Consumer 需要向 Kafka 匯報自己的位移數據,這個匯報過程被稱為提交位移(Committing Offsets)。因為 Consumer 能夠同時消費多個分區的數據,所以位移的提交實際上是在分區粒度上進行的,即 Consumer 需要為分配給它的每個分區提交各自的位移數據。
提交位移主要是為了表征 Consumer 的消費進度,這樣當 Consumer 發生故障重啟之后,就能夠從 Kafka 中讀取之前提交的位移值,然后從相應的位移處繼續消費,從而避免整個消費過程重來一遍。
從用戶的角度來說,位移提交分為自動提交和手動提交;從 Consumer 端的角度來說,位移提交分為同步提交和異步提交。
自動提交
自動提交默認全部為同步提交
自動提交相關參數
- enable.auto.commit (bool) – 如果為True,將自動定時提交消費者offset。默認為True。
- auto.commit.interval.ms(int) – 自動提交offset之間的間隔毫秒數。如果enable_auto_commit 為true,默認值為: 5000。
當設置?enable.auto.commit 為 true,Kafka 會保證在開始調用 poll 方法時,提交上次 poll 返回的所有消息。從順序上來說,poll 方法的邏輯是先提交上一批消息的位移,再處理下一批消息,因此它能保證不出現消費丟失的情況。
網上有說
自動提交位移的一個問題在于,它可能會出現重復消費。
如果設置?enable.auto.commit 為 true,Consumer 按照?auto.commit.interval.ms設置的值(默認5秒)自動提交一次位移。我們假設提交位移之后的 3 秒發生了 Rebalance 操作。在 Rebalance 之后,所有 Consumer 從上一次提交的位移處繼續消費,但該位移已經是 3 秒前的位移數據了,故在 Rebalance 發生前 3 秒消費的所有數據都要重新再消費一次。雖然你能夠通過減少?auto.commit.interval.ms?的值來提高提交頻率,但這么做只能縮小重復消費的時間窗口,不可能完全消除它。這是自動提交機制的一個缺陷。
在實際測試中,未發現上述情況(kafka 版本 2.13), 而是會等待所有消費者消費完當前消息,或者等待消費者超時(等待過程中會報如下 warning), 之后才會 reblance。
手動提交
手動提交可以自己選擇是同步提交(commitSync)還是異步提交(commitAsync )
commitAsync 不能夠替代 commitSync。commitAsync 的問題在于,出現問題時它不會自動重試。因為它是異步操作,倘若提交失敗后自動重試,那么它重試時提交的位移值可能早已經“過期”或不是最新值了。因此,異步提交的重試其實沒有意義,所以 commitAsync 是不會重試的。
手動提交,我們需要將 commitSync 和 commitAsync 組合使用才能到達最理想的效果,原因有兩個:
- 我們可以利用 commitSync 的自動重試來規避那些瞬時錯誤,比如網絡的瞬時抖動,Broker 端 GC 等。因為這些問題都是短暫的,自動重試通常都會成功,因此,我們不想自己重試,而是希望 Kafka Consumer 幫我們做這件事。我們不希望程序總處于阻塞狀態,影響 TPS。
- 我們不希望程序總處于阻塞狀態,影響 TPS。
同時使用?commitSync() 和 commitAsync()
對于常規性、階段性的手動提交,我們調用 commitAsync() 避免程序阻塞,而在 Consumer 要關閉前,我們調用 commitSync() 方法執行同步阻塞式的位移提交,以確保 Consumer 關閉前能夠保存正確的位移數據。將兩者結合后,我們既實現了異步無阻塞式的位移管理,也確保了 Consumer 位移的正確性.
手動提交和自動提交中的 reblance 問題
- 如果設置為手動提交,當集群滿足?reblance 的條件時,集群會直接 reblance,不會等待所有消息被消費完,這會導致所有未被確認的消息會重新被消費,會出現重復消費的問題
- 如果設置為自動提交,當集群滿足?reblance 的條件時,集群不會馬上 reblance,而是會等待所有消費者消費完當前消息,或者等待消費者超時(等待過程中會報如下 warning), 之后才會 reblance。
python kafka-python 輸出信息如下:
[WARNING]Heartbeat failed for group scan_result because it is rebalancing
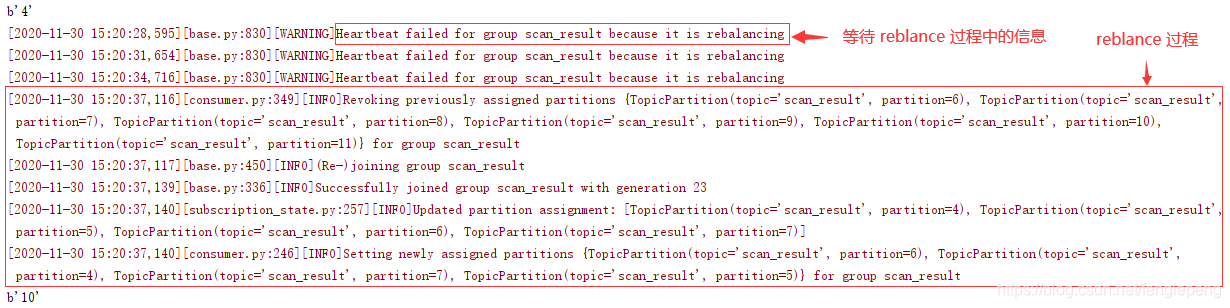
?kafka 中加入消費者時,kafka 會輸出如下信息




)
 。_學小易找答案...)







)
)

(Actor)/業務主角(BusinessActor)/業務工人(BusinessWorker)/用戶/角色辨析【圖解】...)



