read_X()通常是pandas模塊下的,to_X()是dataframe的方法

CSV
讀取
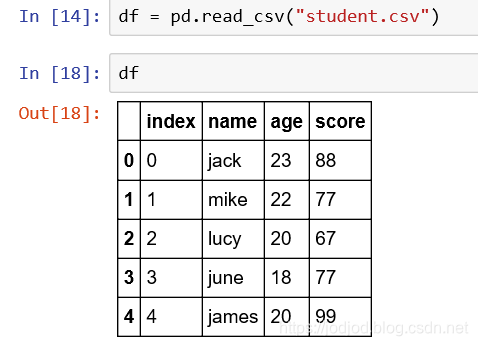
使用pandas.read_csv()方法,返回的是一個dataframe
csv默認是以","分割的
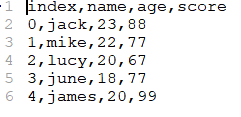
csv文件內容
1、read_csv()默認以第一行數據作為標題
2、調用dataframe的head()方法可以返回所有行數據,若傳入一個n,則返回前n行數據。默認n=5

也可以使用nrows參數截取,并且是在跳行的基礎上
![]()
?
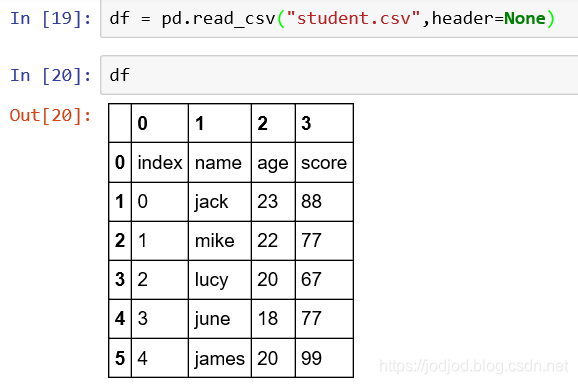
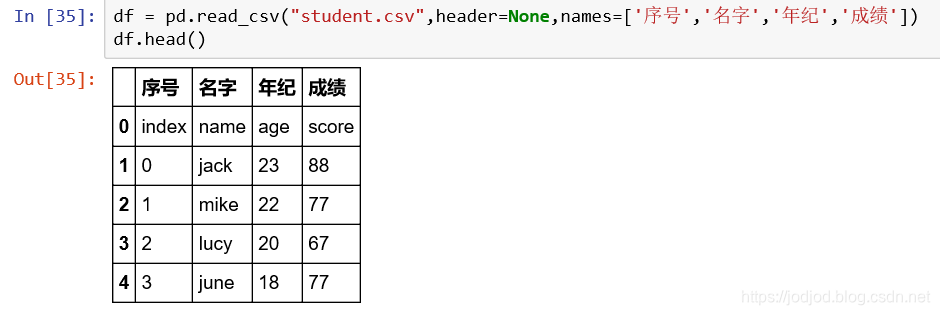
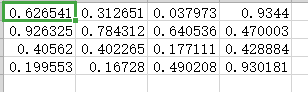
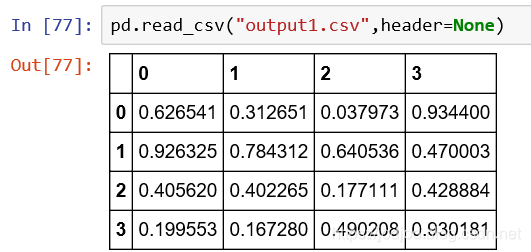
3、若不希望第一行作為標題,或者在read_csv()中添加參數header=None
4、自定義列名(標題)
在read_csv()中傳入參數names
5、跳行
上例中原標題也被讀取出來了,通過參數skiprows可以跳行

