文章目錄
- 一. XML
- 1. XML 和 HTML 的區別
- 2. XML文檔示例
- 3. HTML DOM 模型示例
- 4. XML的節點關系
- 二. 什么是XPath?
- 1. 選取節點
- 2. 謂語(Predicates)
- 3. 選取未知節點
- 4. 選取若干路徑
- 5. XPath的運算符
- 三. lxml庫
- 1. 初步使用
- 2. 文件讀取
- 四. XPath實例測試
- 1. 獲取所有的 < li> 標簽
- 2. 繼續獲取< li> 標簽的所有 class屬性
- 3. 繼續獲取< li>標簽下href 為 link1.html 的 < a> 標簽
- 4. 獲取< li> 標簽下的所有 < span> 標簽
- 5. 獲取 < li> 標簽下的< a>標簽里的所有 class
- 6. 獲取最后一個 < li> 的 < a> 的 href
- 7. 獲取倒數第二個元素的內容
- 8. 獲取 class 值為 bold 的標簽名
一. XML
有人說,我正則用的不好,處理HTML文檔很累,有沒有其他的方法?
有!那就是XPath,我們可以先將 HTML文件 轉換成 XML文檔,然后用 XPath 查找 HTML 節點或元素。
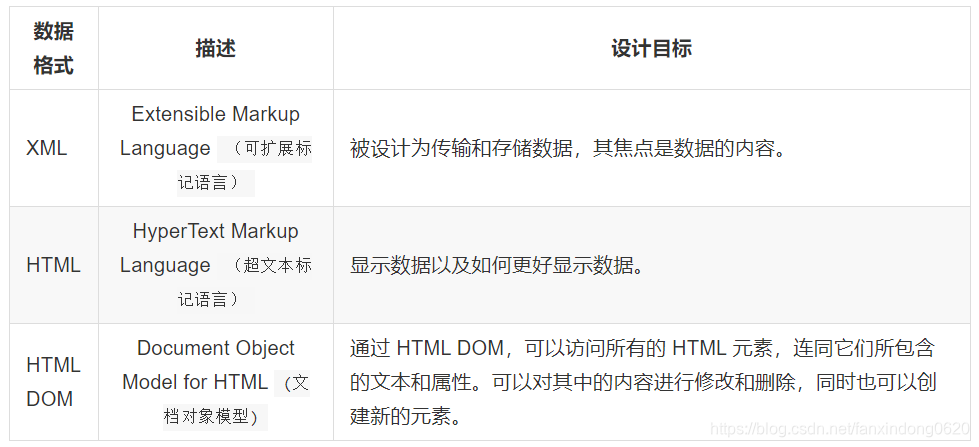
- XML 指可擴展標記語言(EXtensible Markup Language)
- XML 是一種標記語言,很類似 HTML
- XML 的設計宗旨是傳輸數據,而非顯示數據
- XML 的標簽需要我們自行定義。
- XML 被設計為具有自我描述性。
- XML 是 W3C 的推薦標準
W3School官方文檔:http://www.w3school.com.cn/xml/index.asp
1. XML 和 HTML 的區別
2. XML文檔示例
<?xml version="1.0" encoding="utf-8"?><bookstore><book category="cooking"><title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price></book> <book category="children"><title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price></book> <book category="web"><title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price></book><book category="web" cover="paperback"><title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price></book></bookstore>
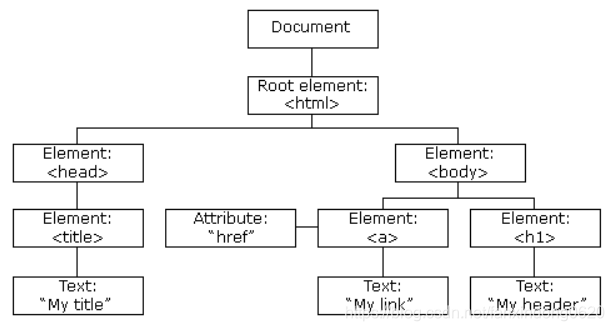
3. HTML DOM 模型示例
HTML DOM 定義了訪問和操作 HTML 文檔的標準方法,以樹結構方式表達 HTML 文檔。
4. XML的節點關系
下面一個簡單的XML例子中:
<?xml version="1.0" encoding="utf-8"?><bookstore><book><title>Harry Potter</title><author>J K. Rowling</author><year>2005</year><price>29.99</price></book></bookstore>
- 父(Parent) 每個元素以及屬性都有一個父。book 元素是 title、author、year 以及 price 元素的父。
- 子(Children)元素節點可有零個、一個或多個子。title、author、year 以及 price 元素都是 book 元素的子。
- 同胞(Sibling)擁有相同的父的節點。title、author、year 以及 price 元素都是同胞。
- 先輩(Ancestor)某節點的父、父的父,等等。title 元素的先輩是 book 元素和 bookstore 元素。
- 后代(Descendant)某個節點的子,子的子,等等。bookstore 的后代是 book、title、author、year 以及 price 元素。
二. 什么是XPath?
