文章目錄
- 一. 案例介紹
- 二.創建項目
- 三. settings.py配置
- 四. 詳細代碼
- 五. 部署
- 1. windows環境下生成requirements.txt文件
- 2. xshell連接ubuntu服務器并安裝依賴環境
- 3. 修改部分代碼
- 4. 上傳代碼至服務器并運行
一. 案例介紹
爬取房天下(https://www1.fang.com/)的網頁信息。
源代碼已更新至:Github
二.創建項目
打開windows終端,切換至項目將要存放的目錄下:
scrapy startproject fang
cd fang\
scrapy genspider sfw “fang.com”
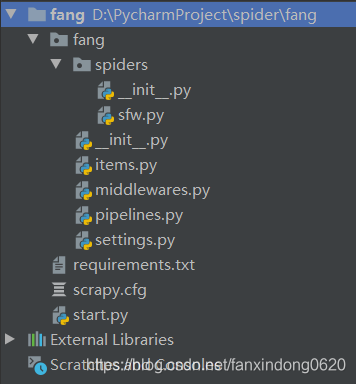
項目目錄結構如下所示:
三. settings.py配置
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',
}
DOWNLOADER_MIDDLEWARES = {'fang.middlewares.UserAgentDownloadMiddleware': 543,
}
ITEM_PIPELINES = {'fang.pipelines.FangPipeline': 300,
}
四. 詳細代碼
settings.py:
# -*- coding: utf-8 -*-# Scrapy settings for fang project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'fang'SPIDER_MODULES = ['fang.spiders']
NEWSPIDER_MODULE = 'fang.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'fang (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',
}# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'fang.middlewares.FangSpiderMiddleware': 543,
#}# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {'fang.middlewares.UserAgentDownloadMiddleware': 543,
}# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'fang.pipelines.FangPipeline': 300,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'items.py:
# -*- coding: utf-8 -*-# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass NewHouseItem(scrapy.Item):# 省份province = scrapy.Field()# 城市city = scrapy.Field()# 小區名字name = scrapy.Field()# 價格price = scrapy.Field()# 幾居 列表rooms = scrapy.Field()# 面積area = scrapy.Field()# 地址address = scrapy.Field()# 行政區district = scrapy.Field()# 是否在售sale = scrapy.Field()# 房天下詳情頁面的urlorigin_url = scrapy.Field()class ESFHouseItem(scrapy.Item):# 省份province = scrapy.Field()# 城市city = scrapy.Field()# 小區名字name = scrapy.Field()# 幾室幾廳rooms = scrapy.Field()# 層floor = scrapy.Field()# 朝向toward = scrapy.Field()# 年代year = scrapy.Field()# 地址address = scrapy.Field()# 建筑面積area = scrapy.Field()# 總價price = scrapy.Field()# 單價unit = scrapy.Field()# 原始urlorigin_url = scrapy.Field()pipelines.py:
# -*- coding: utf-8 -*-# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.exporters import JsonLinesItemExporterclass FangPipeline(object):def __init__(self):self.newhouse_fp = open('newhouse.json','wb')self.esfhouse_fp = open('esfhouse.json','wb')self.newhouse_exporter = JsonLinesItemExporter(self.newhouse_fp,ensure_ascii=False)self.esfhouse_exporter = JsonLinesItemExporter(self.esfhouse_fp, ensure_ascii=False)def process_item(self, item, spider):self.newhouse_exporter.export_item(item)self.esfhouse_exporter.export_item(item)return itemdef close_spider(self,spider):self.newhouse_fp.close()self.esfhouse_fp.close()sfw.py:
# -*- coding: utf-8 -*-
import reimport scrapy
from fang.items import NewHouseItem, ESFHouseItemclass SfwSpider(scrapy.Spider):name = 'sfw'allowed_domains = ['fang.com']start_urls = ['https://www.fang.com/SoufunFamily.htm']def parse(self, response):trs = response.xpath("//div[@class='outCont']//tr")province = Nonefor tr in trs:tds = tr.xpath(".//td[not(@class)]")province_td = tds[0]province_text = province_td.xpath(".//text()").get()province_text = re.sub(r"\s","",province_text)if province_text:province = province_textif province == "其它":continuecity_id = tds[1]city_links = city_id.xpath(".//a")for city_link in city_links:city = city_link.xpath(".//text()").get()city_url = city_link.xpath(".//@href").get()# print("省份:",province)# print("城市:", city)# print("城市鏈接:", city_url)#構建新房的url鏈接url_module = city_url.split("//")scheme = url_module[0]domain_all = url_module[1].split("fang")domain_0 = domain_all[0]domain_1 = domain_all[1]if "bj." in domain_0:newhouse_url = "https://newhouse.fang.com/house/s/"esf_url = "https://esf.fang.com/"else:newhouse_url =scheme + "//" + domain_0 + "newhouse.fang" + domain_1 + "house/s/"# 構建二手房的URL鏈接esf_url = scheme + "//" + domain_0 + "esf.fang" + domain_1# print("城市:%s%s"%(province, city))# print("新房鏈接:%s"%newhouse_url)# print("二手房鏈接:%s"%esf_url)# yield scrapy.Request(url=newhouse_url,callback=self.parse_newhouse,meta={"info":(province, city)})yield scrapy.Request(url=esf_url,callback=self.parse_esf,meta={"info":(province, city)},dont_filter=True)# break# breakdef parse_newhouse(self,response):province,city = response.meta.get('info')lis = response.xpath("//div[contains(@class,'nl_con')]/ul/li")for li in lis:# 獲取 項目名字name = li.xpath(".