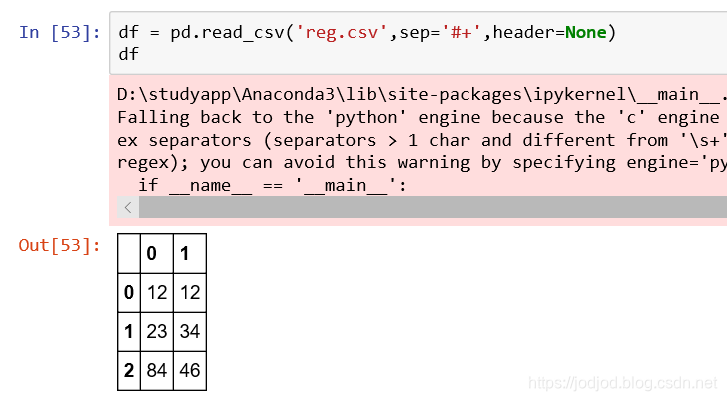
6、指定分隔符
通過sep參數,可以傳入正則表達式
比如有如下csv文件
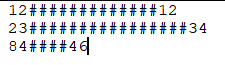
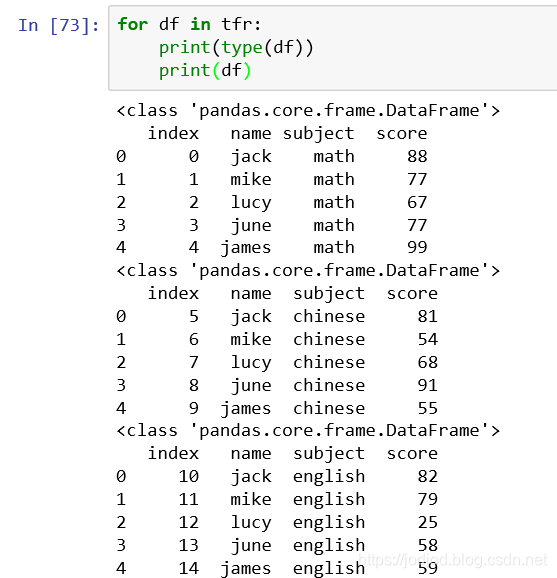
7、分塊處理大型文件
通過chunk參數可以指定每次處理的行數,返回類型為TextFileReader

TextFileReader由多個dataframe組成
寫入
1、將dataframe寫入csv,通過to_csv()方法
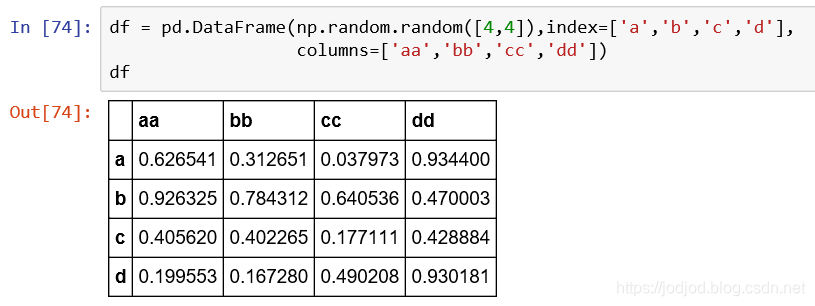
可以將header和index參數設置為False,不將列名和索引寫入

2、寫入NaN
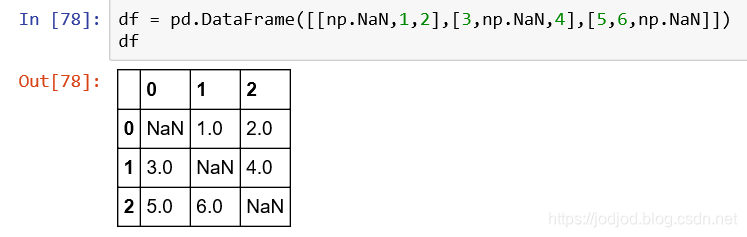
將具有NaN數據的dataframe寫入csv文件,此時NaN寫入文件為空