XPath (XML Path Language) 是一門在 XML 文檔中查找信息的語言,可用來在 XML 文檔中對元素和屬性進行遍歷。
W3School官方文檔:http://www.w3school.com.cn/xpath/index.asp
XPath 開發工具
開源的XPath表達式編輯工具:XMLQuire(XML格式文件可用)
Chrome插件 XPath Helper
Firefox插件 XPath Checker
1. 選取節點
XPath 使用路徑表達式來選取 XML 文檔中的節點或者節點集。這些路徑表達式和我們在常規的電腦文件系統中看到的表達式非常相似。
下面列出了最常用的路徑表達式:
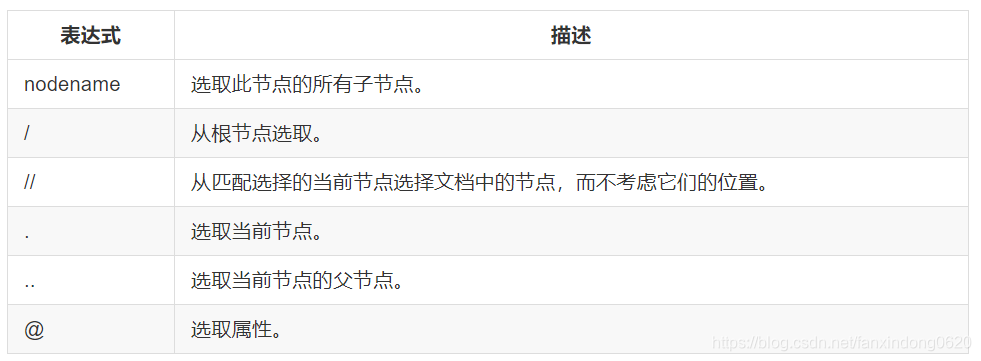
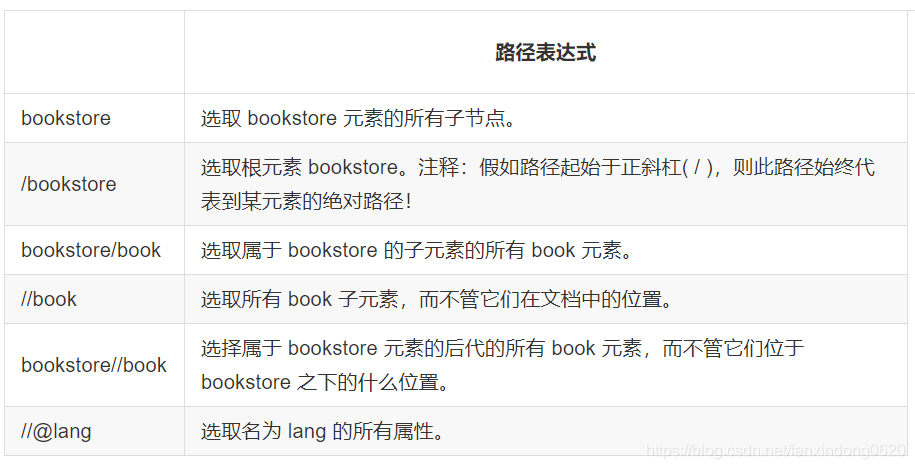
在下面的表格中,我們已列出了一些路徑表達式以及表達式的結果:
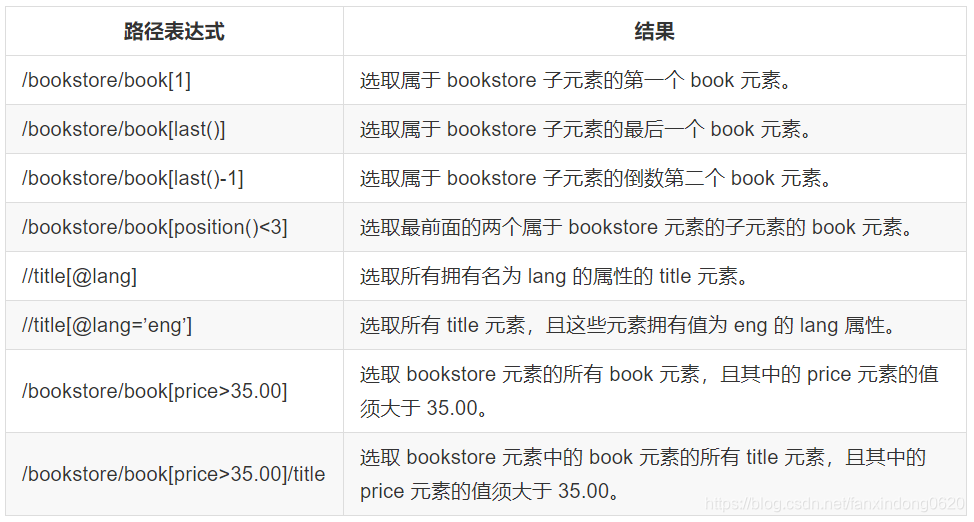
2. 謂語(Predicates)
謂語用來查找某個特定的節點或者包含某個指定的值的節點,被嵌在方括號中。
在下面的表格中,我們列出了帶有謂語的一些路徑表達式,以及表達式的結果:
3. 選取未知節點
XPath 通配符可用來選取未知的 XML 元素。
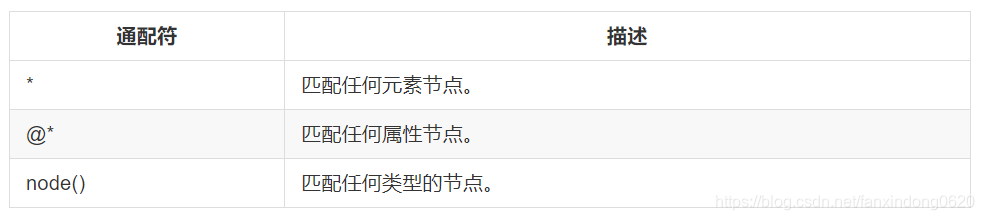
在下面的表格中,我們列出了一些路徑表達式,以及這些表達式的結果:
4. 選取若干路徑
通過在路徑表達式中使用“|”運算符,您可以選取若干個路徑。
在下面的表格中,我們列出了一些路徑表達式,以及這些表達式的結果:

5. XPath的運算符
下面列出了可用在 XPath 表達式中的運算符:

這些就是XPath的語法內容,在運用到Python抓取時要先轉換為xml。
三. lxml庫
lxml 是 一個HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 數據。
lxml和正則一樣,也是用 C 實現的,是一款高性能的 Python HTML/XML 解析器,我們可以利用之前學習的XPath語法,來快速的定位特定元素以及節點信息。
lxml python 官方文檔:http://lxml.de/index.html
需要安裝C語言庫,可使用 pip 安裝:pip install lxml (或通過wheel方式安裝)
1. 初步使用
我們利用它來解析 HTML 代碼,簡單示例:
from lxml import etreetext = '''
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a> # 注意,此處缺少一個 </li> 閉合標簽</ul></div>
'''#利用etree.HTML,將字符串解析為HTML文檔
print('------1------')
print(text)
print (type(text))html = etree.HTML(text)
print('-----2-------')
print(html)
print (type(html))# 按字符串序列化HTML文檔
result = etree.tostring(html)
print('-----3-------')
print(result)
print (type(result))
輸出結果:
------1------<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a> # 注意,此處缺少一個 </li> 閉合標簽</ul></div><class 'str'>
-----2-------
<Element html at 0x1e839453708>
<class 'lxml.etree._Element'>
-----3-------
