1、修改主機名稱
對master/slave1/slave2同時配置為Master/Slave1/Slave2
master@Master:~$?sudo?gedit?/etc/hostname
?上述3個虛機結點均需要進行以上步驟
?
2、填寫主機IP
對master/slave1/slave2同時配置
master@Master:~$?sudo?gedit?/etc/hosts
?
192.168.48.128 master
192.168.48.129 slave1
192.168.48.130 slave2
?
?上述3個虛機結點均需要進行以上步驟
?

?
3、建立hadoop用戶組及新用戶
?
對master/slave1/slave2同時配置
為hadoop集群專門設置一個用戶組及用戶
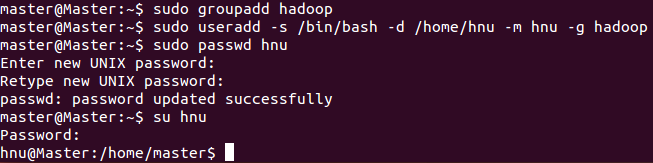
master@Master:~$?sudo?groupadd?hadoop? ? //設置hadoop用戶組
master@Master:~$?sudo?useradd?-s?/bin/bash?-d?/home/hnu?-m?hnu?-g?hadoop? ?//添加一個hnu用戶,此用戶屬于hadoop用戶組。
master@Master:~$?sudo?passwd?hnu? ?//設置用戶hnu登錄密碼
master@Master:~$?su?hnu? //切換到hnu用戶中
?
上述3個虛機結點均需要進行以上步驟
?
?
4、 配置ssh免密碼連入
?
Ubuntu14.04系統下:
對master/slave1/slave2同時配置
master@Master:~$?sudo?apt-get?install?openssh-client=1:6.6p1-2ubuntu1
master@Master:~$?sudo?apt-get?install?openssh-server
上述3個虛機結點均需要進行以上步驟
?
(1)?每個結點分別產生公私密鑰。
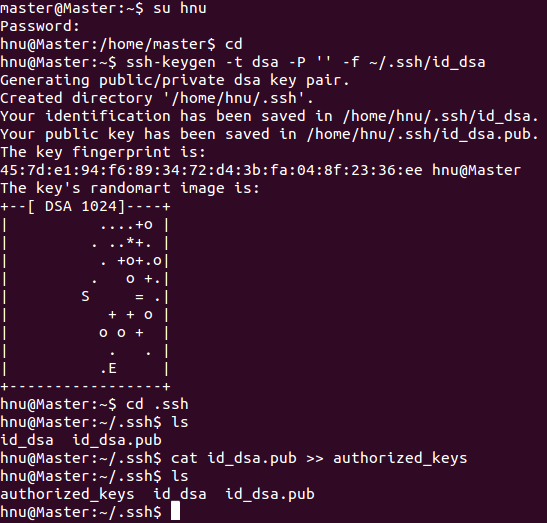
hnu@Master:~$?ssh-keygen?-t?dsa?-P?''?-f?~/.ssh/id_dsa
以上命令是產生公私密鑰,產生目錄在用戶主目錄下的.ssh目錄中,如下:
hnu@Master:~$?cd?.ssh
hnu@Master:~$?ls
Id_dsa.pub為公鑰,id_dsa為私鑰,緊接著將公鑰文件復制成authorized_keys文件,這個步驟是必須的,過程如下:
hnu@Master:~/.ssh$?cat?id_dsa.pub?>>?authorized_keys
hnu@Master:~/.ssh$?ls
用上述同樣的方法在剩下的兩個結點中如法炮制即可。
?
?上述3個虛機結點均需要進行以上步驟
?
?
(2)本機ssh免密碼登錄測試
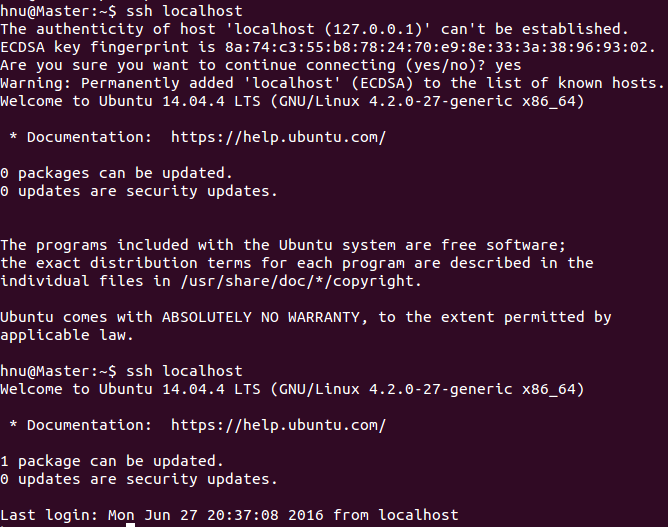
hnu@Master:~$?ssh?localhost
在單機結點上用ssh進行登錄,這將為后續對子結點SSH遠程免密碼登錄作好準備。
用上述同樣的方法在剩下的兩個結點中如法炮制即可。
?
上述3個虛機結點均需要進行以上步驟
?
?
(3)????讓主結點(master)能通過SSH免密碼登錄兩個子結點(slave)
?
1)對slave1節點操作:
為了實現這個功能,兩個slave結點的公鑰文件中必須要包含主結點的公鑰信息,這樣當master就可以順利安全地訪問這兩個slave結點了。操作過程如下:
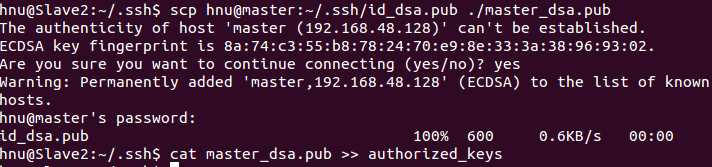