若想要指定NaN寫入的數據,通過na_rep參數指定


?
文本文件
讀取
對于csv文件,也可以通過讀取文本文件的方法來讀取
1、通過dataframe.read_table(),其中傳入參數sep分隔符
同樣有header和skiprows參數
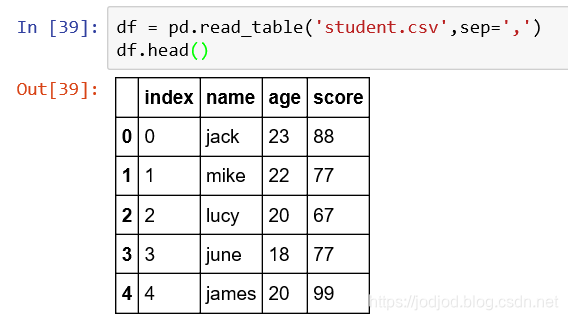
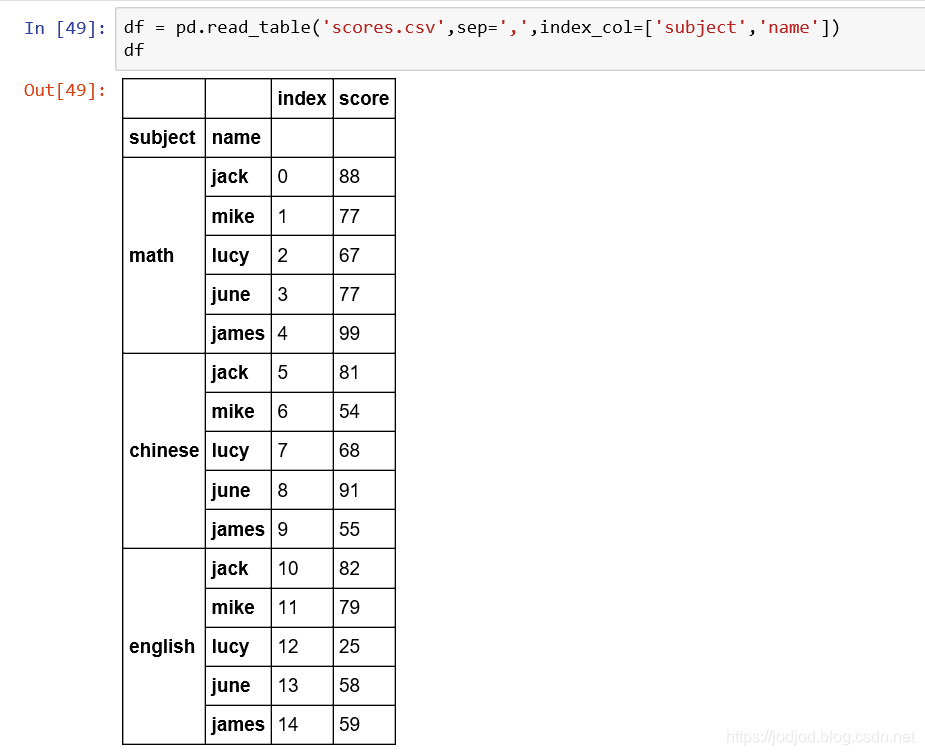
2、指定某列為索引
原文件:

通過屬性index_col()傳入指定列名
html
html的讀寫只針對于python中的dataframe和網頁中的表格
寫入
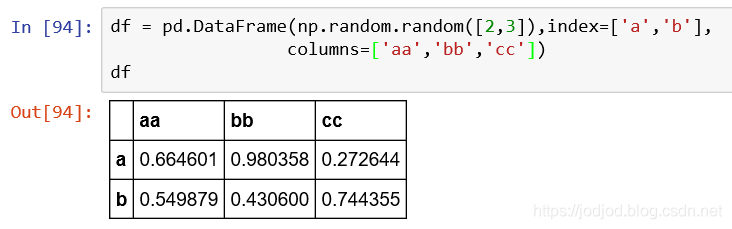
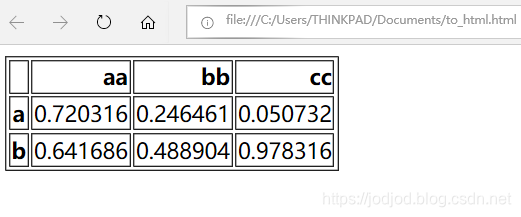
1、將dataframe轉化為html
可以通過dataframe.to_html()方法,返回的是表格的html代碼

