騰訊課堂 |?Python網絡爬蟲與文本分析
TidyTextPy
前天我分享了?tidytext | 耳目一新的R-style文本分析庫?
但是tidytext不夠完善,我在tidytext基礎上增加了情感詞典,可以進行情感計算,為了區別前者,將其命名為tidytextpy。
大家有時間又有興趣,可以多接觸下R語言,在文本分析及可視化方面,R的能力也不弱。
安裝
pip?install?tidytextpy
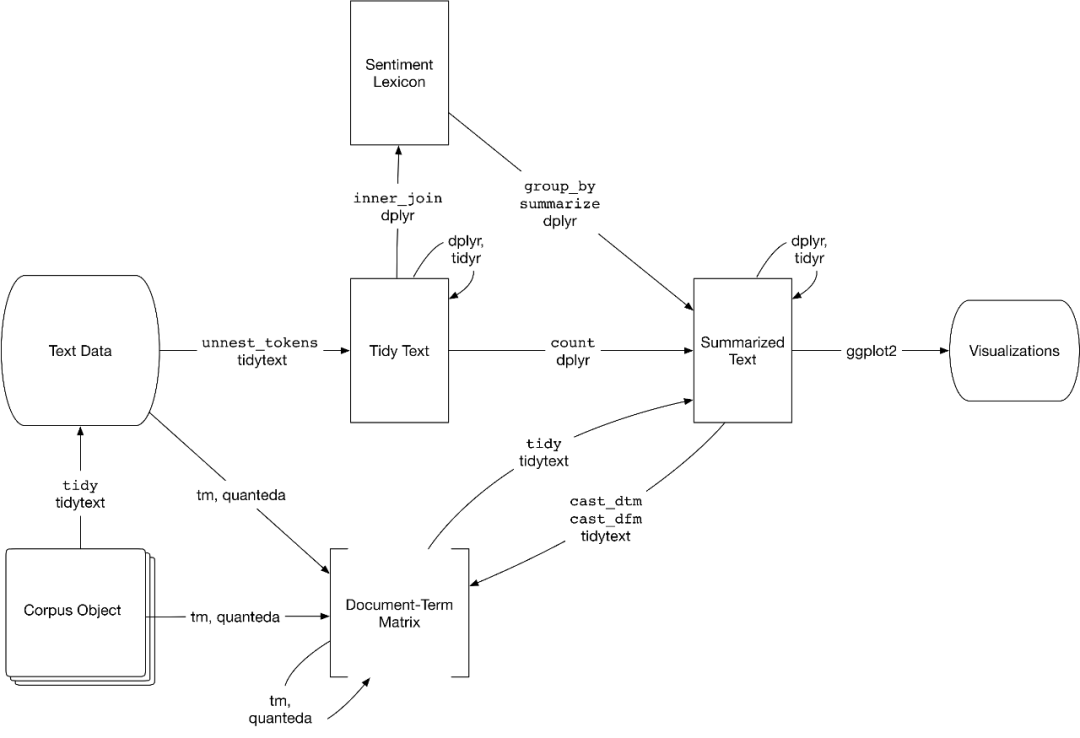
實驗數據
這里使用中文科幻小說《三體》為例子,含注釋共213章,使用正則表達式構建三體小說數據集,該數據集涵
- chapterid 第幾章
- title 章(節)標題
- text 每章節的文本內容(分詞后以空格間隔的文本,形態類似英文)
import?pandas?as?pd
import?jieba
import?re
pd.set_option('display.max_rows',?6)
raw_texts?=?open('三體.txt',?encoding='utf-8').read()
texts?=?re.split('第\d+章',?raw_texts)
texts?=?[text?for?text?in?texts?if?text]
#中文多了下面一行代碼(構造用空格間隔的字符串)
texts?=?['?'.join(jieba.lcut(text))?for?text?in?texts?if?text]
titles?=?re.findall('第\d+章?(.*?)\n',?raw_texts)
data?=?{'chapterid':?list(range(1,?len(titles)+1)),
????????'title':?titles,
????????'text':?texts}
df?=?pd.DataFrame(data)
df

tidytextpy庫
- get_stopwords 停用詞表
- get_sentiments 情感詞典
- unnest_tokens 分詞函數
- bind_tf_idf 計算tf-idf
停用詞表
get_stopwords(language) 獲取對應語言的停用詞表,目前僅支持chinese和english兩種語言
from?tidytextpy?import?get_stopwords
cn_stps?=?get_stopwords('chinese')
#前20個中文的停用詞
cn_stps[:20]
['、',
'。',
'〈',
'〉',
'《',
'》',
'一',
'一些',
'一何',
'一切',
'一則',
'一方面',
'一旦',
'一來',
'一樣',
'一般',
'一轉眼',
'七',
'萬一',
'三']
en_stps?=?get_stopwords()
#前20個英文文的停用詞
en_stps[:20]
['i',
'me',
'my',
'myself',
'we',
'our',
'ours',
'ourselves',
'you',
'your',
'yours',
'yourself',
'yourselves',
'he',
'him',
'his',
'himself',
