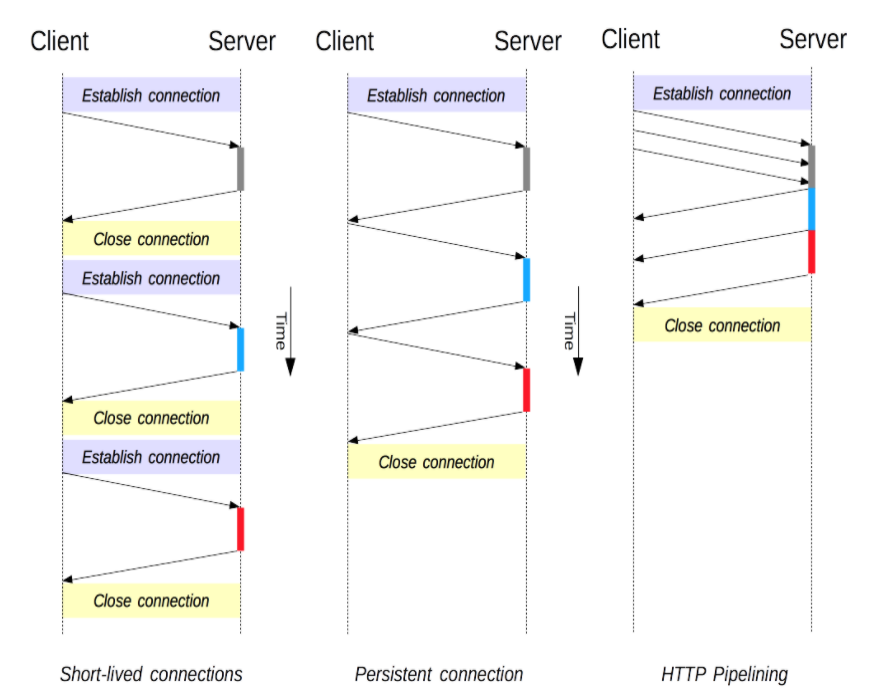
連接管理是一個 HTTP 的關鍵話題:打開和保持連接在很大程度上影響著網站和 Web 應用程序的性能。在 HTTP/1.x 里有多種模型:短連接 ,長連接和HTTP 流水線
短連接
HTTP 最早期的模型,也是 HTTP/1.x 的默認模型,是短連接。每發起一個HTTP請求都會通過三次握手建立一個TCP連接,在接受到數據之后再通過四次揮手釋放連接,因為TCP連接的建立和釋放都是一個耗時操作,加之現代網頁可能需要多次連續請求才能渲染完成,這就顯得這種簡單的模型效率低下。
TCP 協議握手本身就是耗費時間的,所以 TCP 可以保持更多的熱連接來適應負載。短連接破壞了 TCP 具備的能力,新的冷連接降低了其性能。
為此,HTTP/1.1 時新增加了兩種連接管理模式,分別是長連接和流水線,在HTTP/2 中,又基于數據流采用了新的連接管理模式。
長連接
長連接是指在客戶端接受完數據后,不立刻關閉這個 TCP 連接,這個連接還可以用來發送和接收其他 HTTP 數據,這樣一來可以減少部分連接建立和釋放的耗時,但這個連接也并不會一直保持,服務端可以設置 Keep-alive 標頭來指定一個最小的連接保持時間(單位秒)和最大請求數:
HTTP/1.1 200 OK
Connection: Keep-Alive
Keep-Alive: timeout=5, max=1000
HTTP/1.0 里默認并不使用長連接。把
Connection設置成close以外的其它參數都可以讓其保持長連接,通常會設置為retry-after。在 HTTP/1.1 里,默認就是長連接的,協議頭都不用再去聲明它(但我們還是會把它加上,萬一某個時候因為某種原因要退回到 HTTP/1.0 呢)。
長連接并不總是好的,比如,他在空閑狀態下仍會消耗服務器資源,而在網絡重負載時,還有可能遭受 DoS 攻擊。這種場景下,可以使用非長連接,即盡快關閉那些空閑的連接,也能對性能有所提升。
流水線
默認情況下,HTTP 請求是按順序發出的。下一個請求只有在當前請求收到應答過后才會被發出。由于會受到網絡延遲和帶寬的限制,在下一個請求被發送到服務器之前,可能需要等待很長時間。
流水線是在同一條長連接上發出連續的請求,而不用等待應答返回。這樣可以避免連接延遲。理論上講,性能還會因為兩個 HTTP 請求有可能被打包到一個 TCP 消息包中而得到提升,就算 HTTP 請求不斷的繼續導致 TCP 包的尺寸增加,通過設置 TCP 的 MSS(Maximum Segment Size) 選項,流水線方式仍然足夠包含一系列簡單的請求。
使用流水線的另一個需要注意的問題是錯誤重傳,因此,只有冪等的方法,如 GET,HEAD,PUT, DELETE 等方法能夠安全地使用流水線。
流水線只是針對客戶端來說的,服務器依然和非流水線方式那樣工作,這就導致如果第一個請求非常耗時,那流水線上后面的請求就會被阻塞住,這種現象被稱為Head-of-line blocking(隊頭阻塞),除此之外,復雜的網絡環境和代理服務器也可能會導致流水線不能像預期的那樣高效工作,因此,現代瀏覽器都沒有默認啟用流水線,在 HTTP/2 里,有更高效的算法代替了流水線。
三者比較
CORS
在前后端分離開發時,你也許遇到過類似這樣的報錯:
Access to XMLHttpRequest at '*' from origin '*' has been blocked by CORS policy: Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource.