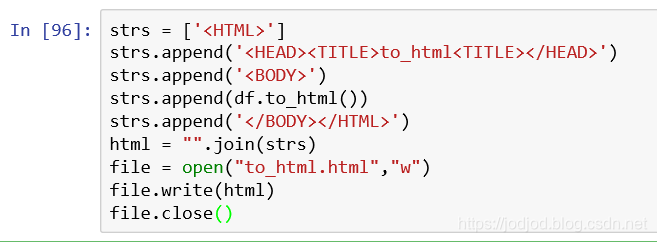
2、保存為html文件
將html代碼寫入html文件中,通過File.write()實現
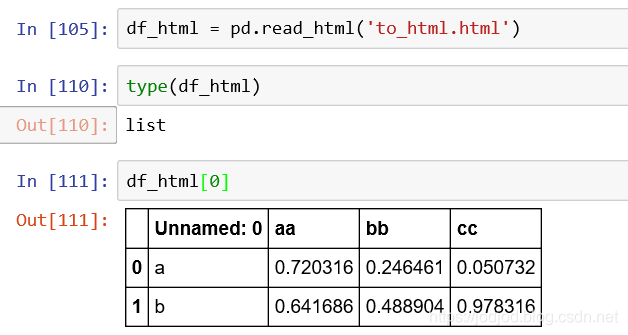
讀取
1、通過pandas.read_html()實現,返回一個dataframe的列表
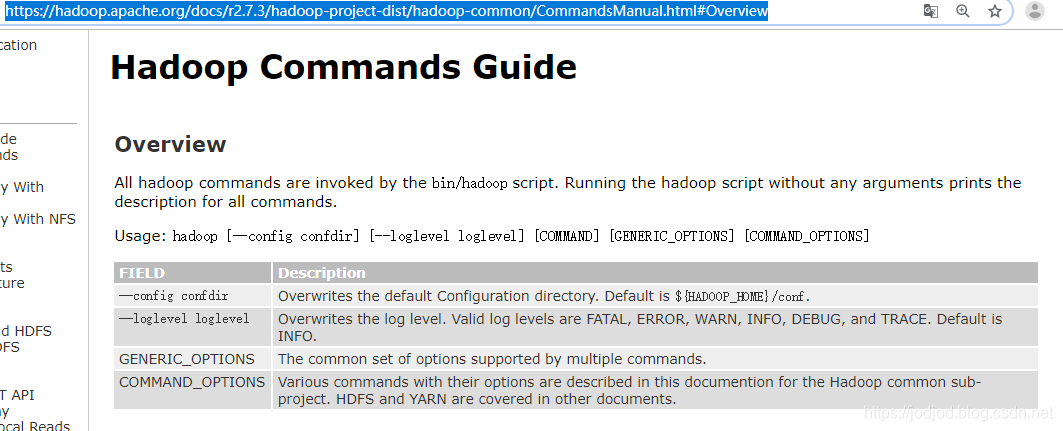
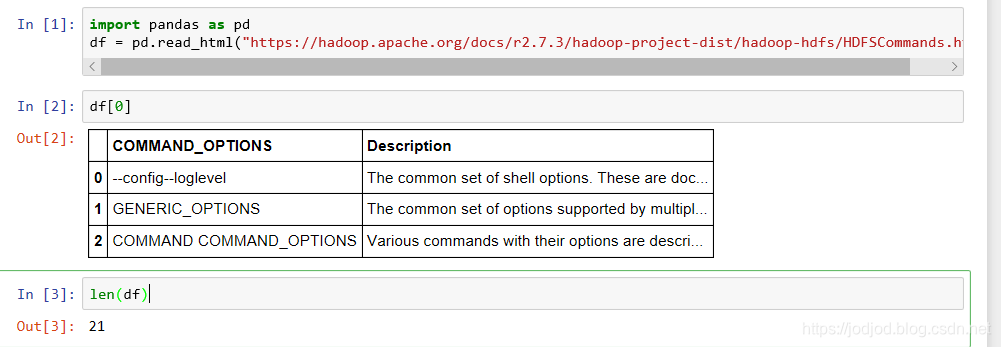
2、也可以讀取http網址
XML
讀取
pandas中沒有提供直接讀取xml文件的API,但可以借助lxml庫來讀取xml文件
當前有一個xml文件

