系統運維的過程中,每一個細節都值得我們關注
下圖為我們的基本日志處理架構
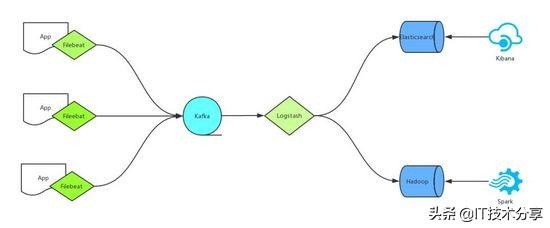
所有日志由Rsyslog或者Filebeat收集,然后傳輸給Kafka,Logstash作為Consumer消費Kafka里邊的數據,分別寫入Elasticsearch和Hadoop,最后使用Kibana輸出到web端供相關人員查看,或者是由Spark接手進入更深層次的分析。
在以上整個架構中,核心的幾個組件Kafka、Elasticsearch、Hadoop天生支持高可用,唯獨Logstash是不支持的,用單個Logstash去處理日志,不僅存在處理瓶頸更重要的是在整個系統中存在單點的問題,如果Logstash宕機則將會導致整個集群的不可用,后果可想而知
如何解決Logstash的單點問題呢?我們可以借助Kafka的Consumer Group來實現
Kafka Consumer Group
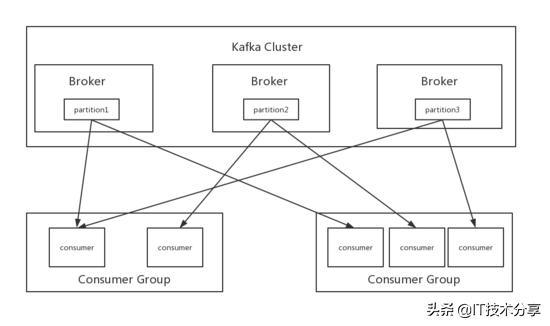
為了便于理解,我么先介紹一下Kafka里邊幾個重要的角色:
Broker:一臺kafka服務器就是一個broker,一個kafka集群由多個broker組成,上圖中的kafka集群有3臺kafka服務器組成,也就是有3個broker,一個broker上可以有多個topic。

Topic:是個邏輯上的概念,用來區分不同的消息類別,類似于數據庫中的表,可以將一組相同的數據發送給一個Topic,在日志處理中通常會將不同類型的日志寫入不同的Topic,例如nginx日志寫入名字為 nginx_log 的topic,tomcat日志寫入名字為 tomcat_log 的topic,topic上圖中沒有標出,我們可以理解為圖上的三個partition構成了一個topic

Partition:是kafka數據存儲的基本物理單元,同一個Topic的數據可以被存儲在一個或多個partition中,例如上圖中的一個topic數據被存儲在了partition1,partition2,partition3中,通常我們設置一個topic下partition的數量為broker的整數倍,這樣一來數據能夠均勻分布,二來可以同時利用集群下的所有服務器資源
Producer:生產者,向kafka寫數據的服務,例如filebeat
Consumer:消費者,去kafka取數據的服務,例如logstash
Consumer Group:也是個邏輯上的概念,為一組consumer的集合,同一個topic的數據會廣播給不同的group,同一個group中只有一個consumer能拿到這個數據
也就是說對于同一個topic, 每個group都可以拿到同樣的所有數據,但是數據進入group后只能被其中的一個consumer消費 ,基于這一點我們只需要啟動多個logstsh,并將這些logstash分配在同一個組里邊就可以實現logstash的高可用了
input { kafka { bootstrap_servers => "10.8.9.2:9092,10.8.9.3:9092,10.8.9.4:9092" topics => ["ops_coffee_cn"] group_id => "groupA" codec => "json" }}以上為logstash消費kafka集群的配置,其中加入了 group_id 參數, group_id 是一個的字符串,唯一標識一個group,具有相同 group_id 的consumer構成了一個consumer group,這樣啟動多個logstash進程,只需要保證 group_id 一致就能達到logstash高可用的目的,一個logstash掛掉同一Group內的logstash可以繼續消費
除了高可用外同一Group內的多個Logstash可以同時消費kafka內topic的數據,從而提高logstash的處理能力,但需要注意的是消費kafka數據時,每個consumer最多只能使用一個partition,當一個Group內consumer的數量大于partition的數量時, 只有等于partition個數的consumer能同時消費 ,其他的consumer處于等待狀態。

例如一個topic下有3個partition,那么在一個有5個consumer的group中只有3個consumer在同時消費topic的數據,而另外兩個consumer處于等待狀態,所以想要增加logstash的消費性能,可以適當的增加topic的partition數量,但kafka中partition數量過多也會導致kafka集群故障恢復時間過長,消耗更多的文件句柄與客戶端內存等問題,也并不是partition配置越多越好,需要在使用中找到一個平衡
kafka partition
kafka中partition數量可以在創建topic時指定:
# bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic ops_coffee --partitions 3Created topic "ops_coffee".--partitions:指定分區數,如果不指定默認會使用配置文件中 num.partitions 配置的數量
也可以手動修改partition的數量:
# bin/kafka-topics.sh --alter --zookeeper 127.0.0.1:2181 --partitions 5 --topic ops_coffeeAdding partitions succeeded!注意partition的數量只能增加不能減少
如果想要知道topic的partition信息,可以通過以下命令查看topic詳情:
# bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe --topic ops_coffeeTopic:ops_coffee PartitionCount:3 ReplicationFactor:2 Configs: Topic: ops_coffee Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2 Topic: ops_coffee Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3 Topic: ops_coffee Partition: 2 Leader: 3 Replicas: 3,1 Isr: 3,1至此對kafka consumer group有了更深入的了解,可以在具體的使用中游刃有余。
end:如果你覺得本文對你有幫助的話,記得關注點贊轉發,你的支持就是我更新動力。


和mysql_fetch_rows()函數_mysql)



,你要什么我就給你什么)


)

)