hnu@Slave1:~/.ssh$?scp?hnu@master:~/.ssh/id_dsa.pub?./master_dsa.pub
hnu@Slave1:~/.ssh$??cat?master_dsa.pub?>>?authorized_keys
如上過程顯示了slave1結點通過scp命令遠程登錄master結點,并復制master的公鑰文件到當前的目錄下,這一過程需要密碼驗證。接著,將master結點的公鑰文件追加至authorized_keys文件中,通過這步操作,如果不出問題,master結點就可以通過ssh遠程免密碼連接slave1結點了。
?
2)對slave2節點同樣進行以上步驟
?
在master結點中對兩個子節點進行免密登陸:
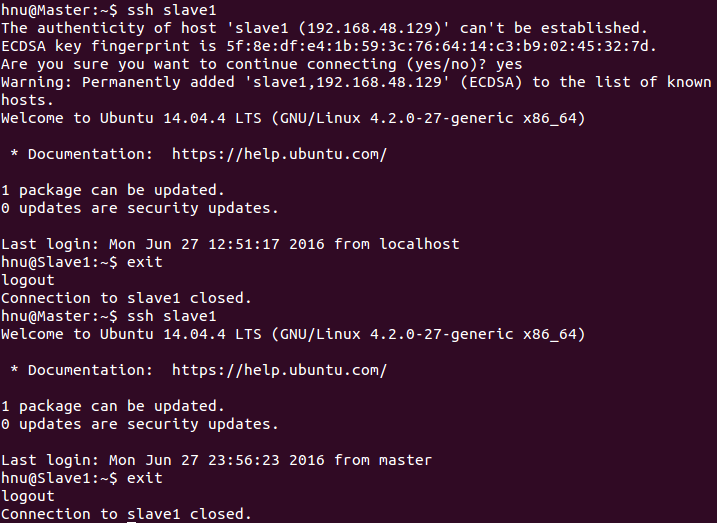
hnu@Master:~$?ssh?slave1
slave1結點首次連接時需要輸入yes后成功接入,緊接著注銷退出至master結點。然后再執行一遍ssh slave1,如果沒有要求你輸入”yes”,就算成功了,對node2結點也可以用同樣的方法進行上述操作。
?
?
表面上看,這兩個節點的ssh免密碼登錄已經配置成功,但是我們還需要對主節點master也要進行上面的同樣工作,據說是真實物理結點時需要做這項工作,因為jobtracker有可能會分布在其它結點上,jobtracker有不存在master結點上的可能性。
?
3)對master自身進行ssh免密碼登錄測試工作:
hnu@Master:~/.ssh$?scp?hnu@master:~/.ssh/id_dsa.pub??./master_dsa.pub
hnu@Master:~/.ssh$?cat?master_dsa.pub??>>?authorized_keys
hnu@Master:~/.ssh$?ssh?master
?
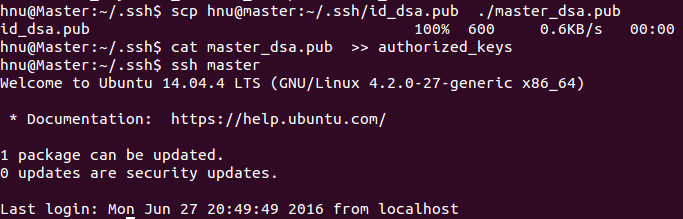
至此,SSH免密碼登錄已經配置成功。
?
5、JDK與HADOOP環境變量配置
對master/slave1/slave2同時配置
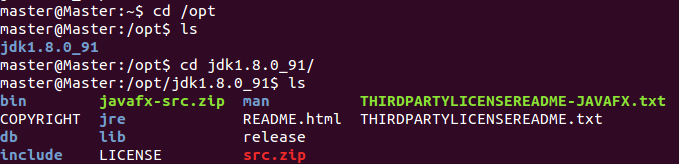
解壓JDK
master@Master:~$?sudo?tar?-zxvf?jdk-8u91-linux-x64.tar.gz?-C?/opt
?
master@Master:~$?sudo?gedit?/etc/profile
#JAVA
export?JAVA_HOME=/opt/jdk1.8.0_91
export?PATH=$PATH:$JAVA_HOME/bin
export?CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
#HADOOP
export?HADOOP_PREFIX=/home/hnu/hadoop-2.6.0
export?PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
export?HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export?HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib:$HADOOP_PREFIX/lib/native"
?
上述3個虛機結點均需要進行以上步驟
?
6、HADOOP安裝與配置
對master配置
解壓hadoop
master@Master:~$?sudo?tar?-zxvf?hadoop-2.6.0.tar.gz?-C?/home/hnu
?