通過lxml庫下的objectify.parse()可以解析xml文件,返回的是一個元素樹類型
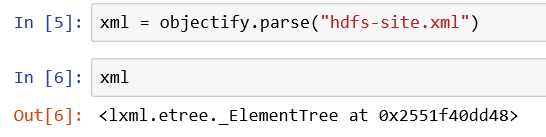
可以通過元素樹的getroot()方法獲取根,即最外一層的data。此時root類型名即為最外層標簽名

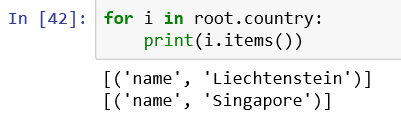
root下有student子標簽,student下有name,age,city子標簽。同樣標簽名即為類型名

root.student是一個由兩個元素的列表,通過items()可以獲取標簽中所有元素
如果只想獲取name的值,通過values()方法
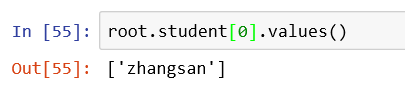
比如想要訪問lisi的age值

將xml轉化為dataframe
根據具體xml格式確定好索引和列

EXCEL
pandas支持.xls和.xlsx兩種類型的excel,通過to_excel和read_excel實現了寫和讀。pandas內部整合了xlrd模塊
讀取
1、當前有一個.xlsx文件,有2個sheet
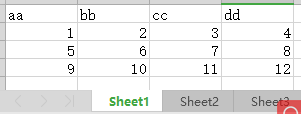

通過read_excel函數可以返回一個dataframe,默認讀取一個sheet

2、指定讀取的表格,傳入參數表名或者用索引表示

寫入
將dataframe通過to_excel()寫入到excel文件中,并可以指定表名


可見保存了索引和列名
JSON
通過read_json()和to_json()
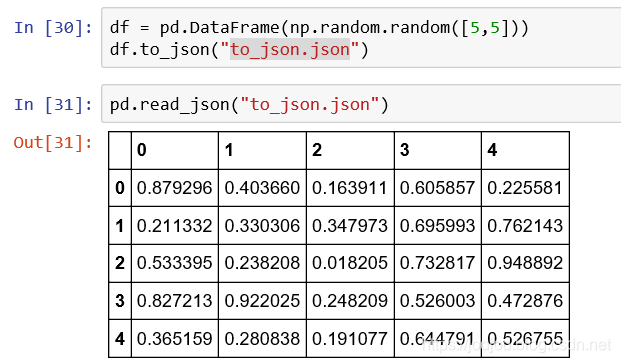
json類型中數據通過jason格式轉化可見,一列為一個字典

HDF5
HDF5是二進制文件格式的一種
python中需要用Pytable來處理HDF5格式的數據。pandas提供了一個叫HDFStore的類,類似于字典,用它來借助Pytable存儲dataframe對象。因此必須引入HDFStore,位于pandas.io.pytables內
寫入
首先聲明一個HDFStore對象,并創建HDF5文件,以.h5為后綴
![]()

向.h5文件中加入這個dataframe,key值自定義,value為df。并且HDFStore對象需要flush到文件中
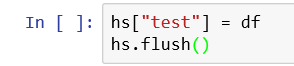
讀取
取出dataframe,因為HDFStore類似于字典

pickle對象序列化
pickle模塊或cPickle模塊使用的數據格式是python中特有的序列化格式,它是一種可讀的序列化方式,默認使用的ASCII表達式
序列化
首先需要引入pickle模塊,通過字典來裝載后調用pickle.dumps()方法實現序列化


