PDFMiner簡介
pdf提取目前的解決方案大致只有pyPDF和PDFMiner。據說PDFMiner更適合文本的解析,首先說明的是解析PDF是非常蛋疼的事,即使是PDFMiner對于格式不工整的PDF解析效果也不怎么樣,所以連PDFMiner的開發者都吐槽PDF is evil. 不過這些并不重要。
PDFMiner是一個可以從PDF文檔中提取信息的工具。與其他PDF相關的工具不同,它注重的完全是獲取和分析文本數據。PDFMiner允許你獲取某一頁中文本的準確位置和一些諸如字體、行數的信息。它包括一個PDF轉換器,可以把PDF文件轉換成HTML等格式。它還有一個擴展的PDF解析器,可以用于除文本分析以外的其他用途。
PDFMiner內置兩個好用的工具:pdf2txt.py和dumppdf.py
- pdf2txt.py從PDF文件中提取所有文本內容。但不能識別畫成圖片的文本,這需要特征識別。對于加密的PDF你需要提供一個密碼才能解析,對于沒有提取權限的PDF文檔你得不到任何文本。
- dumppdf.py把PDF文件內容變成pseudo-XML格式。這個程序主要用于debug,但是它也可能用于提取一些有意義的內容(比如圖片)。
PDFMiner在python2中名為PDFMiner,在python3中名為PDFMiner3k,分別上鏈接
PDFMiner? 官方主頁:https://euske.github.io/pdfminer/
PDFMiner? github主頁:https://github.com/euske/pdfminerpdfminer3k? 官方主頁:https://pypi.org/project/pdfminer3k/
pdfminer3k? github主頁:https://github.com/jaepil/pdfminer3k
解析pdf文件用到的類:
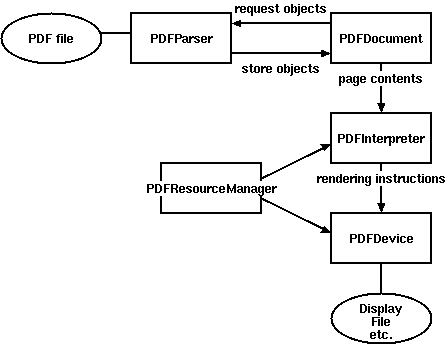
- PDFParser:PDF文檔分析器:從一個文件中獲取數據
- PDFDocument:PDF文檔對象:保存獲取的數據,和PDFParser是相互關聯的
- PDFPageInterpreter:PDF文檔解析器:處理頁面內容,變成Python可以解析
- PDFResourceManager:PDF資源管理器:用于存儲共享資源,如字體或圖像。
- PDFDevice: 將其翻譯成你需要的格式
- LAParams:PDF參數分析器:分析pdf文件參數
- PDFPageAggregator:PDF聚合器:讀取獲取的文檔對象
他們之間的關系圖如下:
?
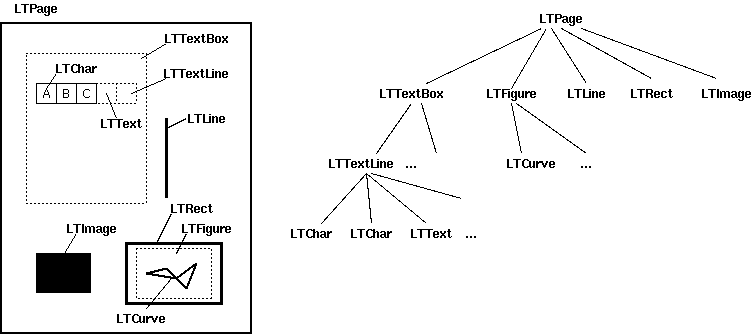
布局分析返回的PDF文檔中的每個頁面LTPage對象。這個對象和頁內包含的子對象,形成一個樹結構,如圖所示:
?
