多線程工作原理
多線程示意圖
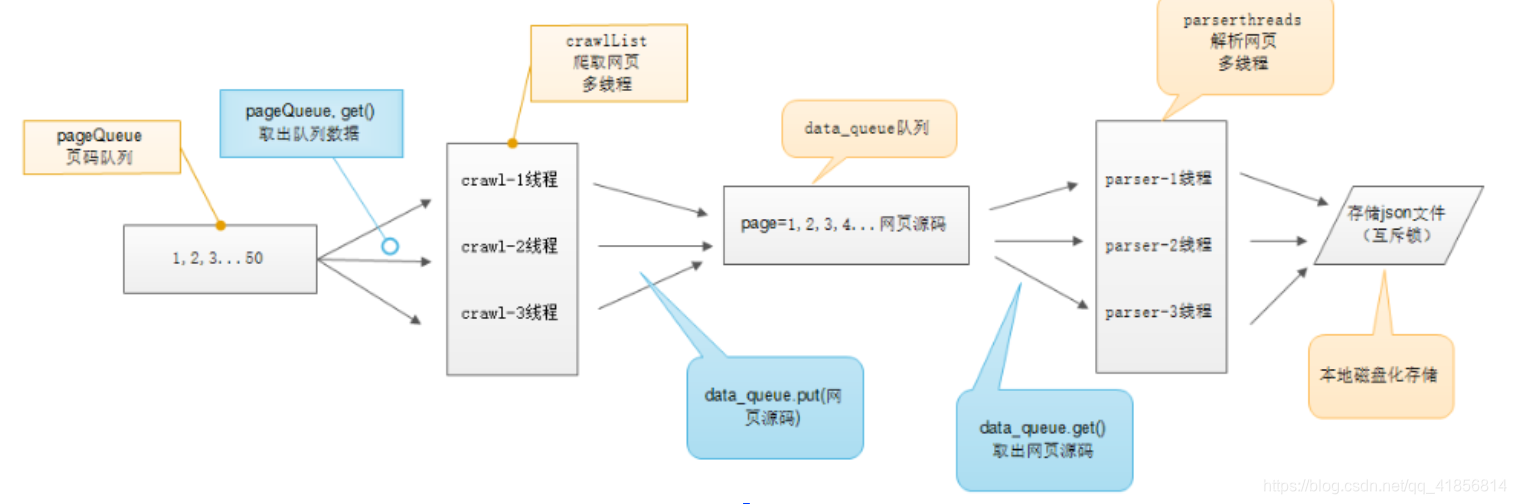
?
Queue(隊列對象)
queue是python中的標準庫,可以直接from queue import Queue引用;隊列是線程間最常用的交換數據的形式
?
python下多線程的思考
對于資源,加鎖是個重要的環節。Queue,是線程安全的,因此在滿足使用條件下,建議使用隊列
?
創建一個“隊列”對象?
pageQueue = Queue(10)
?
將一個值放入隊列中
for page in range(1, 11):
? ?pageQueue.put(page)
?
將一個值從隊列中取出
pageQueue.get()
?