'she',
'her',
'hers']
情感詞典
get_sentiments('詞典名') 調用詞典,返回詞典的dataframe數據。
- afinn sentiment取值-5到5
- bing sentiment取值為positive或negative
- nrc sentiment取值為positive或negative,及細粒度的情緒分類信息
- dutir sentiment為中文七種情緒類別(細粒度情緒分類信息)
- hownet sentiment為positive或negative
其中hownet和dutir為中文情感詞典
from?tidytextpy?import?get_sentiments
#大連理工大學情感本體庫,共七種情緒(sentiment)
get_sentiments('dutir')
| sentiment | word | |
|---|---|---|
| 0 | 驚 | 冷不防 |
| 1 | 驚 | 驚動 |
| 2 | 驚 | 珍聞 |
| ... | ... | ... |
| 27411 | 懼 | 匆猝 |
| 27412 | 懼 | 憂心仲忡 |
| 27413 | 懼 | 面面廝覷 |
27414 rows × 2 columns
get_sentiments('nrc')
| word | sentiment | |
|---|---|---|
| 0 | abacus | trust |
| 1 | abandon | fear |
| 2 | abandon | negative |
| ... | ... | ... |
| 13898 | zest | positive |
| 13899 | zest | trust |
| 13900 | zip | negative |
13901 rows × 2 columns
分詞
unnest_tokens(__data, output, input)
__data待處理的dataframe數據- output 新生成的dataframe中,用于存儲分詞結果的字段名
- input 待分詞數據的字段名(待處理的dataframe數據)
from?tidytextpy?import?unnest_tokens
tokens?=?unnest_tokens(df,?output='word',?input='text')
tokens
| chapterid | title | word | |
|---|---|---|---|
| 0 | 1 | 科學邊界(1) | 科學 |
| 0 | 1 | 科學邊界(1) | 邊界 |
| 0 | 1 | 科學邊界(1) | 1 |
| ... | ... | ... | ... |
| 212 | 213 | 注釋 | 想到 |
| 212 | 213 | 注釋 | 暗物質 |
| 212 | 213 | 注釋 | 。 |
556595 rows × 3 columns
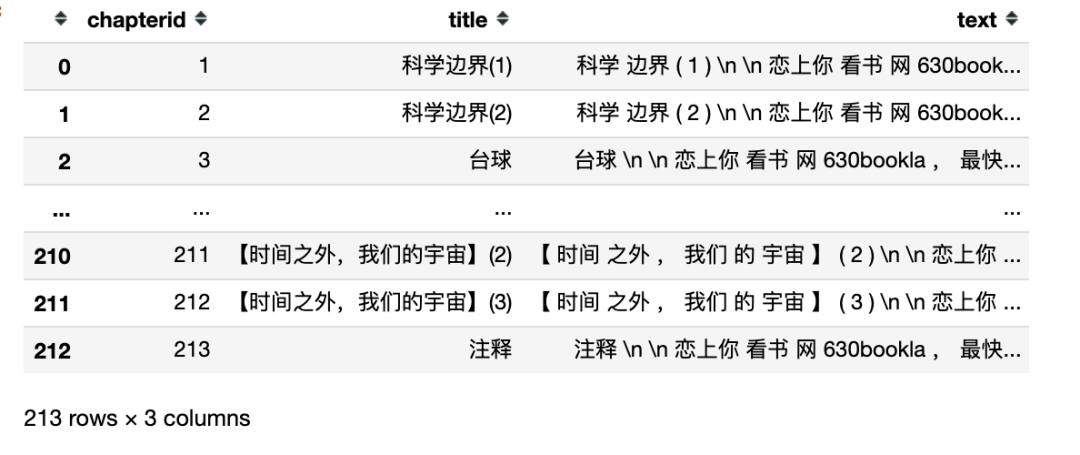
各章節用詞量
從這里開始會用到plydata的管道符>> 和相關的常用函數,建議大家遇到不懂的地方查閱plydata文檔