//div[@class='nlcd_name']/a/text()").get()name = li.xpath(".//div[@class='nlcd_name']/a/text()").get()if name == None:passelse:name = name.strip()# print(name)# 獲取房子類型:幾居house_type_list = li.xpath(".//div[contains(@class,'house_type')]/a/text()").getall()if len(house_type_list) == 0:passelse:house_type_list = list(map(lambda x:re.sub(r"\s","",x),house_type_list))rooms = list(filter(lambda x:x.endswith("居"),house_type_list))# print(rooms)# 獲取房屋面積area = "".join(li.xpath(".//div[contains(@class,'house_type')]/text()").getall())area = re.sub(r"\s|/|-", "", area)if len(area) == 0:passelse:area =area# print(area)# 獲取地址address = li.xpath(".//div[@class='address']/a/@title").get()if address == None:passelse:address = address# print(address)# 獲取區劃分:海淀 朝陽district_text = "".join(li.xpath(".//div[@class='address']/a//text()").getall())if len(district_text) == 0:passelse:district = re.search(r".*\[(.+)\].*",district_text).group(1)# print(district)# 獲取是否在售sale = li.xpath(".//div[contains(@class,'fangyuan')]/span/text()").get()if sale == None:passelse:sale = sale# print(sale)# 獲取價格price = li.xpath(".//div[@class='nhouse_price']//text()").getall()if len(price) == 0:passelse:price = "".join(price)price = re.sub(r"\s|廣告","",price)# print(price)# 獲取網址鏈接origin_url = li.xpath(".//div[@class='nlcd_name']/a/@href").get()if origin_url ==None:passelse:origin_url = origin_url# print(origin_url)item = NewHouseItem(name=name,rooms=rooms,area=area,address=address,district=district,sale=sale,price=price,origin_url=origin_url,province=province,city=city,)yield itemnext_url = response.xpath(".//div[@class='page']//a[@class='next']/@href").get()if next_url:yield scrapy.Request(url=response.urljoin(next_url), callback=self.parse_newhouse,meta={"info":(province,city)})def parse_esf(self, response):# 獲取省份和城市province, city = response.meta.get('info')dls = response.xpath("//div[@class='shop_list shop_list_4']/dl")for dl in dls:item = ESFHouseItem(province=province,city=city)# 獲取小區名字name = dl.xpath(".