Java 提供了不同層面的線程安全支持。在傳統集合框架內部,除了 Hashtable 等同步容器,還提供了所謂的同步包裝器(Synchronized Wrapper),我們可以調用 Collections 工具類提供的包裝方法,來獲取一個同步的包裝容器(如 Collections.synchronizedMap),但是它們都是利用非常粗粒度的同步方式,在高并發情況下,性能比較低。
另外,更加普遍的選擇是利用并發包提供的線程安全容器類,它提供了:
-
各種并發容器,比如 ConcurrentHashMap、CopyOnWriteArrayList(之前文章有介紹)。
-
各種線程安全隊列(Queue/Deque),如 ArrayBlockingQueue、SynchronousQueue。
-
各種有序容器的線程安全版本等。
具體保證線程安全的方式,包括有從簡單的 synchronize 方式,到基于更加精細化的,比如基于鎖分離實現的 ConcurrentHashMap 等并發實現等。具體選擇要看開發的場景需求,總體來說,并發包內提供的容器通用場景,遠優于早期的簡單同步實現。
?
?
Hashtable 本身比較低效,因為它的實現基本就是將 put、get、size 等各種方法加上“synchronized”。簡單來說,這就導致了所有并發操作都要競爭同一把鎖,一個線程在進行同步操作時,其他線程只能等待,大大降低了并發操作的效率。
Collections.synchronizedMap同步包裝器只是利用輸入 Map 構造了另一個同步版本,所有操作雖然不再聲明成為 synchronized 方法,但是還是利用了“this”作為互斥的 mutex,沒有真正意義上的改進。
