參考:https://blog.csdn.net/u013733326/article/details/79971488
希望大家直接到上面的網址去查看代碼,下面是本人的筆記
到目前為止,我們一直在使用numpy來自己編寫神經網絡。現在我們將一步步的使用深度學習的框架來很容易的構建屬于自己的神經網絡。我們將學習TensorFlow這個框架:
初始化變量
建立一個會話
訓練的算法
實現一個神經網絡
使用框架編程不僅可以節省你的寫代碼時間,還可以讓你的優化速度更快。
1.導入TensorFlow庫
import numpy asnp
import h5py
import matplotlib.pyplotasplt
import tensorflowastffromtensorflow.python.framework import ops
import tf_utils
import time
#%matplotlib inline #如果你使用的是jupyter notebook取消注釋
np.random.seed(1)
2.說明TensorFlow代碼的實現流程
對于Tensorflow的代碼實現而言,實現代碼的結構如下:
創建Tensorflow變量(此時,尚未直接計算)
實現Tensorflow變量之間的操作定義
初始化Tensorflow變量
創建Session
運行Session,此時,之前編寫操作都會在這一步運行。
1)所以舉例如果要計算損失函數:
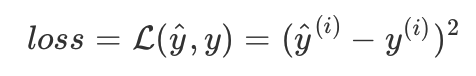
實現流程為:
#首先創建變量,這里設置了常量
y_hat= tf.constant(36,name="y_hat") #定義y_hat為固定值36
y= tf.constant(39,name="y") #定義y為固定值39
#實現變量之間的操作定義,即損失函數的計算
loss= tf.Variable((y-y_hat)**2,name="loss") #為損失函數創建一個變量
#聲明變量的初始化操作
init=tf.global_variables_initializer() #運行之后的初始化(session.run(init))
#創建session,并打印輸出
#損失變量將被初始化并準備計算
with tf.Session()assession:
#初始化變量
session.run(init)
#運行session,這樣之前定義的變量間的操作都會在這里運行,打印損失值
print(session.run(loss))
返回9
查看初始化和運行前后變量的變化:
#首先創建變量
y_hat= tf.constant(36,name="y_hat") #定義y_hat為固定值36
y= tf.constant(39,name="y") #定義y為固定值39
#實現變量之間的操作定義,即損失函數的計算
loss= tf.Variable((y-y_hat)**2,name="loss") #為損失函數創建一個變量
print(y_hat)
print(y)
print(loss)
#聲明變量的初始化操作
init=tf.global_variables_initializer() #運行之后的初始化(session.run(init))
#創建session,并打印輸出
#損失變量將被初始化并準備計算
with tf.Session()assession:
#初始化變量
session.run(init)
print(y_hat)
print(y)
print(loss)
#運行session,這樣之前定義的變量間的操作都會在這里運行,打印損失值
print(session.run(loss))
print(y_hat)
print(y)
返回:
Tensor("y_hat_2:0", shape=(), dtype=int32)
Tensor("y_2:0", shape=(), dtype=int32)Tensor("y_hat_2:0", shape=(), dtype=int32)
Tensor("y_2:0", shape=(), dtype=int32)
9Tensor("y_hat_2:0", shape=(), dtype=int32)
Tensor("y_2:0", shape=(), dtype=int32)
再運行一遍,可見版本號會變:
Tensor("y_hat_3:0", shape=(), dtype=int32)
Tensor("y_3:0", shape=(), dtype=int32)Tensor("y_hat_3:0", shape=(), dtype=int32)
Tensor("y_3:0", shape=(), dtype=int32)
9Tensor("y_hat_3:0", shape=(), dtype=int32)
Tensor("y_3:0", shape=(), dtype=int32)
如果注釋掉初始化就會報錯:
#首先創建變量
y_hat= tf.constant(36,name="y_hat") #定義y_hat為固定值36
y= tf.constant(39,name="y") #定義y為固定值39
#實現變量之間的操作定義,即損失函數的計算
loss= tf.Variable((y-y_hat)**2,name="loss") #為損失函數創建一個變量
print(y_hat)
print(y)
print(loss)
#聲明變量的初始化操作
#init=tf.global_variables_initializer() #運行之后的初始化(session.run(init))
#創建session,并打印輸出
#損失變量將被初始化并準備計算
with tf.Session()assession:
#初始化變量
#session.run(init)
#運行session,這樣之前定義的變量間的操作都會在這里運行,打印損失值
print(session.run(loss))
print(y_hat)
print(y)
返回:
Tensor("y_hat_5:0", shape=(), dtype=int32)
Tensor("y_5:0", shape=(), dtype=int32)...
