Parser(語法分析器)的編寫相對于 Tokenizer (詞法分析器)要復雜得多,因此,在編寫之前可能也會鋪墊得更多一些。當然,本系列旨在“寫出”一個編譯器,所以理論方面只會簡單介紹 tao 語言所涉及的部分。
之前的幾章中,我純手寫了tao 語言的 Tokenizer。但如果我準備也純手寫一個 Parser,那將是非常麻煩且繁瑣的一件事情。實際上,就在在寫出這篇文章之前,我已完成了 Parser 的編寫,并測試妥當,因此我可以在此面對各位得出這個結論。
我將使用這么一種方式“制造”出 Parser:
將 tao 語言的所有語法細節描述出來,即定義 tao 語言。
寫一個能”根據定義,生成 tao 語言的 Parser“的程序。
如果以上描述有些讓人困惑,那我舉個通俗點的例子吧:
假如我想要制作一雙鞋子,通常的方案是,我會買好材料,并把鞋子做出來。但還有另一種方案,我先畫出鞋子的設計圖,再造一臺能依照設計圖造出鞋子的機器,然后把設計圖交給機器,再發動機器,得到鞋子。
在”制造鞋子的世界“中,除非我要開鞋廠,否則若我僅僅想造雙鞋子,那么前一個方案顯然更好。但在”制造編譯器的世界“中,卻與直覺相反,當語言本身足夠復雜的時候,后一種方案比前一種方案要方便得多。
至此,我需要一個能讀懂 tao 語言的定義,并根據定義生成 Parser 的一個程序。這種程序我們稱之為 Compiler-compiler 。這樣的程序(或稱工具)有很多現成的可供選擇(包括在 Java 平臺上可用的),但既然我這個系列叫做《從零開始寫個編譯器吧》,那顯然如果我用現成的工具,那是犯規行為。
因此,我還要寫一個 Compiler-compiler 出來才行。
那么,讓我先貼一張圖,以描述我將會寫出的 Compiler-compiler 的工作原理吧。
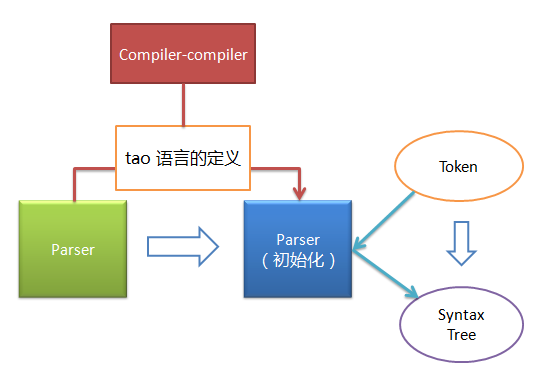
Compiler-compiler 會將 tao 語言的定義編譯成某種數據結構,而這種數據結構是 Parser 初始化的參數。Parser 只有獲得了這種數據結構才能正常工作。
當 Parser 初始化之后,它會讀取 Tokenizer 生成的 Token 序列,并同時通過解釋 Compiler-compiler 生成的數據結構,最后生成 Syntax Tree。
至此,在編寫 Parser 的章節中,我必須完成如下三個任務。
定義 tao 語言的語法細節,并挑選一個合適的形式描述出來。
編寫一個 Compiler-compiler,它能編譯 tao 語言的定義,并生成某種數據結構。
編寫一個 Parser,它通過解釋 Compiler-compiler 生成的數據結構,將 Token 序列編譯成 Syntax Tree。
 asort ksort rsort arsort krsort)

)






![java byte md5_Java開發網 - byte[]按自定義編碼轉換成String(MD5)](http://pic.xiahunao.cn/java byte md5_Java開發網 - byte[]按自定義編碼轉換成String(MD5))








)