private static class SynchronizedMap<K,V>implements Map<K,V>, Serializable {private final Map<K,V> m; // Backing Mapfinal Object mutex; // Object on which to synchronize// …public int size() {synchronized (mutex) {return m.size();}}// … }
所以,Hashtable 或者同步包裝版本,都只是適合在非高度并發的場景下。
?
?
?
ConcurrentHashMap 分析
早期 ConcurrentHashMap,JDK1.7,其實現是基于:
-
分離鎖,也就是將內部進行分段(Segment),里面則是 HashEntry 的數組,和 HashMap 類似,哈希相同的條目也是以鏈表形式存放。
-
HashEntry 內部使用 volatile 的 value 字段來保證可見性,也利用了不可變對象的機制以改進利用 Unsafe 提供的底層能力,比如 volatile access,去直接完成部分操作,以最優化性能,畢竟 Unsafe 中的很多操作都是 JVM intrinsic 優化過的。
你可以參考下面這個早期 ConcurrentHashMap 內部結構的示意圖,其核心是利用分段設計,在進行并發操作的時候,只需要鎖定相應段,這樣就有效避免了類似 Hashtable 整體同步的問題,大大提高了性能。
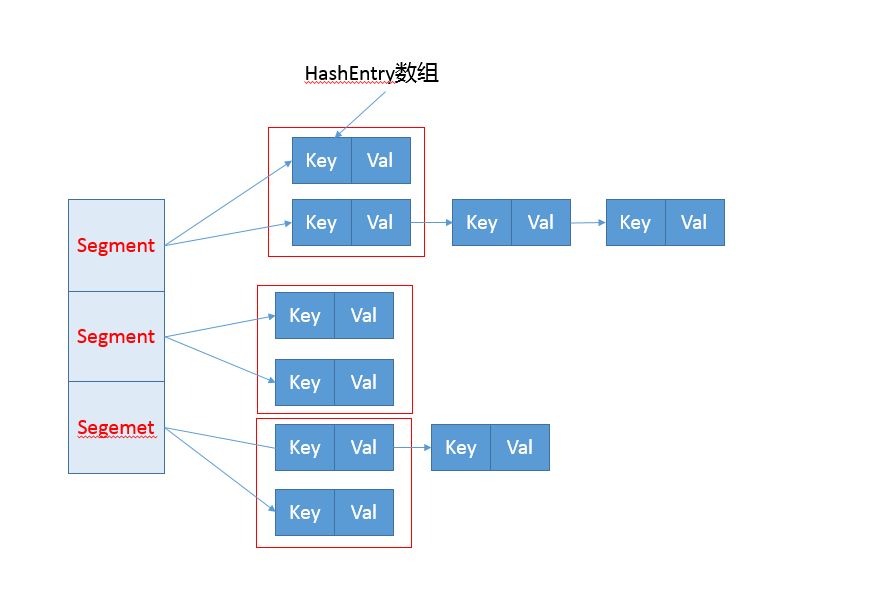
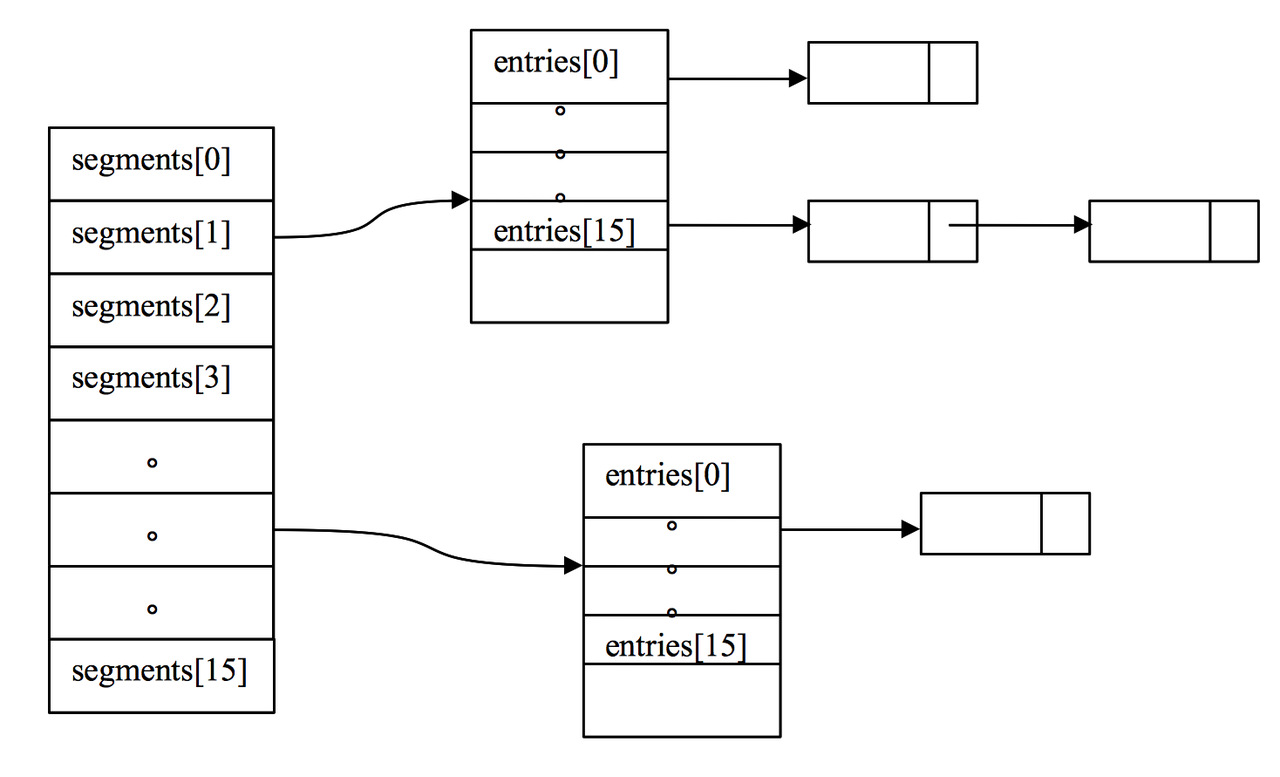
?
?