master@Master:/home/hnu/hadoop-2.6.0/etc/hadoop$
1) ?core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hnu/hadoop-2.6.0/tmp</value>
<description>A?base?for?other?temporary?directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>
2) ? hadoop-env.sh 添加如下環境變量(一定要添加切勿少了)?
export JAVA_HOME=/opt/jdk1.8.0_91
export HADOOP_PID_DIR=/home/hnu/hadoop-2.6.0/pids
在yarn-env.sh下添加如下環境變量
export JAVA_HOME=/opt/jdk1.8.0_91
export YARN_PID_DIR=/home/hnu/hadoop-2.6.0/pids
?
3) hdfs-site.xml?
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hnu/hadoop-2.6.0/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hnu/hadoop-2.6.0/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
?
4) ?mapred-site.xml?
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master:9001</value>
</property>
</configuration>
?
5) yarn-site.xml?
<configuration>
<!--?Site?specific?YARN?configuration?properties?-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
?
6)slaves
slave1
slave2
?
7、向各節點復制hadoop
向slave1節點復制hadoop:
hnu@Master:~$??scp?-r?./hadoop-2.6.0/?slave1:~
向slave2節點復制hadoop:
hnu@Master:~$??scp?-r?./hadoop-2.6.0/?slave2:~
?
8、賦予權限
對master/slave1/slave2執行相同操作
將目錄hadoop文件夾及子目錄的所有者和組更改為用戶hnu和組hadoop
root@Master:/home/hnu#?chown?-R?hnu:hadoop?hadoop-2.6.0
?
9、格式化hadoop
hnu@Master:~$?source?/etc/profile
hnu@Master:~$?hdfs?namenode?-format
?
?
?
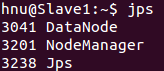
10、啟動/關閉hadoop
start-all.sh/stop-all.sh
start-dfs.sh/start-yarn.sh
stop-dfs.sh/stop-dfs.sh
?