//p[@class='add_shop']/a/text()").get()if name == None:passelse:item['name'] = name.strip()# print(name)# 獲取綜合信息infos = dl.xpath(".//p[@class='tel_shop']/text()").getall()if len(infos) == 0:passelse:infos = list(map(lambda x:re.sub(r"\s","",x),infos))# print(infos)for info in infos:if "廳" in info :item['rooms']= infoelif '層' in info:item['floor']= infoelif '向' in info:item['toward']=infoelif '年' in info:item['year']=infoelif '㎡' in info:item['area'] = info# print(item)# 獲取地址address = dl.xpath(".//p[@class='add_shop']/span/text()").get()if address == None:passelse:# print(address)item['address'] = address# 獲取總價price = dl.xpath("./dd[@class='price_right']/span[1]/b/text()").getall()if len(price) == 0:passelse:price="".join(price)# print(price)item['price'] = price# 獲取單價unit = dl.xpath("./dd[@class='price_right']/span[2]/text()").get()if unit == None:passelse:# print(unit)item['unit'] = unit# 獲取初始urldetail_url = dl.xpath(".//h4[@class='clearfix']/a/@href").get()if detail_url == None:passelse:origin_url = response.urljoin(detail_url)# print(origin_url)item['origin_url'] = origin_url# print(item)yield itemnext_url = response.xpath(".//div[@class='page_al']/p/a/@href").get()# print(next_url)yield scrapy.Request(url=response.urljoin(next_url),callback=self.parse_esf,meta={"info":(province,city)})middlewares.py:
# -*- coding: utf-8 -*-# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlimport randomclass UserAgentDownloadMiddleware(object):# user-agent隨機請求頭中間件USER_AGENTS = ['Mozilla/5.0 (Windows; U; Windows NT 6.1; rv:2.2) Gecko/20110201''Mozilla/5.0 (Windows; U; Windows NT 5.1; pl; rv:1.9.2.3) Gecko/20100401 Lightningquail/3.6.3''Mozilla/5.0 (X11; ; Linux i686; rv:1.9.2.20) Gecko/20110805''Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.1b3) Gecko/20090305''Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.14) Gecko/2009091010''Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.10) Gecko/2009042523']def process_request(self, request, spider):user_agent = random.choice(self.USER_AGENTS)request.headers['User-Agent'] = user_agent
start.sh:
from scrapy import cmdlinecmdline.execute("scrapy crawl sfw".split())
此時在windows開發環境下運行start.sh,即可正常爬取數據。
五. 部署
1. windows環境下生成requirements.txt文件
打開cmder,首先切換至虛擬化境:
cd C:\Users\fxd.virtualenvs\sipder_env
.\Scripts\activate
然后切換至項目所在目錄,輸入指令,生成requirements.txt文件
pip freeze > requirements.txt
2. xshell連接ubuntu服務器并安裝依賴環境
如果未安裝openssh,需要首先安裝,具體指令如下:
sudo apt-get install openssh-server
連接ubuntu服務器,切換至虛擬環境所在的目錄,執行:
source ./bin/activate
進入虛擬環境,執行:
rz
上傳requirements.txt,執行:
pip install -r requirements.txt
安裝項目依賴環境。
然后安裝scrapy-redis:
pip install scrapy-redis
3. 修改部分代碼
要將一個Scrapy項目變成一個Scrapy-redis項目,只需要修改以下三點:
(1)將爬蟲繼承的類,從scrapy.Spider 變成scrapy_redis.spiders.RedisSpider;或者從scrapy.CrowlSpider變成scrapy_redis.spiders.RedisCrowlSpider。
(2)將爬蟲中的start_urls刪掉,增加一個redis_key="***"。這個key是為了以后在redis中控制爬蟲啟動的,爬蟲的第一個url,就是在redis中通過這個推送出去的。
(3)在配置文件中增加如下配置:
# Scrapy-Redis相關配置
# 確保request存儲到redis中
SCHEDULER = "scrapy_redis.scheduler.Scheduler"# 確保所有的爬蟲共享相同的去重指紋
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"# 設置redis為item_pipeline
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline':300
}# 在redis中保持scrapy_redis用到的隊列,不會清理redis中的隊列,從而可以實現暫停和回復的功能
SCHEDULER_PERSIST = True# 設置連接redis信息
REDIS_HOST = '172.20.10.2'
REDIS_PORT = 6379
4. 上傳代碼至服務器并運行
將項目文件壓縮,在xshell中通過命令rz上傳,并解壓
運行爬蟲:
(1)在爬蟲服務器上,進入爬蟲文件sfw.py所在的路徑,然后輸入命令:scrapy runspider [爬蟲名字]
scrapy runspider sfw.py
(2)在redis(windows)服務器上,開啟redis服務:
redis-server redis.windows.conf
若報錯,按步驟執行以下命令:
redis-cli.exe
shutdown
exit
redis-server.exe redis.windows.conf
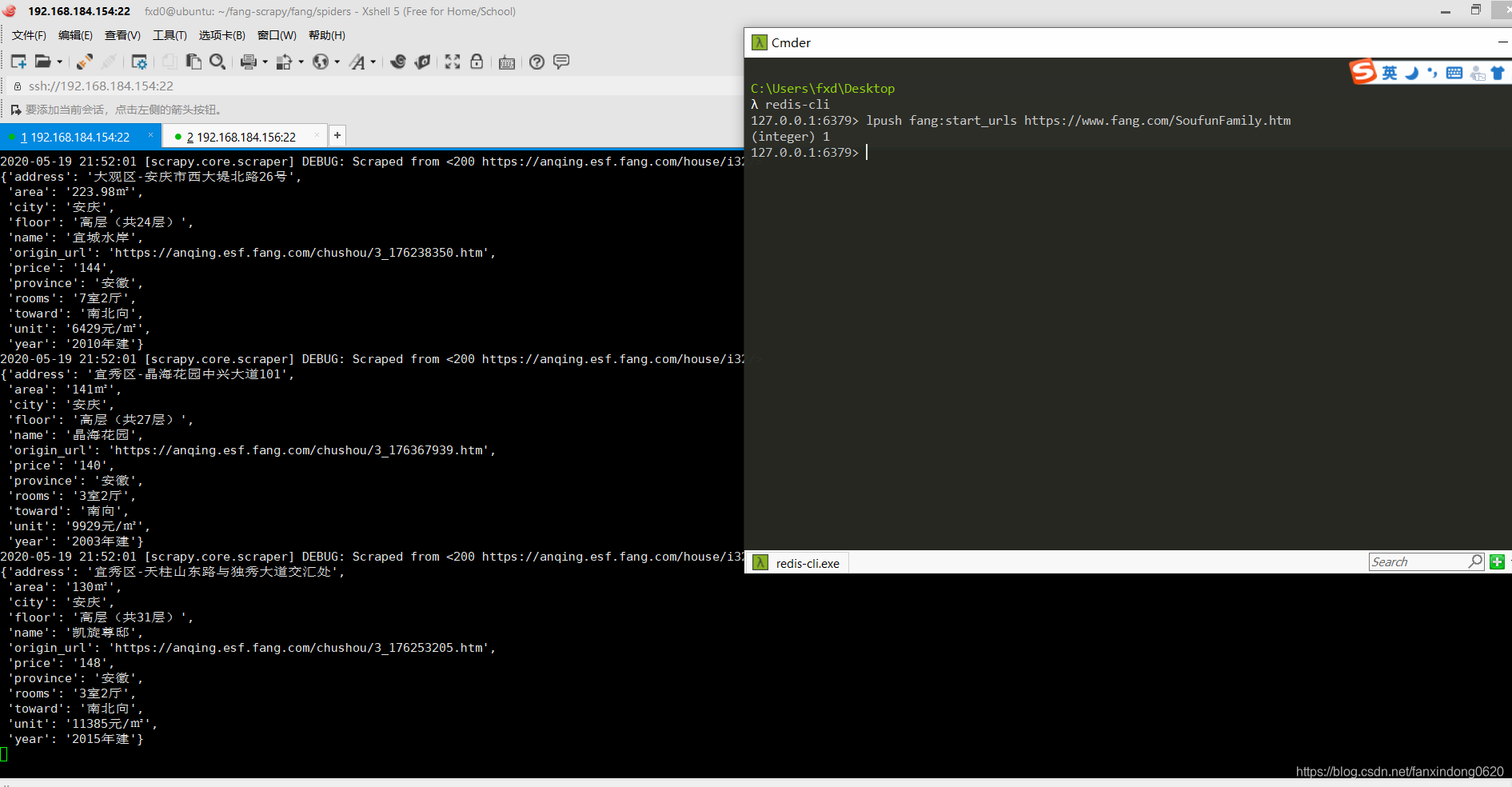
(3)然后打開另外一個windows終端:
redis-cli
推入一個開始的url鏈接:
lpush fang:start_urls https://www.fang.com/SoufunFamily.htm
爬蟲開始
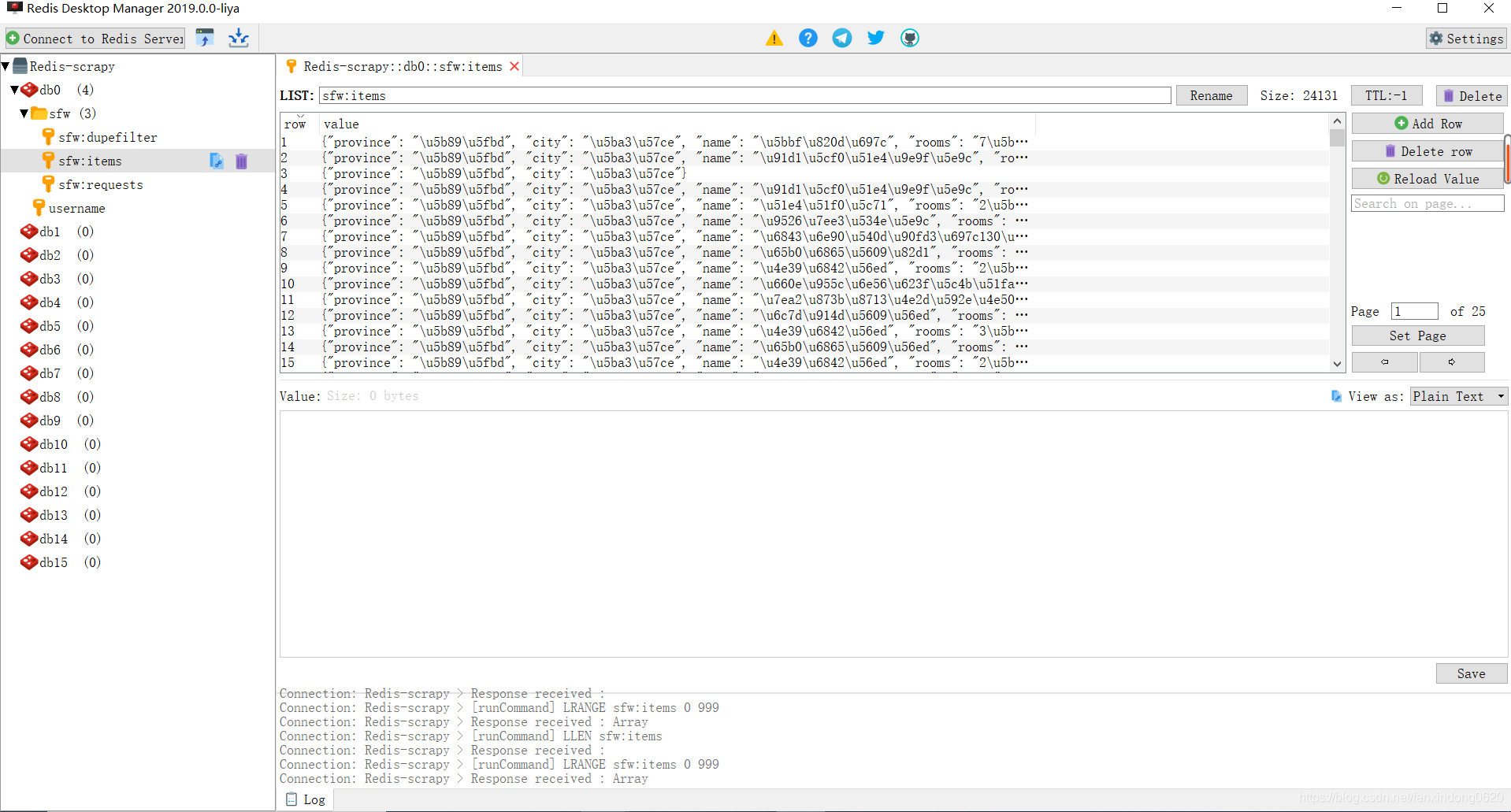
進入RedisDesktopManager查看保存的數據:
另外一臺爬蟲服務器進行同樣的操作。
項目結束!





)



)
![【BZOJ3590】[Snoi2013]Quare 狀壓DP](http://pic.xiahunao.cn/【BZOJ3590】[Snoi2013]Quare 狀壓DP)






)