這就是 CORS 的問題了,所謂 CORS (Cross-Origin Resource Sharing,跨域資源共享),它首先是一個系統,由一系列 HTTP 頭組成,這些 HTTP 頭決定了瀏覽器是否阻止前端 JavaScript 代碼獲取跨域請求的響應。
之所以需要 CORS,是由于瀏覽器的同源安全策略:
同源安全策略
同源安全策略用來限制一個源(origin)的文檔或者它加載的腳本如何能與另一個源的資源進行交互。它能幫助阻隔惡意文檔,減少可能被攻擊的媒介。
只有兩個 URL 的協議,主機,端口都相同時,他們才被認為是“同源的”,反之,如:http://www.a.com 和 https://www.a.com 則會被認為是不同源的(協議不同),在默認情況下,同源策略會阻止通過不同源的URL獲取資源,而 CORS 就是提供了一種機制,以允許不同源的資源進行共享。
原理
CORS 的原理很簡單,它通過添加一組 HTTP 頭,允許服務器聲明哪些源站通過瀏覽器有權限訪問哪些資源。另外,規范要求,對那些可能對服務器數據產生副作用的 HTTP 請求方法(非簡單請求),瀏覽器必須首先使用 OPTIONS 方法發起一個預檢請求,從而獲知服務端是否允許該跨源請求。服務器確認允許之后,才發起實際的 HTTP 請求。在預檢請求的返回中,服務器端也可以通知客戶端,是否需要攜帶身份憑證(包括 Cookies 或 HTTP 認證相關數據)。
上面說到的 “可能對服務器數據產生副作用的 HTTP 請求” 就是非簡單請求(not-so-simple request),與之對應的是簡單請求(simple request),同時滿足以下幾個條件的,屬于簡單請求。
-
請求方法是以下三種方法之一:
- HEAD
- GET
- POST
-
首部字段只包含被用戶代理自動設置的首部字段(例如 Connection ,User-Agent)和允許人為設置的字段為 Fetch 規范定義的 對 CORS 安全的首部字段集合。該集合為:
-
Accept
-
Accept-Language
-
Content-Language
-
Content-Type, 只限于三個值
application/x-www-form-urlencoded、multipart/form-data、text/plain -
DPR
-
Downlink
-
Save-Data
-
Width
-
Viewport-Width
-
-
請求中的任意
XMLHttpRequestUpload對象均沒有注冊任何事件監聽器;XMLHttpRequestUpload對象可以使用XMLHttpRequest.upload屬性訪問。 -
請求中沒有使用
ReadableStream對象。
只要有其一不滿足,就是費簡單請求,非簡單請求在正式請求之前會先使用 OPTION 方法像服務器發起一個 預檢請求,如下面這個請求:
var invocation = new XMLHttpRequest();
var url = 'http://bar.other/resources/post-here/';
var body = '<?xml version="1.0"?><person><name>Arun</name></person>';function callOtherDomain(){if(invocation){invocation.open('POST', url, true);invocation.setRequestHeader('X-PINGOTHER', 'pingpong');invocation.setRequestHeader('Content-Type', 'application/xml');invocation.onreadystatechange = handler;invocation.send(body);}
}
當前域為 foo.example.com,請求 bar.other, 屬于跨域請求,并且請求時自己添加了一個請求頭 X-PINGOTHER ,并且 Content-Type 類型為 application/xml, 所以它屬于一個非簡單請求,在實際請求之前需要使用 OPTION 方法發一個預檢請求:
OPTIONS /resources/post-here/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Origin: http://foo.example
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-TypeHTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 0
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
預檢請求頭頭中最重要的部分有下面幾個:
Host: 要請求的域Origin: 發起請求的域,Host和Origin不一樣,說明是跨域請求Access-Control-Request-Method: 正式的請求將要使用的方法Access-Control-Request-Headers: 正式請求將攜帶的自定義字段
服務器在收到這樣的預檢請求后就可以根據請求頭決定是否允許即將發送的實際請求,在服務器的響應中,最重要的字段有以下幾個:
Access-Control-Allow-Origin: 服務器允許的域,允許所有域該值設置為*Access-Control-Allow-Methods: 服務器允許的請求方法,允許所有方法設置為*Access-Control-Allow-Headers: 服務器允許的請求頭Access-Control-Max-Age: 該響應的有效時間為 86400 秒,也就是 24 小時。在有效時間內,瀏覽器無須為同一請求再次發起預檢請求。
接受到響應后,瀏覽器會自動判斷實際請求是否被允許,如果不被允許,將會報上面的錯誤。
對于簡單請求,通過請求中的 Origin 和響應中的 Access-Control-Allow-Origin 就可以實現簡單的訪問控制,如果請求的 Origin 不在許可范圍內,服務器會返回一個正常的響應,瀏覽器發現這個響應的頭信息沒有包含Access-Control-Allow-Origin字段,就知道出錯了,從而拋出一個錯誤,被XMLHttpRequest的onerror回調函數捕獲。注意,這種錯誤無法通過狀態碼識別,因為HTTP回應的狀態碼有可能是200。