?
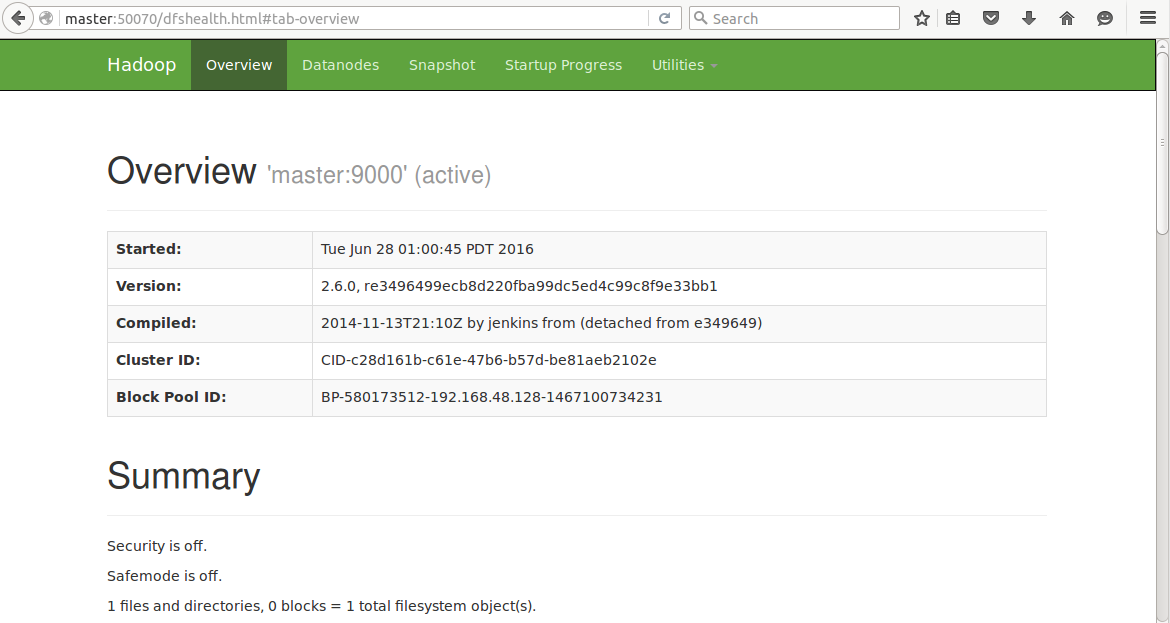
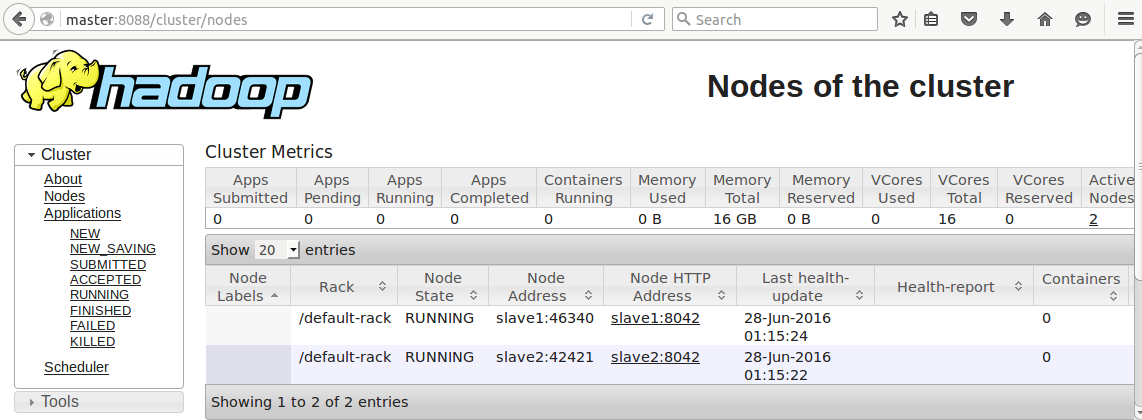
查看hdfs/RM
192.168.48.128:50070/192.168.48.128:8088
master:50070/master:8088
?
?
注:
(1)hadoop集群啟動jps查看后沒有DATANODE?
刪除slave1/slave2 ?中 ?/home/hnu/hadoop/data/current/VERSION文件后重啟即可
寫留言![]()
微信掃一掃
關注該公眾號



![BZOJ1857:[SCOI2010]傳送帶——題解](http://pic.xiahunao.cn/BZOJ1857:[SCOI2010]傳送帶——題解)



——數據庫(二))



)




)

)