寫入
通過to_pickle將dataframe寫入到.plk文件

?讀取

數據庫
pandas為操作數據庫提供了同一的接口sqlalchemy,連接數據庫使用create_engine函數,在這個函數中配置驅動器所需要的用戶名密碼端口和數據庫實例
各種數據庫的連接方法


SQLite
python內置了數據庫SQLite3,它的數據實際上是一個文件
寫入
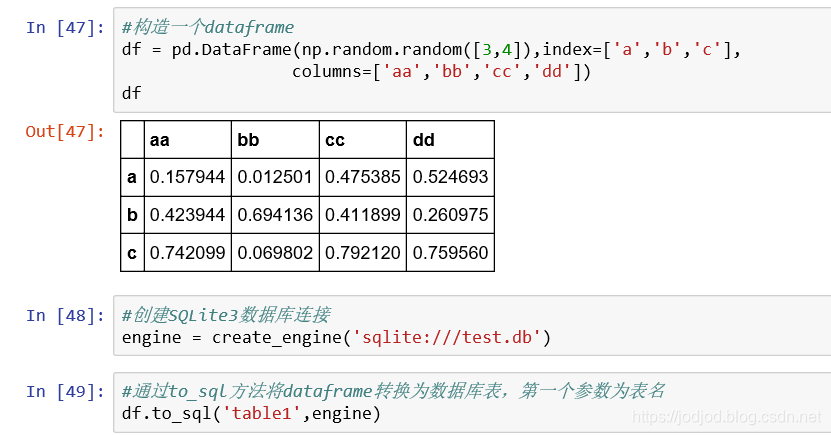
會在當前目錄下創建test.db文件
讀取
read_sql函數中第一個參數指定表名
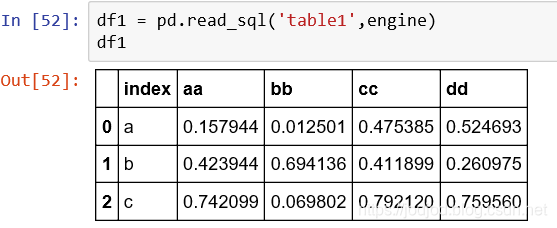
MySQL
創建連接,需安裝mysql-connector-python模塊,test為數據庫名
如果+mysqldb需要安裝mysql-python模塊

寫入
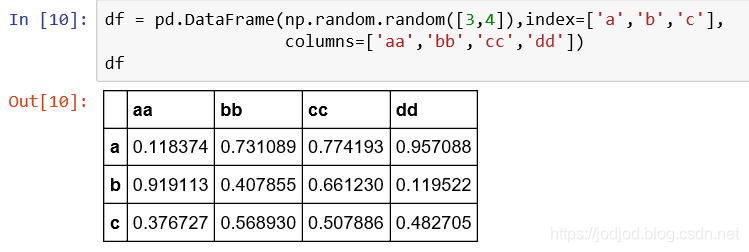

通過可視化軟件可以觀察到,index作為單獨的一列

讀取
1、讀取全表
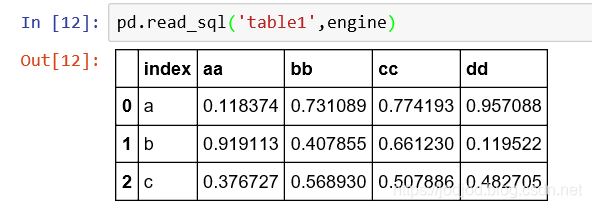
2、查詢讀取
通過read_sql_query函數可以傳入一個mysql查詢語句

?
















![[Grid Layout] Place grid items on a grid using grid-column and grid-row](http://pic.xiahunao.cn/[Grid Layout] Place grid items on a grid using grid-column and grid-row)
)