from?plydata?import?count,?group_by,?ungroup
wordfreq?=?(df?
????????????>>?unnest_tokens(output='word',?input='text')?#分詞
????????????>>?group_by('chapterid')??#按章節分組
????????????>>?count()?#對每章用詞量進行統計
????????????>>?ungroup()?#去除分組
???????????)
wordfreq
| chapterid | n | |
|---|---|---|
| 0 | 1 | 2549 |
| 1 | 2 | 2666 |
| 2 | 3 | 1726 |
| ... | ... | ... |
| 210 | 211 | 2505 |
| 211 | 212 | 2646 |
| 212 | 213 | 2477 |
213 rows × 2 columns
章節用詞量可視化
使用plotnine進行可視化
from?plotnine?import?ggplot,?aes,?theme,?geom_line,?labs,?theme,?element_text
from?plotnine.options?import?figure_size
(ggplot(wordfreq,?aes(x='chapterid',?y='n'))+
?geom_line()+
?labs(title='三體章節用詞量折線圖',
??????x='章節',?
??????y='用詞量')+
?theme(figure_size=(12,?8),
???????title=element_text(family='Kai',?size=15),?
???????axis_text_x=element_text(family='Kai'),
???????axis_text_y=element_text(family='Kai'))
)
情感分析
重要的事情多重復一遍o( ̄︶ ̄)o
get_sentiments('詞典名') 調用詞典,返回詞典的dataframe數據。
- afinn sentiment取值-5到5
- bing sentiment取值為positive或negative
- nrc sentiment取值為positive或negative,及細粒度的情緒分類信息
- dutir sentiment為中文七種情緒類別(細粒度情緒分類信息)
- hownet sentiment為positive或negative
其中hownet和dutir為中文情感詞典
情感計算
這里會用到plydata的很多知識點,大家可以查看https://plydata.readthedocs.io/en/latest/index.html 相關函數的文檔。

from?plydata?import?inner_join,?count,?define,?call
from?plydata.tidy?import?spread
chapter_sentiment_score?=?(
????df?#分詞
????>>?unnest_tokens(output='word',?input='text')?