在構造的時候,Segment 的數量由所謂的 concurrentcyLevel 決定,默認是 16,也可以在相應構造函數直接指定。注意,Java 需要它是 2 的冪數值,如果輸入是類似 15 這種非冪值,會被自動調整到 16 之類 2 的冪數值。get 操作需要保證的是可見性,所以并沒有什么同步邏輯。
public V get(Object key) {Segment<K,V> s; // manually integrate access methods to reduce overheadHashEntry<K,V>[] tab;int h = hash(key.hashCode());// 利用位操作替換普通數學運算long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;// 以 Segment 為單位,進行定位// 利用 Unsafe 直接進行 volatile accessif ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&(tab = s.table) != null) {// 省略 }return null;}
對于 put 操作,首先是通過二次哈希避免哈希沖突,然后以 Unsafe 調用方式,直接獲取相應的 Segment,然后進行線程安全的 put 操作:
public V put(K key, V value) {Segment<K,V> s;if (value == null)throw new NullPointerException();// 二次哈希,以保證數據的分散性,避免哈希沖突int hash = hash(key.hashCode());int j = (hash >>> segmentShift) & segmentMask;if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegments = ensureSegment(j);return s.put(key, hash, value, false);}
其核心邏輯實現在下面的內部方法中:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {// scanAndLockForPut 會去查找是否有 key 相同 Node// 無論如何,確保獲取鎖HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);V oldValue;try {HashEntry<K,V>[] tab = table;int index = (tab.length - 1) & hash;HashEntry<K,V> first = entryAt(tab, index);for (HashEntry<K,V> e = first;;) {if (e != null) {K k;// 更新已有 value... }else {// 放置 HashEntry 到特定位置,如果超過閾值,進行 rehash// ... }}} finally {unlock();}return oldValue;}
?所以,從上面的源碼清晰的看出,在進行并發寫操作時:
-
ConcurrentHashMap 會獲取可重入鎖,以保證數據一致性,Segment 本身就是基于 ReentrantLock 的擴展實現,所以,在并發修改期間,相應 Segment 是被鎖定的。
-
在最初階段,進行重復性的掃描,以確定相應 key 值是否已經在數組里面,進而決定是更新還是放置操作。重復掃描、檢測沖突是 ConcurrentHashMap 的常見技巧。
-
?ConcurrentHashMap 中同樣存在擴容。不過與HashMap有一個明顯區別,就是它進行的不是整體的擴容,而是單獨對 某個Segment中的數組 進行擴容。
?
另外一個 Map 的 size 方法同樣需要關注,它的實現涉及分離鎖的一個副作用。
試想,如果不進行同步,簡單的計算所有 Segment 的總值,可能會因為并發 put,導致結果不準確,但是直接鎖定所有 Segment 進行計算,就會變得非常昂貴。其實,分離鎖也限制了 Map 的初始化等操作。
所以,ConcurrentHashMap 的實現是通過重試機制(RETRIES_BEFORE_LOCK,指定重試次數 2)來試圖獲得可靠值。如果沒有監控到發生變化(通過對比 Segment.modCount),就直接返回,否則獲取鎖進行操作。
?
?JDK1.7對ConcurrentHashMap的詳細分析:? ?
http://www.cnblogs.com/ITtangtang/p/3948786.html? ? (jdk1.7? 比較詳細的介紹)
https://blog.csdn.net/zlfprogram/article/details/77524326
?
獲取鎖時,并不直接使用lock來獲取,因為該方法獲取鎖失敗時會掛起(可重入鎖)。事實上,它使用了自旋鎖(CAS),如果tryLock獲取鎖失敗,說明鎖被其它線程占用,此時通過循環再次以tryLock的方式申請鎖。如果在循環過程中該Key所對應的鏈表頭被修改,則重置retry次數。如果retry次數超過一定值,則使用lock方法申請鎖。
這里使用自旋鎖(CAS)是因為自旋鎖的效率比較高,但是它消耗CPU資源比較多,因此在自旋次數超過閾值時切換為互斥鎖。
?
static final class HashEntry<K,V> { final K key; final int hash; volatile V value; final HashEntry<K,V> next; } ?
