1.相關的數據類型
我們先看相關的數據類型:
HeapTupleData(src/include/access/htup.h)
typedef struct HeapTupleData
{uint32 t_len; /* length of *t_data */ItemPointerData t_self; /* SelfItemPointer */Oid t_tableOid; /* table the tuple came from */HeapTupleHeader t_data; /* -> tuple header and data */
} HeapTupleData;
HeapTupleHeaderData(src/include/access/htup_details.h)
struct HeapTupleHeaderData
{union{HeapTupleFields t_heap;DatumTupleFields t_datum;} t_choice;ItemPointerData t_ctid; /* current TID of this or newer tuple (or a* speculative insertion token) *//* Fields below here must match MinimalTupleData! */uint16 t_infomask2; /* number of attributes + various flags */uint16 t_infomask; /* various flag bits, see below */uint8 t_hoff; /* sizeof header incl. bitmap, padding *//* ^ - 23 bytes - ^ */bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs *//* MORE DATA FOLLOWS AT END OF STRUCT */
};t_choice具有2個成員的聯合類型:
1.t_heap 用于記錄對元組執行插入/刪除操作事物ID和命令ID,這些信息主要用于并發控制是檢查元組對事物的可見性
2.t_datum一個新的元組在內存中形成的時候,我們不關心事物的可見性,因此在t_choice中需要用DatumTupleFields結構來記錄元組的長度等信息,把內存的數據寫入到表文件的時候,需要在元組中記錄事物和命令ID,因此會把t_choice所占的內存轉換成HeapTupleFields結構并且填充響應數據后再進行元組的插入。
t_ctid用于記錄當前元組或者新元組的物理位置,塊號和塊內偏移量,例如(0,1)第一個塊內的第一個linp,若tuple被跟新,那么就記錄新版本的物理位置。
t_infomask2使用其低11位標識當前tuple的attribute的個數,其他位用于HOT以及tuple可見性的標志位
t_infomask用于標識tuple當前的狀態,比如是否有OID,是否空的字段,t_infomask每一位代表一種狀態,總共16種。
2.Tuple的構造
構造tuple的函數(src/backend/access/common/heaptuple.c)
HeapTuple
heap_form_tuple(TupleDesc tupleDescriptor,Datum *values,bool *isnull)該函數使用給定的values數組和isnull數組來組裝生成一個tuple。
該函數的主要流程是先計算整個tuple所需要的長度(這個長度是指tuple中除掉HeapTupleData結構以外的長度。事實上,該長度存儲在HeapTupleData的t_len的屬性中。)然后以此申請內存,最后根據values和isnull來填充tuple數據。
我們稍微說一下這個t_len的計算。
len = offsetof(HeapTupleHeaderData, t_bits);首先計算heaptupleheaderdata的長度,這個offsetof計算了從HeapTupleHeaderData的首址到它的成員變量t_bit的偏移量。
所以為什么不直接sizeof(HeapTupleHeaderData)呢?