HTTP 緩存
緩存是一種保存資源副本并在下次請求時直接使用該副本的技術。當 web 緩存發現請求的資源已經被存儲,它會攔截請求,返回該資源的拷貝,而不會去源服務器重新下載。這樣帶來的好處有:緩解服務器端壓力,提升性能(獲取資源的耗時更短了)。對于網站來說,緩存是達到高性能的重要組成部分。緩存需要合理配置,因為并不是所有資源都是永久不變的:重要的是對一個資源的緩存應截止到其下一次發生改變(即不能緩存過期的資源)。
緩存有很多種,以服務對象分類,緩存可以分為私有緩存和共享緩存,以行為分類,又可以把它分為強制緩存和對比緩存。
- 私有緩存:又叫瀏覽器緩存,只能用于單獨用戶。瀏覽器緩存擁有用戶通過HTTP下載的所有文檔。這些緩存為瀏覽過的文檔提供向后/向前導航,保存網頁,查看源碼等功能,可以避免再次向服務器發起多余的請求。它同樣可以提供緩存內容的離線瀏覽。
- 共享緩存:又叫代理緩存,共享緩存可以被多個用戶使用。例如,ISP 或你所在的公司可能會架設一個 web 代理來作為本地網絡基礎的一部分提供給用戶。這樣熱門的資源就會被重復使用,減少網絡擁堵與延遲。
- 強制緩存:緩存數據未失效時,都可以使用緩存。
- 對比緩存:使用數據前需要請求服務器驗證緩存是否失效。
緩存控制
緩存的原理很簡單:客戶端在從服務器獲取到數據后,可以選擇將這些數據存儲下來,下一次請求同樣的數據時,就可以不請求服務器直接返回先前存儲的數據了,正確使用緩存可以提高響應速度,降低服務器壓力;
這里的客戶端可以是瀏覽器(如私有緩存),也可以是請求鏈路上的中間代理(如共享緩存),但對服務器來說,他們都是一樣的,而服務器并沒有辦法主動向客戶端推送數據,這就導致必須有一種機制去保證緩存是“新鮮”的,HTTP 協議通過一些列的頭字段實現了緩存控制,其中最重要的字段是 Cache-Control,他有以下幾種值:
Cache-Control: no-store: 禁用緩存,緩存不會存儲任何響應數據,每次請求都從服務器獲取最新的數據。Cache-Control: no-cache: 使用緩存,但需要服務器重新驗證,此方式下,每次有請求發出時,緩存會將此請求發到服務器,服務器端會驗證請求中所描述的緩存是否過期,若未過期(返回304),則緩存才使用本地緩存副本。Cache-Control: private: 私有緩存,表示該響應是專用于某單個用戶的,中間人不能緩存此響應,該響應只能應用于瀏覽器私有緩存中。Cache-Control: public:表示該響應可以被任何中間人(比如中間代理、CDN等)緩存。若指定了"public",則一些通常不被中間人緩存的頁面(默認是private)(比如 帶有HTTP驗證信息(帳號密碼)的頁面 或 某些特定狀態碼的頁面),將會被其緩存。Cache-Control: max-age=31536000: 表示資源能被緩存的最大時間,單位秒。Cache-Control: must-revalidate: 緩存在考慮使用一個陳舊的資源時,必須先驗證它的狀態,已過期的緩存將不被使用。
強制緩存
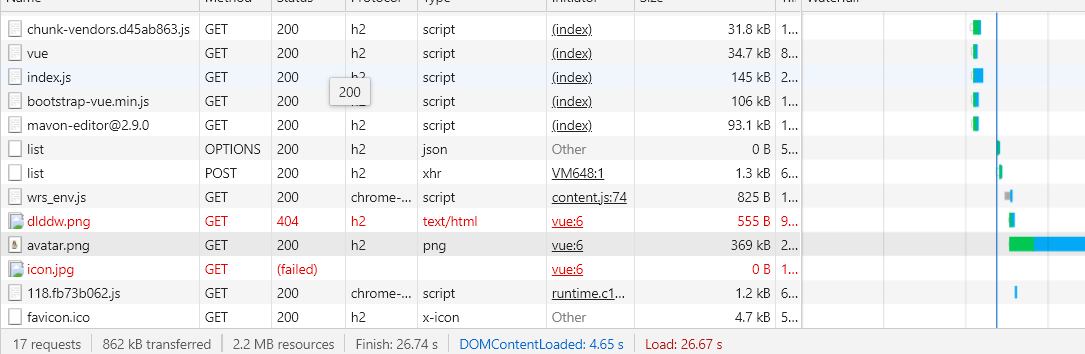
在某個資源的響應中,如果 Cache-Control:max-age=31536000, 則表明這個資源在未來一年內再次請求可以直接從緩存中拿,如第一次請求 avatar.png 時,響應里標明最大有效時間為 600s (10 分鐘),第二次再次請求該資源時,從 size 列就可以看倒該資源直接從緩存返回。
| 第一次,未使用緩存 | 第二次,使用強制緩存 |
|---|---|
 [外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-GR4bBSEk-1613829654718)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\image-20210115164159878.png)] [外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-GR4bBSEk-1613829654718)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\image-20210115164159878.png)] | 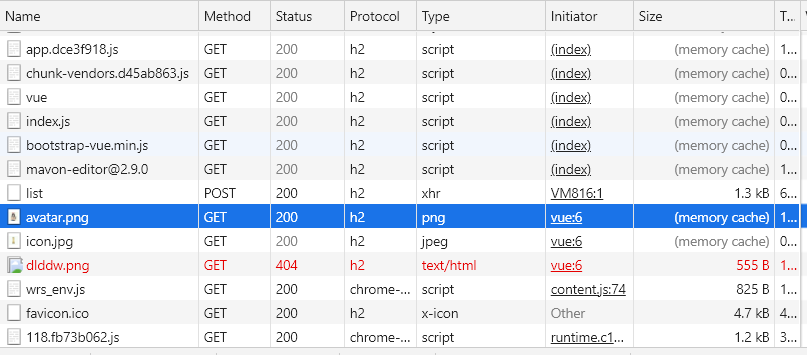 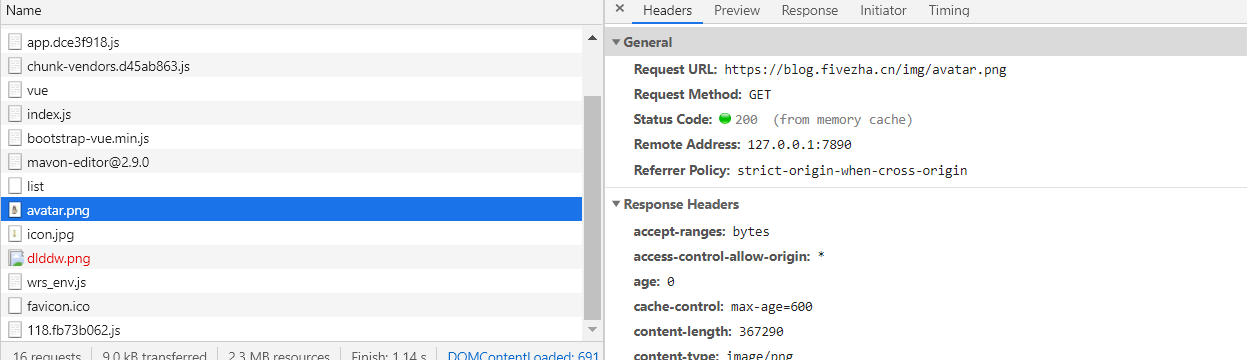 |
這里的緩存就是強制緩存,只要在10分鐘內,都可以使用緩存的資源。
如果過了10分鐘,緩存中的這個資源就可能是過期了的,這時就需要詢問服務器這個資源是不是“新鮮”的,具體客戶端會向服務器發起一個攜帶 [If-None-Match](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/If-None-Match) 頭的請求:
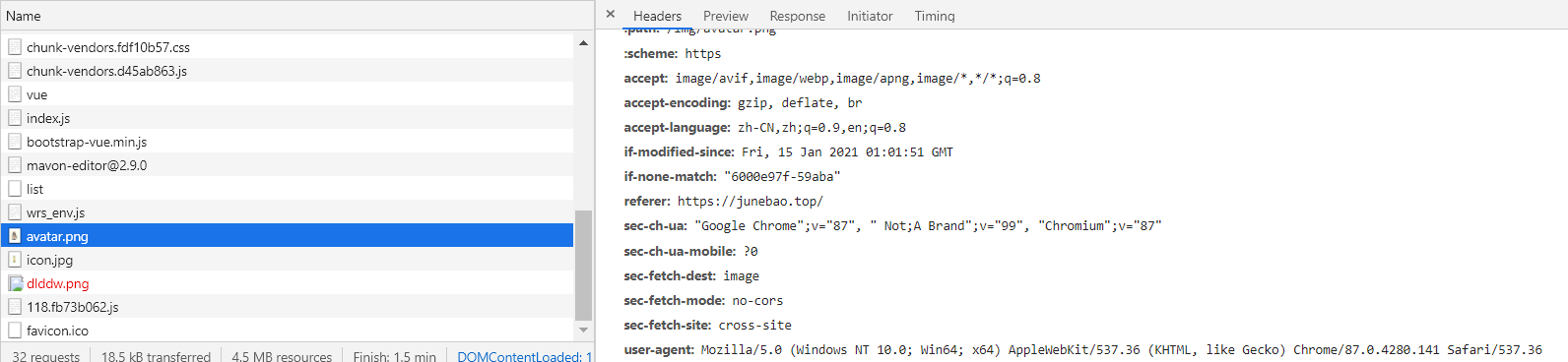
如果這個資源是“新鮮”的,服務器會返回 304 (Not Modified)(該響應不會有帶有實體信息),如果服務器發現這個資源已經過期了,則會返回新的資源。
對比緩存
與強制緩存不同,對比緩存每次使用緩存數據前都會向服務器查詢該資源是否有效,但由于查詢和響應大部分情況下都只包含頭部,所以比起不使用緩存,對比緩存也可以大大提高響應速度和降低服務器壓力。它依賴于下面幾個頭部字段:
Last-Modified: 響應頭字段,告訴客戶端這個資源最后更新的時間If-Modified-Since: 請求頭字段,如果請求頭中攜帶了這個字段,服務器會將該字段的值和資源最后修改的時間做對比,如果最后修改的時間大于字段值,說明數據已經被修改,則響應 200, 返回最新的資源,否則,響應 304 告訴客戶端資源未修改,可以使用緩存。
上面兩個頭部字段是根據修改時間判斷資源是否是新鮮的,這樣做的準確度不是很高,還有一組頭部字段 ETag 和 If-None-Match 使用資源的唯一標識來判斷資源是否被修改:
ETag: 響應頭字段,用于服務器告訴客戶端資源的唯一標識(標識的生成規則由服務端確定)If-None-Match: 請求頭字段,如果請求頭中包含此字段,服務端會對比該字段的值與最新的資源的標識,如果不相同,說明資源被修改,響應 200, 返回最新的資源,否則,響應 304.