b'<html><body><div>\n <ul>\n <li class="item-0"><a href="link1.html">first item</a></li>\n <li class="item-1"><a href="link2.html">second item</a></li>\n <li class="item-inactive"><a href="link3.html">third item</a></li>\n <li class="item-1"><a href="link4.html">fourth item</a></li>\n <li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签\n </ul>\n </div>\n</body></html>'
<class 'bytes'>
lxml 可以自動修正 html 代碼,例子里不僅會補全 li 標簽,還添加了 body,html 標簽。
2. 文件讀取
除了直接讀取字符串,lxml還支持從文件里讀取內容。我們新建一個hello.html文件:
<!-- hello.html --><div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
再利用 etree.parse() 方法來讀取文件。
from lxml import etree# 讀取外部文件 hello.html
html1 = etree.parse('./hello.html')
result1 = etree.tostring(html1, pretty_print=True)print('--------------------')
print(result1)print('-------如果是文件讀取,需要使用prase(),而不是用HTML,否則會出現下邊結果:---------')html2 = etree.HTML('./hello.html')
result2 = etree.tostring(html2, pretty_print=True)
print(result2)
運行結果:
--------------------
b'<div>\n <ul>\n <li class="item-0"><a href="link1.html">first item</a></li>\n <li class="item-1"><a href="link2.html">second item</a></li>\n <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>\n <li class="item-1"><a href="link4.html">fourth item</a></li>\n <li class="item-0"><a href="link5.html">fifth item</a></li>\n </ul>\n </div>\n'
-------如果是文件讀取,需要使用prase(),而不是用HTML,否則會出現下邊結果:---------
b'<html>\n <body>\n <p>./hello.html</p>\n </body>\n</html>\n'
四. XPath實例測試
1. 獲取所有的 < li> 標簽
from lxml import etreehtml = etree.parse('hello.html')
print (type(html)) # 顯示etree.parse() 返回類型result = html.xpath('//li')print (result) # 打印<li>標簽的元素集合
print (len(result))
print (type(result))
print (type(result[0]))
輸出結果:
<class 'lxml.etree._ElementTree'>