FailedPreconditionError: Attempting to use uninitialized value loss_5
[[{{node _retval_loss_5_0_0}}= _Retval[T=DT_INT32, index=0, _device="/job:localhost/replica:0/task:0/device:CPU:0"](loss_5)]]
因此,當我們為損失函數創建一個變量時,我們簡單地將損失定義為其他數量的函數,但沒有評估它的價值。
為了評估它,我們需要運行init=tf.global_variables_initializer(),初始化損失變量,在最后一行,我們最后能夠評估損失的值并打印它的值。
所以init=tf.global_variables_initializer()的作用對應的是聲明為變量的損失函數loss = tf.Variable((y-y_hat)**2,name="loss")
2)另外一個更簡單的函數
#創建變量
a= tf.constant(2)
b= tf.constant(10)
#實現變量之間的操作定義
c=tf.multiply(a,b)
print(c)
返回:
Tensor("Mul:0", shape=(), dtype=int32)
正如預料中一樣,我們并沒有看到結果20,不過我們得到了一個Tensor類型的變量,沒有維度,數字類型為int32。我們之前所做的一切都只是把這些東西放到了一個“計算圖(computation graph)”中,而我們還沒有開始運行這個計算圖,為了實際計算這兩個數字,我們需要創建一個會話并運行它:
#創建會話
sess=tf.Session()
#使用會話運行操作
print(sess.run(c)) #返回20
??因為這里沒有聲明變量,所以不用使用init=tf.global_variables_initializer()來初始化變量
總結一下,記得初始化變量,然后創建一個session來運行它。
3.會話
可以使用兩種方法來創建并使用session
方法一:
sess =tf.Session()
result= sess.run(...,feed_dict ={...})
sess.close()
方法二:
with tf.Session assess:
result= sess.run(...,feed_dict = {...})
4.占位符(placeholder)
占位符是一個對象,它的值只能在稍后指定,要指定占位符的值,可以使用一個feed_dict變量來傳入,接下來,我們為x創建一個占位符,這將允許我們在稍后運行會話時傳入一個數字。
#利用feed_dict來改變x的值
x= tf.placeholder(tf.int64,name="x")
print(x)
print(sess.run(2 * x,feed_dict={x:3}))
sess.close()
返回:
Tensor("x:0", dtype=int64)6
當我們第一次定義x時,我們不必為它指定一個值。 占位符只是一個變量,我們會在運行會話時將數據分配給它。
5.線性函數
讓我們通過計算以下等式來開始編程:Y=WX+b,W和X是隨機矩陣,b是隨機向量。
我們計算WX+b,其中W,X和b是從隨機正態分布中抽取的。 W的維度是(4,3),X是(3,1),b是(4,1)。
我們開始定義一個shape=(3,1)的常量X:
X = tf.constant(np.random.randn(3,1), name = "X")
代碼:
def linear_function():"""實現一個線性功能:
初始化W,類型為tensor的隨機變量,維度為(4,3)
初始化X,類型為tensor的隨機變量,維度為(3,1)
初始化b,類型為tensor的隨機變量,維度為(4,1)
返回:
result- 運行了session后的結果,運行的是Y = WX +b"""np.random.seed(1) #指定隨機種子
X= np.random.randn(3,1)
W= np.random.randn(4,3)
b= np.random.randn(4,1)
Y=tf.add(tf.matmul(W,X),b) #tf.matmul是矩陣乘法
#Y= tf.matmul(W,X) +b #也可以以寫成這樣子
#創建一個session并運行它
sess=tf.Session()
result=sess.run(Y)
#session使用完畢,關閉它
sess.close()return result
測試:
print("result =" + str(linear_function()))
返回:
result = [[-2.15657382]
[2.95891446]
[-1.08926781]
[-0.84538042]]
6.計算sigmoid函數
TensorFlow提供了多種常用的神經網絡的函數比如tf.softmax和tf.sigmoid。
我們將使用占位符變量x,當運行這個session的時候,我們西藥使用使用feed_dict來輸入z,我們將創建占位符變量x,使用tf.sigmoid來定義操作,最后運行session,我們會用到下面的代碼:
tf.placeholder(tf.float32, name = “x”)
sigmoid = tf.sigmoid(x)
sess.run(sigmoid, feed_dict = {x: z})
實現:
def sigmoid(z):"""實現使用sigmoid函數計算z
參數:
z-輸入的值,標量或矢量
返回:
result-用sigmoid計算z的值"""#創建一個占位符x,名字叫“x”
x= tf.placeholder(tf.float32,name="x")
#計算sigmoid(z)
sigmoid=tf.sigmoid(x)
#創建一個會話,使用方法二
with tf.Session()assess:
result= sess.run(sigmoid,feed_dict={x:z})return result
測試:
print ("sigmoid(0) =" + str(sigmoid(0)))
print ("sigmoid(12) =" + str(sigmoid(12)))
返回:
sigmoid(0) = 0.5sigmoid(12) = 0.9999938
7.計算成本函數
還可以使用內置函數計算神經網絡的成本。因此,不需要編寫代碼來計算成本函數的a[2](i)和y(i),如:
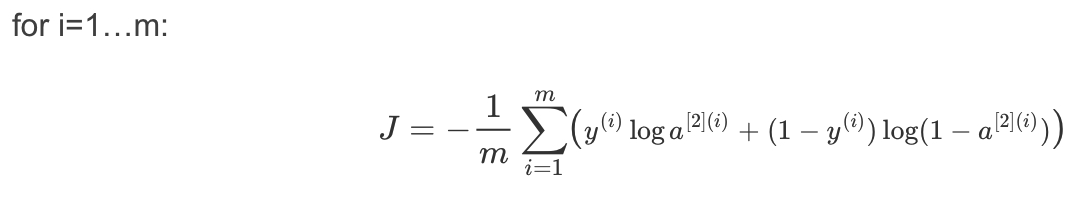
tensorflow提供了用來計算成本的函數:
tf.nn.sigmoid_cross_entropy_with_logits(logits = ..., labels = ...)