ConcurrentHashMap的一些特點:
1、public V get(Object key)不涉及到鎖,也就是說獲得對象時沒有使用鎖;(CopyOnWrite讀的時候也是不需要加鎖的)
2、put、remove方法要使用鎖,但并不一定有鎖爭用,原因在于ConcurrentHashMap將緩存的變量分到多個Segment,每個Segment上有一個鎖,只要多個線程訪問的不是一個Segment就沒有鎖爭用,就沒有堵塞,各線程用各自的鎖,ConcurrentHashMap缺省情況下生成16個Segment,也就是允許16個線程并發的更新而盡量沒有鎖爭用;(CopyOnWrite寫的時候需要加可重入鎖)
3、Iterator對象的使用,不一定是和其它更新線程同步,獲得的對象可能是更新前的對象,ConcurrentHashMap允許一邊更新、一邊遍歷,也就是說在Iterator對象遍歷的時候,ConcurrentHashMap也可以進行remove,put操作,且遍歷的數據會隨著remove,put操作產出變化,所以希望遍歷到當前全部數據的話,要么以ConcurrentHashMap變量為鎖進行同步(synchronized該變量),以整個ConcurrentHashMap為獲取鎖的對象,要么使用CopiedIterator包裝iterator,使其拷貝當前集合的全部數據,但是這樣生成的iterator不可以進行remove操作。
?
?
?
?
?
?
在 Java 8 中,ConcurrentHashMap 的變化:
1.8中放棄了Segment臃腫的設計,取而代之的是采用Node?+?CAS?+?Synchronized來保證并發安全進行實現
-
總體結構上,它的內部存儲變得和HashMap 結構非常相似,同樣是大的桶(bucket)數組,然后內部也是一個個所謂的鏈表結構(bin),同步的粒度要更細致一些。1.8以后的鎖的顆粒度,是加在鏈表頭上的,這個是個思路上的突破。
-
其內部仍然有 Segment 定義,但僅僅是為了保證序列化時的兼容性而已,不再有任何結構上的用處。
-
因為不再使用 Segment,初始化操作大大簡化,修改為 lazy-load(延遲初始化) 形式,這樣可以有效避免初始開銷,解決了老版本很多人抱怨的這一點。
-
數據存儲利用 volatile 來保證可見性。
-
使用 CAS 等操作,在特定場景進行無鎖并發操作。
-
使用 Unsafe、LongAdder 之類底層手段,進行極端情況的優化。
?先看看現在的數據存儲內部實現,我們可以發現 Key 是 final 的,因為在生命周期中,一個條目的 Key 發生變化是不可能的;與此同時 val,則聲明為 volatile,以保證可見性。
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key; // key基本不會變volatile V val; // val需要保證可見性volatile Node<K,V> next;// … }
并發的 put :
當執行put方法插入數據時,根據key的hash值,在Node數組中找到相應的位置
1、如果相應位置的Node還未初始化,則通過CAS插入相應的數據;
2、如果相應位置的Node不為空,且當前該節點不處于移動狀態,則對該頭節點加synchronized鎖,如果該節點的hash不小于0,則遍歷鏈表更新節點或插入新節點;
3、如果該節點是TreeBin類型的節點,說明是紅黑樹結構,則通過putTreeVal方法往紅黑樹中插入節點;
4、如果binCount不為0,說明put操作對數據產生了影響,如果當前鏈表的個數達到8個,則通過treeifyBin方法轉化為紅黑樹,如果oldVal不為空,說明是一次更新操作,沒有對元素個數產生影響,則直接返回舊值;
5、如果插入的是一個新節點,則執行addCount()方法嘗試更新元素個數baseCount;1.8中使用一個volatile類型的變量baseCount記錄元素的個數,當插入新數據或則刪除數據時,會通過addCount()方法更新baseCount
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0; // 鏈表長度for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh; K fk; V fv;if (tab == null || (n = tab.length) == 0)tab = initTable(); else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // f為鏈表第一個節點,即在數組中的元素// 利用 CAS 去進行無鎖線程安全操作,如果 bin 是空的if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))break; }else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else if (onlyIfAbsent // 不加鎖,進行檢查&& fh == hash&& ((fk = f.key) == key || (fk != null && key.equals(fk)))&& (fv = f.val) != null)return fv;else {V oldVal = null;synchronized (f) { // 對鏈表頭節點加鎖,即數組中的那個元素加鎖// 細粒度的同步修改操作... }}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD) //Bin鏈表超過閥值,樹化treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null; }