ETag 和 If-None-Match 的優先級高于 Last-Modified 和 If-Modified-Since
除此之外,與緩存相關的還有一個請求頭:Vary, 用來決定客戶端使用新資源還是緩存資源,使用vary頭有利于內容服務的動態多樣性。例如,使用Vary: User-Agent頭,緩存服務器需要通過UA判斷是否使用緩存的頁面。如果需要區分移動端和桌面端的展示內容,利用這種方式就能避免在不同的終端展示錯誤的布局。另外,它可以幫助 Google 或者其他搜索引擎更好地發現頁面的移動版本,并且告訴搜索引擎沒有引入Cloaking。
使用緩存
說了這么多,我們應該怎么通過使用緩存來提高站點的性能呢?
首先,對于私有緩存,開發者一般是不需要關注的,瀏覽器會自動緩存請求成功的 GET 數據,用來支持后退等功能。我們一般關注的是共有緩存,也就是在代理服務器上緩存數據,客戶端請求到代理服務器上后,就可以直接返回了,下面以 Nginx 為例,簡單說明如何使用緩存。
http {# 緩存配置proxy_cache_path /usr/share/nginx/cache levels=1:2 keys_zone=server_cache:10m max_size=5g inactive=60m use_temp_path=off;# 博客后端反代server {listen 8888 ssl http2;access_log /var/log/nginx/admin/access_fd.log smail;error_log /var/log/nginx/admin/error_fd.log;location ~ /api/ {proxy_cache server_cache;proxy_cache_valid 200 304 302 1h;proxy_cache_methods GET HEAD POST;add_header X-Proxy-Cache $upstream_cache_status;proxy_pass http://39.106.168.39:8888;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}
}
如上,proxy_cache_path 用來配置緩存數據保存的路徑,里面的主要字段含義如下:
levels: 在單個目錄中包含大量文件會降低文件訪問速度,因此我們建議對大多數部署使用兩級目錄層次結構。如果未包含levelsNginx會將所有文件放在同一目錄中。keys_zone: 設置共享內存區域,用于存儲緩存鍵和元數據,后面的參數表示該區域的大小,一般來說,1 MB區域可以存儲大約8,000個 key 數據。max-size: 緩存能占的最大內存。inactive:指定項目在未被訪問的情況下可以保留在緩存中的時間長度。在此示例中,緩存管理器進程會自動從緩存中刪除1分鐘未請求的文件,無論其是否已過期。默認值為10分鐘(10m)。非活動內容與過期內容不同。Nginx 不會自動刪除緩存header定義為已過期內容(例如Cache-Control:max-age=120)。過期(陳舊)內容僅在指定時間內未被訪問時被刪除。訪問過期內容時,Nginx 會從原始服務器刷新它并重置inactive計時器。
其次,我們在 Location 塊中配置了幾個值:
proxy_cache:定義用于緩存的共享內存區域。proxy_cache_valid: 指定哪些狀態的響應可以被緩存。proxy_cache_methods: 哪些方法的請求可以被緩存。
除此之外,我們添加了一個響應頭部字段 X-Proxy-Cache 用來查看緩存是否生效。
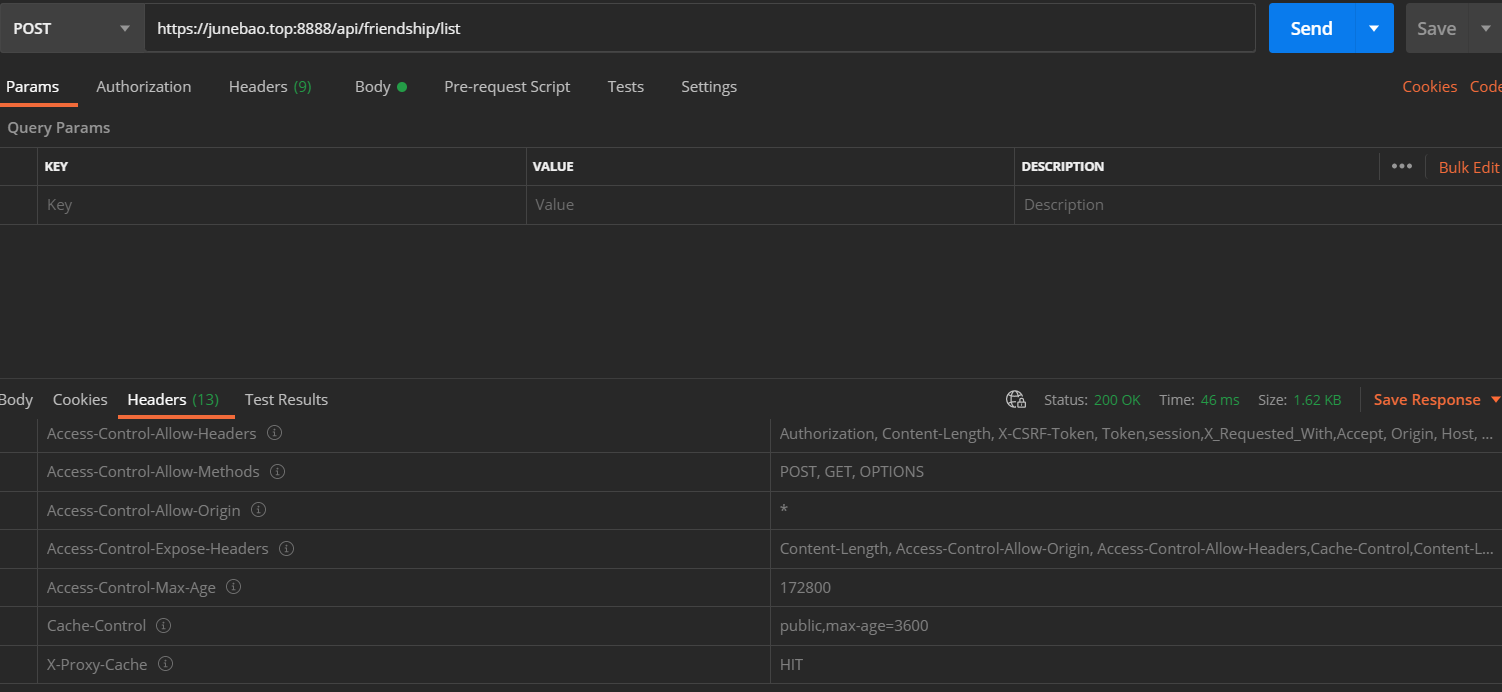
這里只是簡單對數據進行了緩存,服務端沒有提供緩存驗證的功能,所以可能出現服務端數據已經改變但緩存沒更新的情況。
HTTPS 細節
HTTPS 的原理
密碼學基礎