原因是t_bits描述了NULL的bitmap關系,它的實際長度與列(屬性)個數有關,是一個可變的值,
因此,在計算完HeapTupleHeaderData長度的時候,我們便根據是否存在著null列,來計算相應的數據(如下)。
if (hasnull)len += BITMAPLEN(numberOfAttributes);以及是否有oid:
if (tupleDescriptor->tdhasoid)len += sizeof(Oid);再加上padding大小(涉及到C語言的數據對齊):
hoff = len = MAXALIGN(len); /* align user data safely */最后再獲取data的長度:
data_len = heap_compute_data_size(tupleDescriptor, values, isnull);len += data_len;獲取了tuple的長度申請好內存后,向里面添加數據,就獲得了如下的tuple(結構):
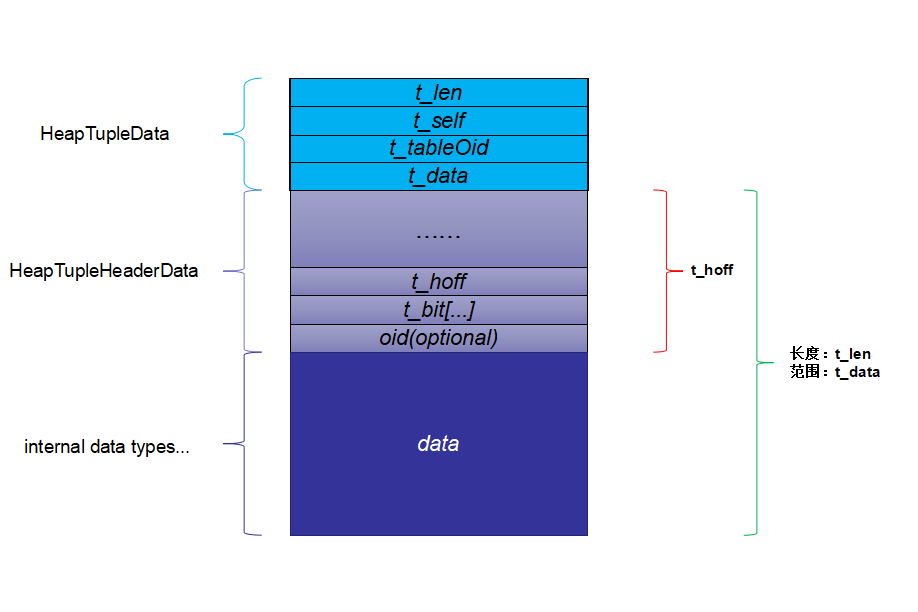
其中,hoff中包括了: 從TupleHeaderData起始位置到t_bits的位置;用戶數據是從t_hoff開始,加上t_bits的偏移,以及oid的偏移,開始真正存儲的。 這些由上圖可以得知。
heap_fill_tuple 函數中依據tupledesc中atts所提供的信息來保存數據到相應的位置。att[i]->attlen == -1 當為此種情況時候,表明其是varlen數據,例如varchar之類的數量類型,att[i]->attlen == -2 當為此種情況時候,為cstring,即字符串形式的數據。never needs alignment 無需進行對齊操作。否則,為固定長度的類型。
如果是varlen類型數據時候。還需要使用VARATT_IS_EXTERNAL來判定是否是存儲在外存上面。
做好了一條tuple之后,我們還要把它插入到數據庫對應的表中才算完事。
3.Tuple的插入
插入tuple到heap的函數
Oid
heap_insert(Relation relation, HeapTuple tup, CommandId cid,int options, BulkInsertState bistate)這個函數還挺復雜的,涉及到了內存和disk的數據交換。內存主要涉及到了緩沖區buffer和lock,對于disk涉及到了FSM映射表和Page。
首先,預處理函數設置元組頭部的字段,分配一個OID,并在必要時為元組提供Toast。請注意,在這里heaptup是傳進來的tuple,而變量tup是作為一個臨時變量存在的。
heaptup = heap_prepare_insert(relation, tup, xid, cid, options);我們要將元組插入到page,涉及到內存和disk的數據交換,這就要用到buffer。我們知道insert的本質也是先"select"再"insert"。也就是說我們先要找到該表上合適的Page來裝這個tuple。因此,我們為該Page申請一個buffer并加上執行鎖,將該Page載入申請到的buffer中。注意,此時要插入的tuple并未寫到buffer中。
buffer = RelationGetBufferForTuple(relation, heaptup->t_len,InvalidBuffer, options, bistate,&vmbuffer, NULL);這樣以后,所有的準備工作都做好了,就差臨門一腳了。成與不成就在一舉了。是不是聽起來有點。。。?
是的,我們要進入臨界區了,誰都不要打擾我:
START_CRIT_SECTION();這個語句其實是設置了全局變量CritSectionCount,就相當于信號量了,這里不多說。
然后我們開始寫數據吧:
RelationPutHeapTuple(relation, buffer, heaptup,(options & HEAP_INSERT_SPECULATIVE) != 0);但是話說,真的寫了?并沒有!你忘了我們postgresql有WAL么?你WAL log都還沒寫,數據怎么能先到磁盤?