初始化操作實現在 initTable 里面,這是一個典型的 CAS 使用場景,利用 volatile 的 sizeCtl 作為互斥手段:如果發現競爭性的初始化,就 spin 在那里,等待條件恢復;否則利用 CAS 設置排他標志。如果成功則進行初始化;否則重試。
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;while ((tab = table) == null || tab.length == 0) {// 如果發現沖突,進行 spin 等待if ((sc = sizeCtl) < 0)Thread.yield(); // CAS 成功返回 true,則進入真正的初始化邏輯else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {try {if ((tab = table) == null || tab.length == 0) {int n = (sc > 0) ? sc : DEFAULT_CAPACITY;Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;sc = n - (n >>> 2);}} finally {sizeCtl = sc;}break;}}return tab; }
當 bin 為空時,同樣是沒有必要鎖定,也是以 CAS 操作去放置。
你有沒有注意到,在同步邏輯上,它使用的是 synchronized,而不是通常建議的 ReentrantLock 之類,這是為什么呢?現代 JDK 中,synchronized 已經被不斷優化,可以不再過分擔心性能差異,另外,相比于 ReentrantLock,它可以減少內存消耗,這是個非常大的優勢。
與此同時,更多細節實現通過使用 Unsafe 進行了優化,例如 tabAt 就是直接利用 getObjectAcquire,避免間接調用的開銷。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {return (Node<K,V>)U.getObjectAcquire(tab, ((long)i << ASHIFT) + ABASE); }
如何實現 size 操作的,真正的邏輯是在 sumCount 方法中
final long sumCount() {CounterCell[] as = counterCells; CounterCell a;long sum = baseCount;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum; }
我們發現,雖然思路仍然和以前類似,都是分而治之的進行計數,然后求和處理,但實現卻基于一個奇怪的 CounterCell。 難道它的數值,就更加準確嗎?數據一致性是怎么保證的?
static final class CounterCell {volatile long value;CounterCell(long x) { value = x; } }
其實,對于 CounterCell 的操作,是基于 java.util.concurrent.atomic.LongAdder 進行的,是一種 JVM 利用空間換取更高效率的方法。這個東西非常小眾,大多數情況下,建議還是使用 AtomicLong,足以滿足絕大部分應用的性能需求。
?
?
size實現
JDK1.8中使用一個volatile類型的變量baseCount記錄元素的個數,當插入新數據或則刪除數據時,會通過addCount()方法更新baseCount
1、初始化時counterCells為空,在并發量很高時,如果存在兩個線程同時執行CAS修改baseCount值,則失敗的線程會繼續執行方法體中的邏輯,使用CounterCell記錄元素個數的變化;
2、如果CounterCell數組counterCells為空,調用fullAddCount()方法進行初始化,并插入對應的記錄數,通過CAS設置cellsBusy字段,只有設置成功的線程才能初始化CounterCell數組
3、如果通過CAS設置cellsBusy字段失敗的話,則繼續嘗試通過CAS修改baseCount字段,如果修改baseCount字段成功的話,就退出循環,否則繼續循環插入CounterCell對象;
所以在1.8中的size實現比1.7簡單多,因為元素個數保存baseCount中,部分元素的變化個數保存在CounterCell數組中。通過累加baseCount和CounterCell數組中的數量,即可得到元素的總個數
?
?
?
需要注意的一點是,1.8以后的鎖的顆粒度,是加在鏈表頭上的,這個是個思路上的突破。
?
ConcurrentHashMap1.7與1.8的不同實現:http://www.importnew.com/23610.html
?
?
自旋鎖個人理解的是CAS的一種應用方式。并發包中的原子類是典型的應用。
偏向鎖個人理解的是獲取鎖的優化。在ReentrantLock中用于實現已獲取完鎖的的線程重入問題。偏向鎖,側重是低競爭場景的優化,去掉可能不必要的同步
?
從1.5有并發包,到1.6對synchronized的改進,到1.7的并發map的分段鎖(segment是可重入鎖ReentrantLock),再到1.8的cas(鏈表頭為空)+synchronized(鏈表頭不為空,對鏈表頭加鎖)。
?jdk8就相當于把segment分段鎖更細粒度了(去掉了segment),每個數組元素(鏈表頭節點)就是原來一個segment,那并發度就由原來segment數變為數組長度了,而且用到了cas樂觀鎖,所以能支持更高的并發。
?



