對稱加密和非對稱加密
-
對稱加密: 加密和解密時使用的密鑰是一樣的,比如 DES, 優點是速度快,缺點是在協商密鑰時,可能會泄露密鑰
-
非對稱加密:有兩個密鑰,公鑰和私鑰,使用公鑰加密,私鑰解密,公鑰是公開的,比如 RSA。
非對稱加密有一個形象的比喻:
A有一份機密文件,想要發給B,發之前先向B要一個打開的保險柜,把文件裝進保險柜鎖住后再發給B,整個過程中保險柜密碼只有B知道,這里的保險柜相當于公鑰,保險柜密碼相當于私鑰。
CA機構和證書
公鑰是公開的,那怎么證明這個公鑰是屬于你的呢?接上面的比喻,如果有一個中間人 C,在 B 向 A 發保險柜的時候將 B 的保險柜換成自己的發給 A,這樣 C 就可以竊取到文件,A 如果想要驗證這個保險柜是不是 B 的,就需要一個 A、B 都信任的第三方機構,B 在發給 A 之前請求第三方機構在保險箱上蓋一個戳,A 收到后再請求第三方機構檢查戳是不是真的就可以了,這里的第三方機構就是 CA 機構,這個戳就是證書,具體來說:
每個CA機構都會有自己的一組密鑰對(CA 的公鑰是通信雙方都信任的),現在 B 有一個公鑰,他要證明這個公鑰是他的,就需要向 CA 機構請求一份該公鑰的證書,請求時,B 需要向 CA 機構提供自己的信息以及要認證的公鑰(這些信息會組成CSR文件),CA 機構收到請求后,會檢查 CSR 的真實性,檢查無誤后,CA 會將 CSR 的內容哈希后用自己的私鑰簽名,然后將 CSR 中的信息和簽名組合成證書發給 B。
所以一份證書中包含的典型內容包括:
- 明文的證書持有者信息
- 明文的公鑰
- CA 的簽名
- 證書用途,使用的算法,證書過期時間,頒發者信息,CRL分發點等
B 有了 CA 機構的證書,在向 A 發送公鑰時就只需要發送證書了,A 收到證書,用 CA 機構的公鑰解密簽名,然后對證書中的明文數據以同樣的算法做哈希,只需要對比兩個哈希值就可以判斷證書有沒有被篡改了,如果證書沒被篡改,則可以放心使用證書中的公鑰與 B 通信了。
HTTPS 通信流程
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-8HD5SxsD-1613829654732)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\image-20210122163508612.png)]
看上面的截圖,前三行 [SYN], [SYN, ACK], [ACK] 是典型的 TCP 三次握手,那么在三次握手后,客戶端向服務端以 TLSV1.2 協議向服務端發送了一個 client Hello 包,通過 Client Hello, 客戶端會生成一個隨機數,并告訴服務端自己支持的加密,哈希等算法,我們可以在這個報文里看到這些內容:
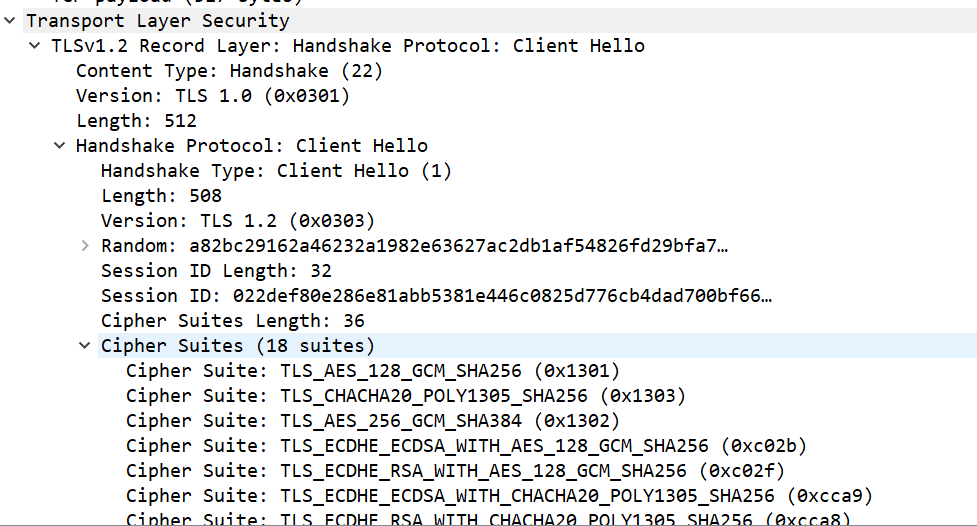
其中,Random 就是客戶端選取的隨機數,Cipher Suites 中就是客戶端支持的算法。
接下來就是 Server Hello, 在這一步,服務端同樣會生成一個隨機數,并且會從客戶端支持的算法中選取一種,通過 Server Hello 的方式告訴客戶端:
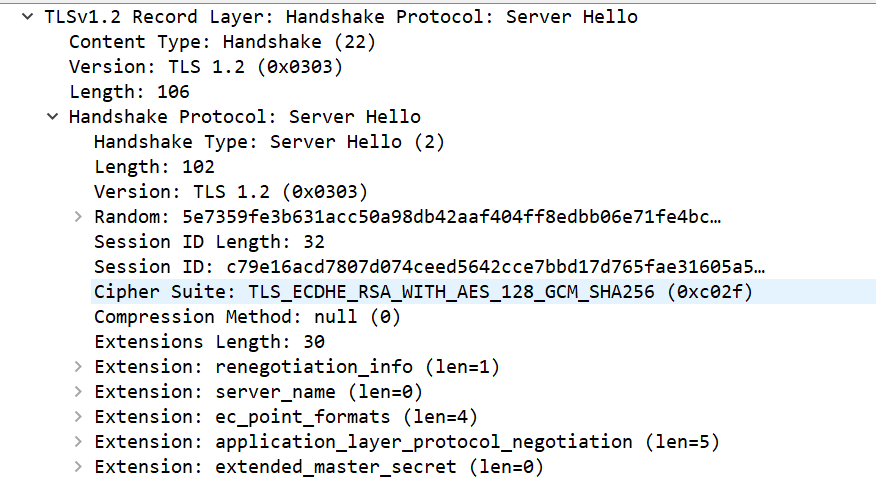
可以看到 Server Hello 和 Client Hello 的報文內容區別不大,只是 Client Hello 中的 Cipher Suite 有許多項,而 Server Hello 的只有一項,因為服務端會選擇安全性最高的加密方式,需要注意的是這里選擇的是一組算法,以這里選擇的 0xc02f 為例,它的名字叫 TLS_ECDHE_RSA_WITH_AES_128_GCM_ SHA256 (0xc02f) 其中包括:
- 密鑰交換算法:ECDHE
- 身份驗證算法:RSA
- 對稱加密算法:AES_128_GCM
- 摘要算法:SHA256