????>>?inner_join(get_sentiments('hownet'))?#讓分詞結果與hownet詞表交集,給每個詞分配sentiment
????>>?count('chapterid',?'sentiment')#統計每章中每類sentiment的個數
????>>?spread('sentiment',?'n')?#將sentiment中的positive和negative轉化為兩列
????>>?call('.fillna',?0)?#將缺失值替換為0
????>>?define(score?=?'(positive-negative)/(positive+negative)')?#計算每一章的情感分score
)
chapter_sentiment_score
| chapterid | negative | positive | score | |
|---|---|---|---|---|
| 0 | 1 | 93.0 | 56.0 | -0.248322 |
| 1 | 2 | 98.0 | 83.0 | -0.082873 |
| 2 | 3 | 54.0 | 37.0 | -0.186813 |
| ... | ... | ... | ... | ... |
| 210 | 211 | 56.0 | 73.0 | 0.131783 |
| 211 | 212 | 71.0 | 67.0 | -0.028986 |
| 212 | 213 | 75.0 | 74.0 | -0.006711 |
213 rows × 4 columns
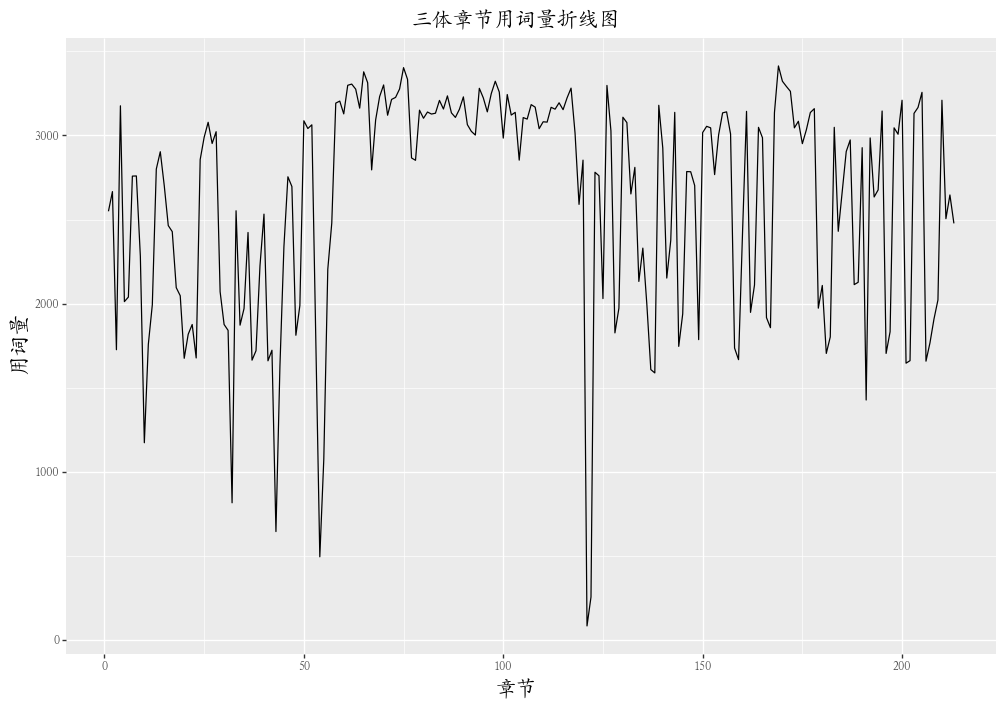
三體小說情感走勢
我記得看完《三體》后,很悲觀,覺得人類似乎永遠逃不過宇宙的時空規律,心情十分壓抑。如果對照小說進行章節的情感分析,應該整體情感分的走勢大多在0以下。
from?plotnine?import?ggplot,?aes,?geom_line,?element_text,?labs,?theme
(ggplot(chapter_sentiment_score,?aes('chapterid',?'score'))+
?geom_line()+
?labs(x='章節',?y='情感值score',?title='《三體》小說情感走勢圖')+
?theme(title=element_text(family='Kai'))
)
tf-idf
相比之前的代碼,bind_tf_idf運行起來很慢很慢,《三體》數據量大,所以這里用別的數據做實驗。
tf-idf實驗數據
import?pandas?as?pd
pd.set_option('display.max_rows',?6)
zen?=?"""
The?Zen?of?Python,?by?Tim?Peters
Beautiful?is?better?than?ugly.
Explicit?is?better?than?implicit.