那么這里我們有什么?我們buffer里面有Page,我們"手上"有tuple,好的,我們把tuple放到這個buffer裝的Page里面對應的位置上。
就是說,我們的數據還在buffer里。
那么怎么通知Postgres我有臟數據要寫啊?
MarkBufferDirty(buffer);設置buffer為臟,這樣Postgres在下次寫磁盤(checkpointer)的時候就知道把這個buffer里的數據丟回disk了。
那么,我們也就知道了,接下來我們就要開始準備WAL和數據了。
這里大致用到了這幾個函數:
XLogBeginInsert
XLogRegisterData
XLogRegisterBuffer
XLogRegisterBufData
PageSetLSN好的,WAL也設置好了。(只等插入這條tuple的命令commit之后,WAL數據立即落盤,寫到disk上,也就是pg_xlog目錄下的WAL段里面。)此時退出臨界區。
這個時候要放開buffer了。
最后我們再做一做清理工作,打完收工。
最最最后,實際的元組仍然在內存,不過沒事,因為你的查詢也是要先走buffer和cache的,所以你已經可以查詢到這條數據了。等到系統調用了checkpointer進程,你的數據才真正落了盤,然而,這對你是透明的。
這里關于數據落盤的先后順序和時機,我還是借網上的兩張圖吧:
WAL和data進入buffer的時機:
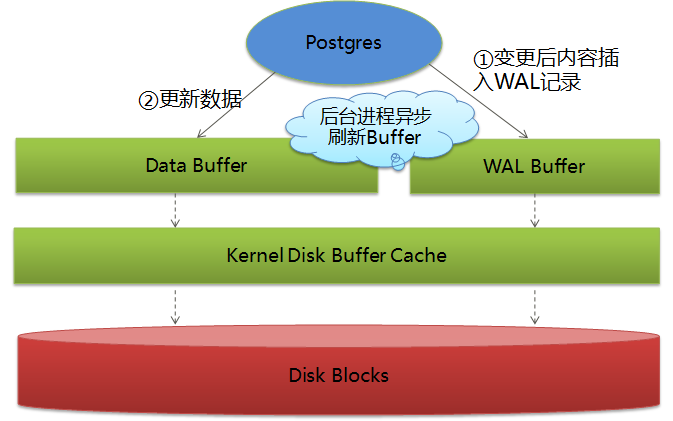
WAL和data寫到disk的時機: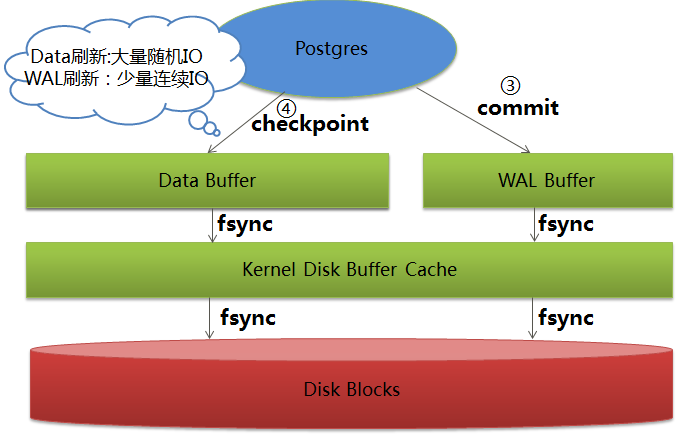
好的就是這樣~
恩,這次對WAL的插入的分析比較簡略,下次我弄清楚了再細說吧各位。
參考文章:
http://blog.jobbole.com/106585/
http://www.cnblogs.com/sangli/p/6404771.html
http://www.jianshu.com/p/a37ceed648a8






)
)

(Actor)/業務主角(BusinessActor)/業務工人(BusinessWorker)/用戶/角色辨析【圖解】...)









)