在這之后,服務端在一個 TLS 包里進行了三個負載:
- Certificate:發送證書
- Server Key Exchange:包含密鑰交換算法 DHE/ECDHE 所需要的額外參數。
- Server Hello Done:表明服務端相關信息發送結束,這之后服務端會等待客戶端響應。
到這一步,客戶端已經拿到了服務器的證書,會檢查證書是否有效,如果證書失效,客戶端瀏覽器會阻止后續操作,反之,客戶端會繼續與服務端協商對稱加密密鑰:
客戶端向服務端發送一個響應(id = 67)包含三個負載:
- Client Key Exchange:類似 Server Key Exchange,客戶端生成一個新的隨機數(Premaster secret),并使用數字證書中的公鑰加密后發給服務端。
- Change cipher Spec: 已被廢棄,不攜帶數據
- Encrypted handshake message:這個步驟客戶端和服務器在握手完后都會進行,以告訴對方自己在整個握手過程中收到了什么數據,發送了什么數據,保證中間沒人篡改報文。
到現在為止,我們總結一下客戶端和服務器做了什么:
- 客戶端生成了一個隨機數 Client Random 發給了服務端
- 服務端也生成了一個隨機數 Server Random 發給了客戶端,同時,雙方還協商了以后要用到的哈希,加密算法。
- 服務端把自己的證書發給了客戶端。
- 客戶端又生成了一個新隨機數,并用服務端證書中的公鑰進行加密后發給了服務端。
- 客戶端和服務端通過互發 Encrypted handshake message 確保了數據沒被 中間人篡改。
現在,根據三個隨機數,客戶端和服務器就會根據約定好的對稱加密算法生成最終的對稱加密密鑰,后續的數據傳輸就會使用該密鑰加密。
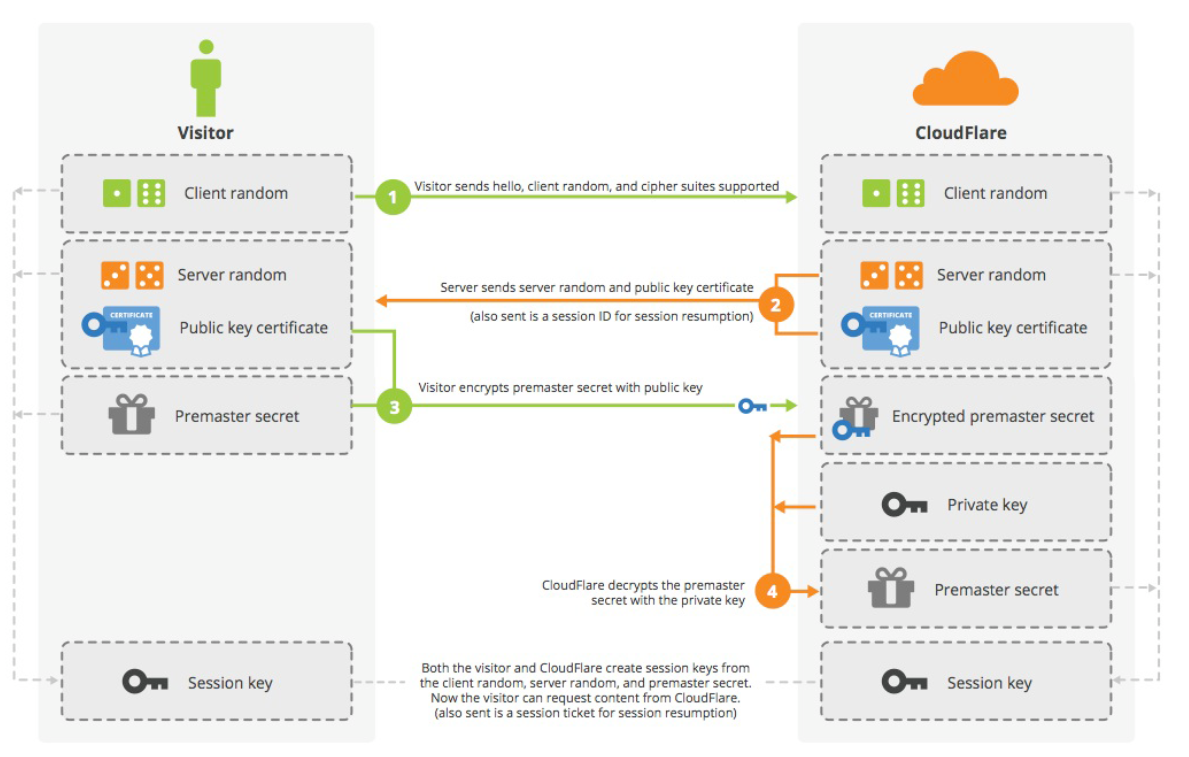
總結
HTTPS 建立連接的過程總結如下:
- TCP 三次握手
- 客戶端向服務器發送
Client Hello包,包含 TLS 版本,客戶端生成的隨機數 Client Random, 客戶端支持的算法等信息 - 服務器向客戶端發送
Server Hello包,包含服務端生成的隨機數 Server Random,服務端選擇的算法等信息。 - 服務端向客戶端發送證書。
- 客戶端檢查證書有效后,生成一個新的隨機數 Premaster secret 并用證書中的公鑰加密發給服務端。
- 服務端使用自己的私鑰解密 Premaster secret。
- 客戶端和服務端分別使用三個隨機數,依照約定的算法生成對話密鑰 session key。
- 客戶端和服務端使用 session key 加密后續的會話。
使用 HTTPS
nginx 配置示例:
server {listen 443 ssl http2;server_name *.junebao.top;# 證書ssl_certificate 1_www.junebao.top_bundle.crt;# 私鑰ssl_certificate_key 2_www.junebao.top.key;ssl_session_timeout 5m;ssl_protocols TLSv1 TLSv1.1 TLSv1.2;ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;ssl_prefer_server_ciphers on;error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
HTTP/2 細節
實現
2015 年,HTTP/2 發布。HTTP/2 是現行 HTTP 協議(HTTP/1.x)的替代,但它不是重寫,HTTP 方法/狀態碼/語義都與 HTTP/1.x 一樣。HTTP/2 基于 SPDY3,專注于性能,最大的一個目標是在用戶和網站間只用一個連接(connection)。
那么SPDY3是什么呢?