Simple?is?better?than?complex.
Complex?is?better?than?complicated.
Flat?is?better?than?nested.
Sparse?is?better?than?dense.
Readability?counts.
Special?cases?aren't?special?enough?to?break?the?rules.
Although?practicality?beats?purity.
Errors?should?never?pass?silently.
Unless?explicitly?silenced.
In?the?face?of?ambiguity,?refuse?the?temptation?to?guess.
There?should?be?one--?and?preferably?only?one?--obvious?way?to?do?it.
Although?that?way?may?not?be?obvious?at?first?unless?you're?Dutch.
Now?is?better?than?never.
Although?never?is?often?better?than?*right*?now.
If?the?implementation?is?hard?to?explain,?it's?a?bad?idea.
If?the?implementation?is?easy?to?explain,?it?may?be?a?good?idea.
Namespaces?are?one?honking?great?idea?--?let's?do?more?of?those!
"""
zen_split?=?zen.splitlines()
df?=?pd.DataFrame({'docid':?list(range(len(zen_split))),
??????????????????'text':?zen_split})
df
| docid | text | |
|---|---|---|
| 0 | 0 | |
| 1 | 1 | The Zen of Python, by Tim Peters |
| 2 | 2 | |
| ... | ... | ... |
| 19 | 19 | If the implementation is hard to explain, it's... |
| 20 | 20 | If the implementation is easy to explain, it m... |
| 21 | 21 | Namespaces are one honking great idea -- let's... |
22 rows × 2 columns
bind_tf_idf
tf表示詞頻,idf表示詞語在文本中的稀缺性,兩者的結合體現了一個詞的信息量。找出小說中tf-idf最大的詞。
bind_tf_idf(_data, term, document, n)
_data傳入的df- term df中詞語對應的字段名
- document df中文檔id的字段名
- n df中詞頻數對應的字段名
from?tidytextpy?import?bind_tf_idf
from?plydata?import?count,?group_by,?ungroup
tfidfs?=?(df
??????????>>?unnest_tokens(output='word',?input='text')
??????????>>?count('docid',?'word')
??????????>>?bind_tf_idf(term='word',?document='docid',?n='n')
?????????)
tfidfs
| docid | word | n | tf | idf | tf_idf | |
|---|---|---|---|---|---|---|
| 0 | 1 | the | 1 | 0.142857 | 1.386294 | 0.198042 |
| 1 | 1 | zen | 1 | 0.142857 | 2.995732 | 0.427962 |
| 2 | 1 | of | 1 | 0.142857 | 1.897120 | 0.271017 |
| ... | ... | ... | ... | ... | ... | ... |
| 137 | 21 | more | 1 | 0.090909 | 2.995732 | 0.272339 |
| 138 | 21 | of | 1 | 0.090909 | 1.897120 | 0.172465 |
| 139 | 21 | those | 1 | 0.090909 | 2.995732 | 0.272339 |
140 rows × 6 columns
近期文章
[更新] Python網絡爬蟲與文本數據分析?tidytext | 耳目一新的R-style文本分析庫rpy2庫 | 在jupyter中調用R語言代碼plydata庫 | 數據操作管道操作符>>plotnine: Python版的ggplot2作圖庫七夕禮物 | 全網最火的釘子繞線圖制作教程讀完本文你就了解什么是文本分析文本分析在經管領域中的應用概述??綜述:文本分析在市場營銷研究中的應用plotnine: Python版的ggplot2作圖庫小案例: Pandas的apply方法??stylecloud:簡潔易用的詞云庫?用Python繪制近20年地方財政收入變遷史視頻??Wow~70G上市公司定期報告數據集漂亮~pandas可以無縫銜接Bokeh??YelpDaset: 酒店管理類數據集10+G??后臺回復關鍵詞【20200822】獲取本文代碼








)




)
 。_學小易找答案...)