隊列Queue
Queue線程安全
?? ?queue是python中的標準庫,可以直接from queue import Queue引用;隊列是線程間最常用的交換數據的形式
?? ?創建一個“隊列”對象
?? ?隊列常用方法
?? ??? ?put()
?? ??? ?get(block)
?? ??? ?empty()
?? ??? ?full()
?? ??? ?qsize()
隊列鎖與線程鎖
import threading
from queue import Queue
dataQueue = Queue(100)
exitFlag = Falseclass MyThread(threading.Thread):def __init__(self,q):super().__init__()self.queue = qdef run(self):super().run()global exitFlagwhile True:if exitFlag:print('++++++++++++++++++++++++++exit')breaktry:print('------------------------',self.queue.get(False))self.queue.task_done()except:passdef main():for i in range(100):dataQueue.put(i)threads = []for i in range(5):thread = MyThread(dataQueue)threads.append(thread)thread.start()# 隊列鎖# dataQueue.join()global exitFlagexitFlag = Trueprint('exit ------------------------------------------------')# 線程鎖for t in threads:t.join()if __name__ == '__main__':main()
另一個實例 爬去讀書網站
import requests
from bs4 import BeautifulSoup
from queue import Queue
import threading
from threading import Lock
url = 'https://www.dushu.com/book/1175_%d.html'
task_queue = Queue(100)
parse_queue = Queue(100)
headers = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Cookie':'Hm_lvt_8008bbd51b8bc504162e1a61c3741a9d=1572418328; Hm_lpvt_8008bbd51b8bc504162e1a61c3741a9d=1572418390',
'Host':'www.dushu.com',
'Sec-Fetch-Mode':'navigate',
'Sec-Fetch-Site':'none',
'Sec-Fetch-User':'?1',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',}
# 解析線程退出的標記
exit_flag = False# 相當于線程池
class CrawlThread(threading.Thread):def __init__(self, q_task:Queue,q_parse:Queue) -> None:super().__init__()self.q_task = q_taskself.q_parse = q_parsedef run(self) -> None:super().run()self.spider()# 一直干活def spider(self):while True:if self.q_task.empty():print('+++++++爬蟲線程%s執行任務結束+++++++'%(threading.current_thread().getName()))breaktaskId = self.q_task.get()response = requests.get(url % (taskId), headers = headers)response.encoding = 'utf-8'html = response.textself.q_parse.put((html,taskId))self.q_task.task_done()print('------爬蟲線程:%s-----執行任務:%d-------'%(threading.current_thread().getName(),taskId))
# 專心爬蟲
def crawl():for i in range(1,101):task_queue.put(i)for i in range(5):t = CrawlThread(task_queue,parse_queue)t.start()class ParseThread(threading.Thread):def __init__(self,q_parse:Queue,lock:Lock,fp):super().__init__()self.q_parse = q_parseself.lock = lockself.fp = fpdef run(self):super().run()self.parse()def parse(self):while True:if exit_flag:print('-----------解析線程:%s完成任務退出------------'%(threading.current_thread().getName()))breaktry:html,taskId = self.q_parse.get(block=False)soup = BeautifulSoup(html,'lxml')books = soup.select('div[class="bookslist"] > ul > li')print('----------------',len(books))for book in books:self.lock.acquire()book_url = book.find('img').attrs['src']book_title = book.select('h3 a')[0]['title']book_author = book.select('p')[0].get_text()book_describe = book.select('p')[1].get_text()fp.write('%s\t%s\t%s\t%s\n'%(book_url,book_title,book_author,book_describe))self.lock.release()self.q_parse.task_done()print('**********解析線程:%s完成了第%d頁解析任務***********'%(threading.current_thread().getName(),taskId))except :pass
# 專心的負責網頁解析,保存
def parse(fp):lock = Lock()for i in range(5):t = ParseThread(parse_queue,lock,fp)t.start()
if __name__ == '__main__':crawl()fp = open('./book.txt','a',encoding='utf-8')parse(fp)# 隊列join:隊列中的任務必須結束,下面才會執行task_queue.join()parse_queue.join()fp.close()exit_flag = Trueprint('代碼執行到這里!!!!!!!!!!!!!!')多線程實現
?? ?讀書http://www.qwsy.com/shuku.aspx?&page=1
?? ?導包
?? ?定義變量
?? ?創建爬蟲線程并啟動
?? ??? ?爬蟲線程
?? ?創建解析線程并啟動
?? ??? ?解析線程
?? ??? ??? ?Queue.get(block = True/False)
?? ?join()鎖定線程,確保線程全部執行完畢
?? ?結束任務











)

![scan8[16+2*4]的內容](http://pic.xiahunao.cn/scan8[16+2*4]的內容)