- LTPage :表示整個頁。可能會含有LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine子對象。
- LTTextBox:表示一組文本塊可能包含在一個矩形區域。注意此box是由幾何分析中創建,并且不一定
表示該文本的一個邏輯邊界。它包含LTTextLine對象的列表。使用 get_text()方法返回的文本內容。 - LTTextLine :包含表示單個文本行LTChar對象的列表。字符對齊要么??水平或垂直,取決于文本的寫入模式。
get_text()方法返回的文本內容。 - LTChar
- LTAnno:在文本中實際的字母表示為Unicode字符串(?)。需要注意的是,雖然一個LTChar對象具有實際邊界,
LTAnno對象沒有,因為這些是“虛擬”的字符,根據兩個字符間的關系(例如,一個空格)由布局分析后插入。 - LTImage:表示一個圖像對象。嵌入式圖像可以是JPEG或其它格式,但是目前PDFMiner沒有放置太多精力在圖形對象。
- LTLine:代表一條直線。可用于分離文本或附圖。
- LTRect:表示矩形。可用于框架的另一圖片或數字。
LTCurve:表示一個通用的Bezier曲線
一個簡單的示例
# encoding: utf-8
import sys
import importlib
importlib.reload(sys)
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowedpath ="C:\\Users\\admin\\Desktop\\t.pdf"
def parse():fp = open(path, 'rb') #用文件對象來創建一個pdf文檔分析器PDFParserpraser = PDFParser(fp)# 創建一個PDF文檔PDFDocumentdoc = PDFDocument()# 連接分析器 與文檔對象praser.set_document(doc)doc.set_parser(praser)# 提供初始化密碼,如果沒有密碼 就創建一個空的字符串doc.initialize()# 檢測文檔是否提供txt轉換,不提供就忽略if not doc.is_extractable:raise PDFTextExtractionNotAllowedelse:# 創建PDf 資源管理器 來管理共享資源PDFResourceManagerrsrcmgr = PDFResourceManager()# 創建一個PDF設備對象LAParamslaparams = LAParams()# 創建聚合器,用于讀取文檔的對象PDFPageAggregatordevice = PDFPageAggregator(rsrcmgr, laparams=laparams)# 創建一個PDF解釋器對象,對文檔編碼,解釋成Python能夠識別的格式:PDFPageInterpreterinterpreter = PDFPageInterpreter(rsrcmgr, device)# 循環遍歷列表,每次處理一個page的內容for page in doc.get_pages(): # doc.get_pages() 獲取page列表# 利用解釋器的process_page()方法解析讀取單獨頁數interpreter.process_page(page)# 這里layout是一個LTPage對象,里面存放著這個page解析出的各種對象,一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal等等,想要獲取文本就獲得對象的text屬性,# 使用聚合器get_result()方法獲取頁面內容layout = device.get_result()for x in layout:if (isinstance(x, LTTextBoxHorizontal)):#需要寫出編碼格式with open(r'C:\Users\admin\Desktop\1.txt', 'a',encoding='utf-8') as f:results = x.get_text()f.write(results + '\n')if __name__ == '__main__':parse()或者使用官方的一個例子,簡單寫如下
rsrcmgr = PDFResourceManager(caching=caching) # 創建一個PDF資源管理器對象來存儲共賞資源
outfp = io.open(outfile, 'wt', encoding=codec, errors='ignore') #指定outfile
device = XMLConverter(rsrcmgr, outfp, laparams=laparams, outdir=outdir)
fp = io.open(file, 'rb') #來創建一個pdf文檔分析器
process_pdf(rsrcmgr, device, fp, pagenos, maxpages=maxpages, password=password, caching=caching, check_extractable=True) #調用process_pdf
fp.close()
device.close()
outfp.close()參考鏈接: https://blog.csdn.net/liuqingpeng_1/article/details/79560753 https://www.zhangshengrong.com/p/Z9a2AAy1Vk/ https://blog.csdn.net/qq_29750461/article/details/80011255 https://blog.csdn.net/sinat_37967865/article/details/80145487
















)


