計算機除了計算能力之外還有存儲能力,存儲能力即計算機擁有一系列的存儲介質,我們可以在存儲介質上存儲我們的代碼和數據。計算機體系結構中約定了哪些地方可以用來存儲數據:CPU內的寄存器、內存和外存。不同的存儲介質,容量、速度和價格都是不同的。為了建立一個合理的系統,我們將計算機系統中的存儲介質組織成一個層次結構。操作系統針對層次結構下的存儲單元進行管理。操作系統的存儲管理就是用來管理這些存儲介質的。最基本的管理要求就是當一個進程需要使用存儲單元的時候,操作系統能夠分一塊存儲介質給它使用,等它不用的時候還回給操作系統。
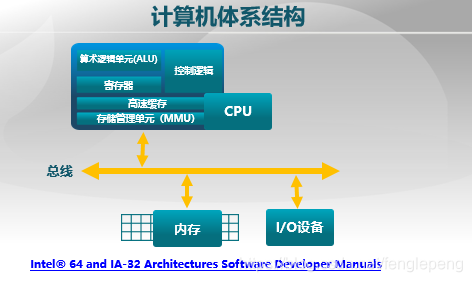
計算機體系結構:包括CPU、內存和I/O設備。
CPU中有寄存器和高速緩存。寄存器的空間是非常小的,可能是32位或64位,能存的詩句也就幾十字節或幾百字節。CPU中還有高速緩存,高速緩存僅次于CPU寄存器,處理速度接近CPU頻率,容量遠小于內存,速度遠快于內存,當CPU要讀取的數據存在于高速緩存時(命中),可以直接返回數據而不需要訪問內存,合理利用內存訪問的局部性特點,可以達到極高的命中率。內存也是比較大的能存儲數據的介質,他的最小訪問單位是字節,也就是8bit,通常我們的計算機系統是32位的總線,也就是說可以同時從內存中讀寫32位也就是4字節。一次讀寫32位時牽扯到地址對齊,因此讀寫時不能從任意地方開始讀一個4字節。
內存層次:
了解了上面這些,我們可以看下計算機中內存的層次關系:首先是處理器中有兩級緩存,這一部分內存管理是由硬件實現的,因此用戶或操作系統是無法顯示地進行控制的。再下面一層則是內存,內存再下面一層可以是外存中的虛擬內存,這兩個層次是由操作系統機型管理的。當CPU能層高速緩存中獲取所需讀取的內容無需訪問內存,能夠在內存中獲取的內容無需訪問虛擬內存,內存缺頁時才會從虛擬內存中讀取需要的內容。而這幾個層次上的內存的訪問速度是有這巨大差別的。最快的L1緩存可以達到接近CPU頻率的速度,內存可以達到1.3GHz,外存較慢需要5ms,可以看到最快和最慢能差到百萬數量級,如何將這幾個層次有機地結合到一起,挑戰性還是很大的。

內存管理:
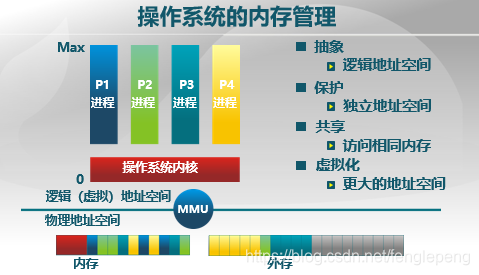
我們希望將內存管理做到什么程度呢?如下圖,系統中有不同的進程,進程通過操作系統內核訪問物理內存,訪問受內存管理單元(MMU)的控制。我們希望每個進程認為它自己獨占內存,因此進程能看到的是邏輯地址空間。MMU負責將邏輯地址空間映射到真實的物理地址空間。而這些都對內存管理提出了很高的要求,主要需要滿足如下幾條:
- 抽象,進程使用邏輯地址空間;
- 保護,由邏輯地址空間映射到物理地址空間時不同進程之間不能訪問到其他進程的內存;
- 共享,所用進程共用操作系統內核;
- 虛擬化,進程可以使用比實際內存空間更大的地址空間。
其中的保護性和共享性是相對矛盾的兩個要求,既要保護好各自的空間,又要訪問相同內存。甚至邏輯地址空間中看到的可以存儲數據的空間是大于實際物理內存的。
操作系統為了達到上述效果,具體采用的內存管理方式有以下幾條:
- 重定位。在最初的計算機中,是直接使用總線上的物理地址來編寫程序的,程序要讀寫某個內存單元,直接訪問它所在的物理地址。這有很大缺陷,你的程序只能在指定類型的機器上運行。重定位通過將進程中的邏輯地址加上重定位寄存器的值獲得物理地址。這樣通過修改重定位寄存器的值就可以將程序運行下去。為了實現,程序和操作系統里面都需要有相應的支持。
- 分段。實際我們在寫程序的時候,邏輯結構并不是必須連成一片的區域,而是把程序分為數據、代碼、堆棧。這三個部分是相對獨立的。這樣每一塊需要的空間就變少了。分段依然需要每一段內的內容是連續的,這個要求依然很高。
- 分頁。分頁就是把內存分成最基本的單位,選取合適的大小的連續區域作為一頁,一頁作為內存管理的基本單位。
- 虛擬存儲。目前多數系統(如Linux)采用按需頁式虛擬存儲。將不常用內容轉移到外存上存儲,這也使得邏輯地址空間可以大于實際物理內存空間。
上述4條內存管理方式的實現高度依賴硬件。比如與計算機存儲架構緊耦合;MMU的結構是什么樣的,CPU能夠識別的頁表是什么樣的,也就是MMU如何處理CPU存儲訪問請求的硬件。
地址空間
從邏輯地址到最后在總線上出現的物理地址,有一個轉換的過程,在學習具體的轉換算法之前,我們需要學習地址生成的過程。生成過程中并不是所有地址都允許訪問的,因此還需要對地址的合法性進行檢查。
地址空間定義:計算機地址空間有兩種,物理地址空間和邏輯地址空間。
- 物理地址空間就是硬件支持的真實地址空間,這是受硬件支持的,比如32位的系統,就是從0到4G-1的位置。
- 邏輯地址空間就是在CPU中運行的進程看到的地址,這個地址是從物理地址空間中分配的一段或幾段子空間。