logits:前向傳播的結果AL,如果使用的是softmax,這里傳入的是ZL
labels:真正的結果Y
8.使用獨熱編碼(0,1編碼)
很多時候在深度學習中y向量的維度是從0到C?1的,C是指分類的類別數量,如果C=4,那么對y而言你可能需要有以下的轉換方式:
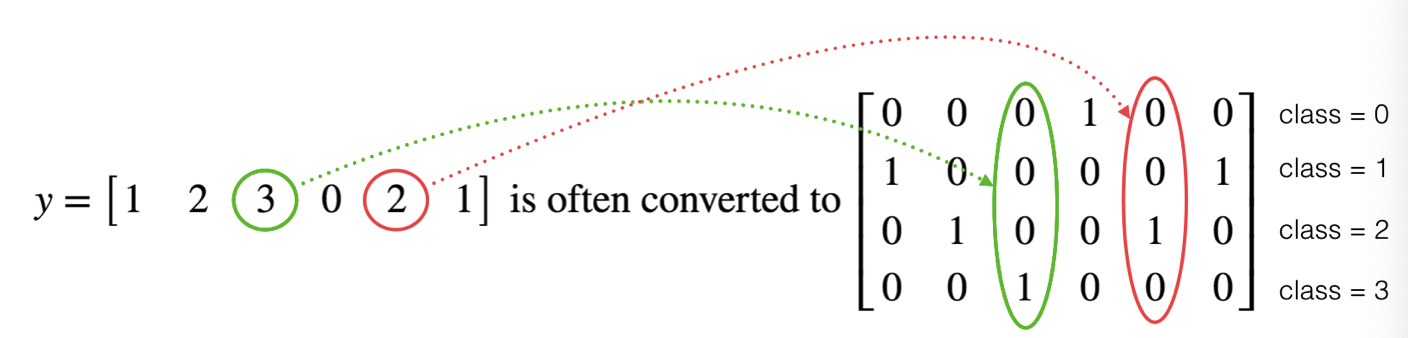
這叫做獨熱編碼(”one hot” encoding),因為在轉換后的表示中,每列的一個元素是“hot”(意思是設置為1)。 要在numpy中進行這種轉換,您可能需要編寫幾行代碼。 在tensorflow中,只需要使用一行代碼:
tf.one_hot(labels,depth,axis)
下面我們要做的是取一個標簽矢量(即圖片的判斷結果)和C類總數,返回一個獨熱編碼。
def one_hot_matrix(lables,C):"""創建一個矩陣,其中第i行對應第i個類號,第j列對應第j個訓練樣本
所以如果第j個樣本對應著第i個標簽,那么entry (i,j)將會是1
參數:
lables-標簽向量
C-分類數
返回:
one_hot-獨熱矩陣"""#創建一個tf.constant,賦值為C,名字叫C
C= tf.constant(C,name="C")
#使用tf.one_hot,注意一下axis
one_hot_matrix= tf.one_hot(indices=lables , depth=C , axis=0)
#創建一個session
sess=tf.Session()
#運行session
one_hot=sess.run(one_hot_matrix)
#關閉session
sess.close()return one_hot
測試:
labels = np.array([1,2,3,0,2,1])
one_hot= one_hot_matrix(labels,C=4)
print(str(one_hot))
返回:
[[0. 0. 0. 1. 0. 0.]
[1. 0. 0. 0. 0. 1.]
[0. 1. 0. 0. 1. 0.]
[0. 0. 1. 0. 0. 0.]]
9.初始化參數
學習如何用0或者1初始化一個向量,我們要用到tf.ones()和tf.zeros(),給定這些函數一個維度值那么它們將會返回全是1或0的滿足條件的向量/矩陣,我們來看看怎樣實現它們:
def ones(shape):"""創建一個維度為shape的變量,其值全為1
參數:
shape-你要創建的數組的維度
返回:
ones-只包含1的數組"""#使用tf.ones()
ones=tf.ones(shape)
#創建會話
sess=tf.Session()
#運行會話
ones=sess.run(ones)
#關閉會話
sess.close()return ones
測試:
print ("ones =" + str(ones([3])))
返回:
ones = [1. 1. 1.]
)








![[轉載]SYSCALL_DEFINE宏定義](http://pic.xiahunao.cn/[轉載]SYSCALL_DEFINE宏定義)








——DataSource篇)
![【BZOJ 1597】 [Usaco2008 Mar]土地購買 (斜率優化)](http://pic.xiahunao.cn/【BZOJ 1597】 [Usaco2008 Mar]土地購買 (斜率優化))