SPDY是谷歌自行研發的 SPDY 協議,主要解決 HTTP/1.1 效率不高的問題。谷歌推出 SPDY,才算是正式改造 HTTP 協議本身。降低延遲,壓縮 header 等等,SPDY 的實踐證明了這些優化的效果,也最終帶來 HTTP/2 的誕生。
HTTP/2 由兩個規范(Specification)組成:
- Hypertext Transfer Protocol version 2 - RFC7540
- HPACK - Header Compression for HTTP/2 - RFC7541
那么HTTP2在HTTP1.1的基礎上做了哪些改進
- 二進制傳輸
- 請求和響應復用
- Header壓縮
- Server Push(服務端推送)
二進制傳輸
HTTP/2 采用二進制格式傳輸數據,而非 HTTP 1.x 的文本格式,二進制協議解析起來更高效。 HTTP / 1 的請求和響應報文,都是由起始行,首部和實體正文(可選)組成,各部分之間以文本換行符分隔。HTTP/2 將請求和響應數據分割為更小的幀,并且它們采用二進制編碼。
新的二進制分幀機制改變了客戶端與服務器之間交換數據的方式。 為了說明這個過程,我們需要了解 HTTP/2 的三個概念:
- 數據流:已建立的連接內的雙向字節流,可以承載一條或多條消息。
- 消息:與邏輯請求或響應消息對應的完整的一系列幀。
- 幀:HTTP/2 通信的最小單位,每個幀都包含幀頭,至少也會標識出當前幀所屬的數據流。
這些概念的關系總結如下:
- 所有通信都在一個 TCP 連接上完成,此連接可以承載任意數量的雙向數據流。
- 每個數據流都有一個唯一的標識符和可選的優先級信息,用于承載雙向消息。
- 每條消息都是一條邏輯 HTTP 消息(例如請求或響應),包含一個或多個幀。
- 幀是最小的通信單位,承載著特定類型的數據,例如 HTTP 標頭、消息負載等等。 來自不同數據流的幀可以交錯發送,然后再根據每個幀頭的數據流標識符重新組裝。
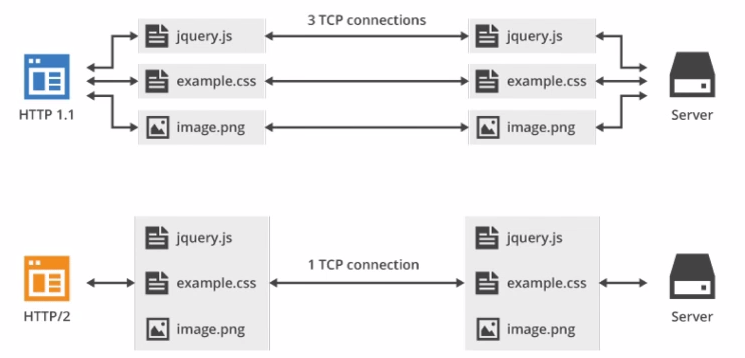
請求和響應復用
在 HTTP/1.x 中,如果客戶端要想發起多個并行請求以提升性能,則必須使用多個 TCP 連接,這是 HTTP/1.x 交付模型的直接結果,該模型可以保證每個連接每次只交付一個響應(響應排隊)。 更糟糕的是,這種模型也會導致隊首阻塞,從而造成底層 TCP 連接的效率低下。
HTTP/2 中新的二進制分幀層突破了這些限制,實現了完整的請求和響應復用:客戶端和服務器可以將 HTTP 消息分解為互不依賴的幀,然后交錯發送,最后再在另一端把它們重新組裝起來。
在 HTTP/2 中,有了二進制分幀之后,HTTP /2 不再依賴 TCP 鏈接去實現多流并行了,在 HTTP/2 中:
- 同域名下所有通信都在單個連接上完成。
- 單個連接可以承載任意數量的雙向數據流。
- 數據流以消息的形式發送,而消息又由一個或多個幀組成,多個幀之間可以亂序發送,因為根據幀首部的流標識可以重新組裝。
這一特性,使性能有了極大提升:
- 同個域名只需要占用一個 TCP 連接,使用一個連接并行發送多個請求和響應,消除了因多個 TCP 連接而帶來的延時和內存消耗。
- 并行交錯地發送多個請求,請求之間互不影響。
- 并行交錯地發送多個響應,響應之間互不干擾。
- 在 HTTP/2 中,每個請求都可以帶一個 31bit 的優先值,0 表示最高優先級, 數值越大優先級越低。有了這個優先值,客戶端和服務器就可以在處理不同的流時采取不同的策略,以最優的方式發送流、消息和幀。
Header壓縮
在 HTTP/1 中,我們使用文本的形式傳輸 header,在 header 攜帶 cookie 的情況下,可能每次都需要重復傳輸幾百到幾千的字節。為了減少這塊的資源消耗并提升性能,HTTP/2 使用 HPACK 壓縮格式壓縮請求和響應標頭元數據,這種格式采用兩種強大的技術:
- 這種格式支持通過靜態霍夫曼代碼對傳輸的標頭字段進行編碼,從而減小了各個傳輸的大小。
- 這種格式要求客戶端和服務器同時維護和更新一個包含之前見過的標頭字段的索引列表(換句話說,它可以建立一個共享的壓縮上下文),此列表隨后會用作參考,對之前傳輸的值進行有效編碼。
利用霍夫曼編碼,可以在傳輸時對各個值進行壓縮,而利用之前傳輸值的索引列表,我們可以通過傳輸索引值的方式對重復值進行編碼,索引值可用于有效查詢和重構完整的標頭鍵值對。
作為一種進一步優化方式,HPACK 壓縮上下文包含一個靜態表和一個動態表:靜態表在規范中定義,并提供了一個包含所有連接都可能使用的常用 HTTP 標頭字段(例如,有效標頭名稱)的列表;動態表最初為空,將根據在特定連接內交換的值進行更新。 因此,為之前未見過的值采用靜態 Huffman 編碼,并替換每一側靜態表或動態表中已存在值的索引,可以減小每個請求的大小。
注:在 HTTP/2 中,請求和響應標頭字段的定義保持不變,僅有一些微小的差異:所有標頭字段名稱均為小寫,請求行現在拆分成各個 :method、:scheme、:authority 和 :path 偽標頭字段。
如需了解有關 HPACK 壓縮算法的完整詳情,請參閱 IETF HPACK - HTTP/2 的標頭壓縮。
Server Push
HTTP/2 新增的另一個強大的新功能是,服務器可以對一個客戶端請求發送多個響應。 換句話說,除了對最初請求的響應外,服務器還可以向客戶端推送額外資源如下圖所示,而無需客戶端明確地請求。
為什么在瀏覽器中需要一種此類機制呢?一個典型的網絡應用包含多種資源,客戶端需要檢查服務器提供的文檔才能逐個找到它們。 那為什么不讓服務器提前推送這些資源,從而減少額外的延遲時間呢? 服務器已經知道客戶端下一步要請求什么資源,這時候服務器推送即可派上用場。
事實上,如果您在網頁中內聯過 CSS、JavaScript,或者通過數據 URI 內聯過其他資產(請參閱資源內聯),那么您就已經親身體驗過服務器推送了。 對于將資源手動內聯到文檔中的過程,我們實際上是在將資源推送給客戶端,而不是等待客戶端請求。 使用 HTTP/2,我們不僅可以實現相同結果,還會獲得其他性能優勢。 推送資源可以進行以下處理:
- 由客戶端緩存
- 在不同頁面之間重用
- 與其他資源一起復用
- 由服務器設定優先級
- 被客戶端拒絕
服務端推送如何實現
所有服務器推送數據流都由 PUSH_PROMISE 幀發起,表明了服務器向客戶端推送所述資源的意圖,并且需要先于請求推送資源的響應數據傳輸。 這種傳輸順序非常重要:客戶端需要了解服務器打算推送哪些資源,以免為這些資源創建重復請求。 滿足此要求的最簡單策略是先于父響應(即,DATA 幀)發送所有 PUSH_PROMISE 幀,其中包含所承諾資源的 HTTP 標頭。
在客戶端接收到 PUSH_PROMISE 幀后,它可以根據自身情況選擇拒絕數據流(通過 RST_STREAM 幀)。 (例如,如果資源已經位于緩存中,便可能會發生這種情況。) 這是一個相對于 HTTP/1.x 的重要提升。 相比之下,使用資源內聯(一種受歡迎的 HTTP/1.x“優化”)等同于“強制推送”:客戶端無法選擇拒絕、取消或單獨處理內聯的資源。
使用 HTTP/2,客戶端仍然完全掌控服務器推送的使用方式。 客戶端可以限制并行推送的數據流數量;調整初始的流控制窗口以控制在數據流首次打開時推送的數據量;或完全停用服務器推送。 這些優先級在 HTTP/2 連接開始時通過 SETTINGS 幀傳輸,可能隨時更新。
過渡到 HTTP/2
上面說了這么多,我們要如何啟用HTTP2呢?