地址生成及處理過程:
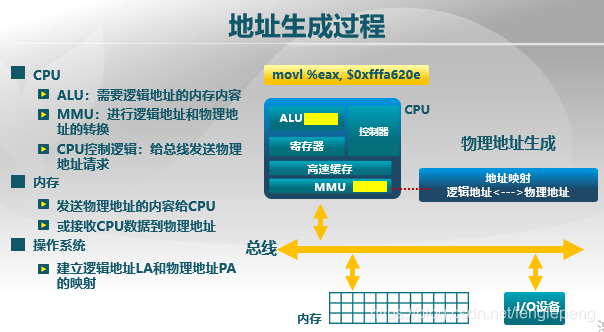
整體可以分為如下幾個步驟,ALU需要邏輯地址中的內容(讀或寫),MMU對邏輯地址進行轉換,轉換為物理地址,CPU控制邏輯給總線發送物理地址請求。內存發送物理地址的內容給CPU或者將CPU給的數據存儲到物理地址。操作系統做的是建立邏輯地址LA和物理地址PA之間的映射。
邏輯地址生成:
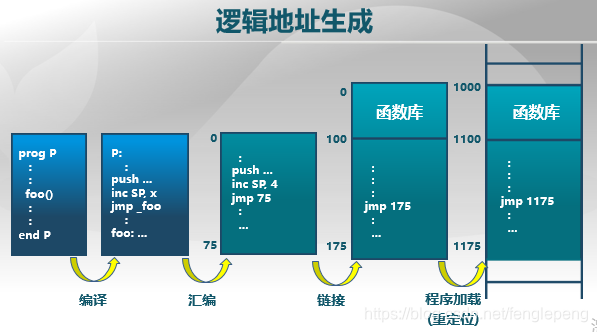
生成過程如下圖。比如最開始是高級語言寫了一段代碼,其中有一個函數foo();首先要進行編譯,編譯為機器能夠識別的匯編語言;之后進行匯編,將函數名從字符串變為地址75;而這個函數可能是某個函數庫中的成員,而函數庫的位置程序是不知道的,這就需要鏈接,將需要的文件拼接起來,此時可能在原先的代碼前面插入了一段代碼,比如地址偏移了100,此時函數地址變為了175;最后需要進行程序加載即重定位,因為這段程序不一定是從邏輯地址的0位開始的,比如是從1000開始的,那么函數地址成為1175。經歷了這么多步驟之后,生成的1175才是我們需要的邏輯地址。
那么邏輯地址是在什么時間生成的呢:
- 編譯時。假定起始地址已知,也就是我知道我的程序要放在哪,那么編譯時就可以生成邏輯地址。但是當起始地址改變時,比如修改了代碼,必須重新編譯。老舊的功能機買來之后不允許下載軟件,這種情況下地址通常就是寫死的。
- 加載時。當你修改了代碼或者安裝了各種新的軟件,寫程序時是無法知道新的代碼存儲在什么地址的。也就是編譯時起始位置未知時,編譯器需生成可重定位的代碼,等到加載時重定位,生成絕對地址。通常在可執行文件的前面有一個重定位表,加載的時候改成絕對地址,程序就可以跑了。
- 執行時。執行到這條指令之前一直使用相對地址,當執行到這一條指令的時候,才可以去知道它確切訪問的地址。這種情況出現在使用虛擬存儲的系統里。優點就是在程序執行過程中就可以將代碼移動,而前面兩種生成時機都不可以。但是需要地址轉化硬件支持,相對較麻煩。
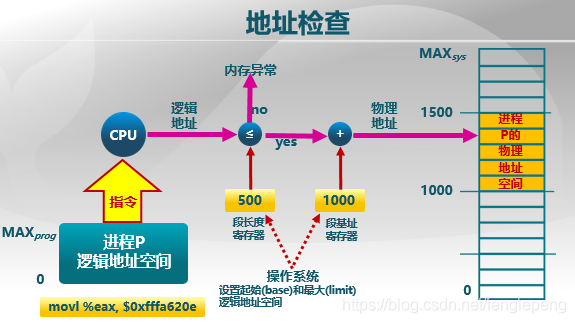
地址檢查
CPU執行到某條指令,得到它的邏輯地址,首先根據邏輯地址判斷所在它的偏移量是否在所在段(比如數據段)的長度之內,如果超出了段長度,認為是非法請求,否則認為是合法的。此時加上段基址得到物理地址,進行訪問。在這個過程中操作系統要做的就是設置段起始地址和最大邏輯地址空間(段長度)。

, 這部分都是angular)


:連續內存分配 內存碎片、動態分配、碎片整理、伙伴系統)




:非連續內存分配 段式、頁式、段頁式存儲管理)



:虛擬存儲、覆蓋、交換)

)

:置換算法)
)