[<Element li at 0x21658f02608>, <Element li at 0x21658f02708>, <Element li at 0x21658f02748>, <Element li at 0x21658f02788>, <Element li at 0x21658f027c8>]
5
<class 'list'>
<class 'lxml.etree._Element'>
2. 繼續獲取< li> 標簽的所有 class屬性
from lxml import etreehtml = etree.parse('hello.html')
result = html.xpath('//li/@class')print(result)
print(type(result))
運行結果:
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
<class 'list'>
3. 繼續獲取< li>標簽下href 為 link1.html 的 < a> 標簽
from lxml import etreehtml = etree.parse('hello.html')
result = html.xpath('//li/a[@href="link1.html"]')print result
輸出結果:
[<Element a at 0x23b68132748>]
<class 'list'>
4. 獲取< li> 標簽下的所有 < span> 標簽
from lxml import etreehtml = etree.parse('hello.html')#result = html.xpath('//li/span')
#注意這么寫是不對的:
#因為 / 是用來獲取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用雙斜杠result = html.xpath('//li//span')print(result)
print(type(result))
輸出結果:
[<Element span at 0x28d12587508>]
<class 'list'>
5. 獲取 < li> 標簽下的< a>標簽里的所有 class
from lxml import etreehtml = etree.parse('hello.html')
result = html.xpath('//li/a//@class')print(result)
print(type(result))
輸出結果:
['bold']
<class 'list'>
6. 獲取最后一個 < li> 的 < a> 的 href
from lxml import etreehtml = etree.parse('hello.html')
result = html.xpath('//li/a//@class')print(result)
print(type(result))
輸出結果:
['link5.html']
<class 'list'>
7. 獲取倒數第二個元素的內容
from lxml import etreehtml = etree.parse('hello.html')
result = html.xpath('//li[last()-1]/a')# text 方法可以獲取元素內容
print (result[0].text)
print (type(result[0].text))
輸出結果:
fourth item
<class 'str'>8. 獲取 class 值為 bold 的標簽名
from lxml import etreehtml = etree.parse('hello.html')result = html.xpath('//*[@class="bold"]')# tag方法可以獲取標簽名
print (result[0].tag)
print (type(result[0].tag))
輸出結果:
span
<class 'str'>

)













)


)