如果你使用的是 nginx,那么你只需要加一個 http2 即可:
server {listen 8888 ssl http2;server_name *.junebao.top;# ...
}
如果你使用 Golang 的 Gin 框架,他默認支持 HTTP/2,你可以使用 RunTLS() 使用 HTTP/2,如下:
package mainimport ("github.com/gin-gonic/gin"
)func main() {engine := gin.Default()engine.GET("./", func(context *gin.Context) {context.JSON(200, map[string]string{"msg": "ok"})})// 服務端推送engine.Static("/static", "./static")engine.GET("/push", func(context *gin.Context) {pusher := context.Writer.Pusher()if pusher != nil {err := pusher.Push("/static/test.js", nil)if err != nil {log.Println("push fail", err)}}context.JSON(200, map[string]string{"msg": "ok"})})engine.RunTLS(":8888", "./root_cer.cer", "./root_private_key.pem")
}
如果你使用的是 spring boot 內置的 Tomcat 服務器,那么只需要在配置文件中添加配置:
server:http2:enabled: on
只有 Tomcat 9 版本之后版本才支持 HTTP/2 協議。在 conf/server.xml 中增加內容:
<Connector port="8443" protocol="org.apache.coyote.http11.Http11AprProtocol" maxThreads="150" SSLEnabled="true">
<UpgradeProtocol className="org.apache.coyote.http2.Http2Protocol"/>
<SSLHostConfig honorCipherOrder="false">
<Certificate certificateKeyFile="conf/ca.key" certificateFile="conf/ca.crt"/>
</SSLHostConfig>
</Connector>
HTTP/3 細節
為什么要出現HTTP3
雖然 HTTP/2 解決了很多之前舊版本的問題,但是它還是存在一個巨大的問題,主要是底層支撐的 TCP 協議造成的。
上文提到 HTTP/2 使用了多路復用,一般來說同一域名下只需要使用一個 TCP 連接。但當這個連接中出現了丟包的情況,那就會導致 HTTP/2 的表現情況反倒不如 HTTP/1 了。
因為在出現丟包的情況下,整個 TCP 都要開始等待重傳,也就導致了后面的所有數據都被阻塞了。但是對于 HTTP/1.1 來說,可以開啟多個 TCP 連接,出現這種情況反到只會影響其中一個連接,剩余的 TCP 連接還可以正常傳輸數據。
那么可能就會有人考慮到去修改 TCP 協議,其實這已經是一件不可能完成的任務了。因為 TCP 存在的時間實在太長,已經充斥在各種設備中,并且這個協議是由操作系統實現的,更新起來不大現實。
基于這個原因,Google 就更起爐灶搞了一個基于 UDP 協議的 QUIC 協議,并且使用在了 HTTP/3 上,HTTP/3 之前名為 HTTP-over-QUIC,從這個名字中我們也可以發現,HTTP/3 最大的改造就是使用了 QUIC(快速 UDP Internet 連接)。
QUIC
QUIC(Quick UDP Internet Connection)是谷歌制定的一種基于UDP的低時延的互聯網傳輸層協議。在2016年11月國際互聯網工程任務組(IETF)召開了第一次QUIC工作組會議,受到了業界的廣泛關注。這也意味著QUIC開始了它的標準化過程,成為新一代傳輸層協議 。
優勢:
- 高效地建立連接: 將 TLS 協商密鑰和協議作為打開連接握手地一部分,加上對 client Hello 地緩存,在大部分情況下,QUIC 建立連接只需要 0RTT,而普通的 HTTPS 則至少需要 2RTT
- 改進地擁塞控制方案:TCP 擁塞控制包括:慢啟動,擁塞避免,快速重傳,快速恢復,QUIC 在 UDP 基礎上實現了相關算法并做了改進,使之具有可插拔,高效地特點。
- 基于 stream 和 connecton 級別的流量控制。
- 沒有 TCP 隊頭阻塞地多路復用:HTTP/2 通過二進制分幀層避免了 HTTP 隊頭阻塞,但由于依然使用 TCP 協議,就避免不了 TCP 隊頭阻塞,QUIC 基于 UDP,多個 stream 之間沒有依賴。這樣假如 stream2 丟了一個 udp packet,也只會影響 stream2 的處理。不會影響 stream2 之前及之后的 stream 的處理,這也就在很大程度上緩解甚至消除了隊頭阻塞的影響。
- 加密認證地報文:TCP 協議頭部沒有經過任何加密和認證,所以在傳輸過程中很容易被中間網絡設備篡改,注入和竊聽。比如修改序列號、滑動窗口。這些行為有可能是出于性能優化,也有可能是主動攻擊。但是 QUIC 的 packet 可以說是武裝到了牙齒。除了個別報文比如 PUBLIC_RESET 和 CHLO,所有報文頭部都是經過認證的,報文 Body 都是經過加密的.
- 連接遷移:一條 TCP 連接是由四元組標識的(源 IP,源端口,目的 IP,目的端口)。什么叫連接遷移呢?就是當其中任何一個元素發生變化時,這條連接依然維持著,能夠保持業務邏輯不中斷。當然這里面主要關注的是客戶端的變化,因為客戶端不可控并且網絡環境經常發生變化,而服務端的 IP 和端口一般都是固定的,而 QUIC 連接不再以 IP 及端口四元組標識,而是以一個 64 位的隨機數作為 ID 來標識,這樣就算 IP 或者端口發生變化時,只要 ID 不變,這條連接依然維持著,上層業務邏輯感知不到變化,不會中斷,也就不需要重連。由于這個 ID 是客戶端隨機產生的,并且長度有 64 位,所以沖突概率非常低。
- 向前糾錯: 每個數據包除了它本身的內容之外,還包括了部分其他數據包的數據,因此少量的丟包可以通過其他包的冗余數據直接組裝而無需重傳。向前糾錯犧牲了每個數據包可以發送數據的上限,但是減少了因為丟包導致的數據重傳,因為數據重傳將會消耗更多的時間(包括確認數據包丟失、請求重傳、等待新數據包等步驟的時間消耗);假如說這次我要發送三個包,那么協議會算出這三個包的異或值并單獨發出一個校驗包,也就是總共發出了四個包。當出現其中的非校驗包丟包的情況時,可以通過另外三個包計算出丟失的數據包的內容。當然這種技術只能使用在丟失一個包的情況下,如果出現丟失多個包就不能使用糾錯機制了,只能使用重傳的方式了。
- 證書壓縮等.
可見HTTP3在效率上和安全性上都有了很大程度上的修改,但是由于目前這個標準還在論證中,Nginx等也只是在測試版中加入了對HTTP3的支持,等到技術真正的論證實現完成,我們就可以使用上快速且安全的HTTP3協議了,期待著這一天的到來。
參考
mozilla 開發文檔
谷歌開發文檔 HTTP2 簡介
Nginx緩存最佳實踐
讓互聯網更快:新一代QUIC協議在騰訊的技術實踐分享






![[轉]關于凸優化的一些簡單概念](http://pic.xiahunao.cn/[轉]關于凸優化的一些簡單概念)






的關系)
![[譯] Bounds Check Elimination 邊界檢查消除](http://pic.xiahunao.cn/[譯] Bounds Check Elimination 邊界檢查消除)

)


