前些天發現了一個巨牛的人工智能學習網站,通俗易懂,風趣幽默,忍不住分享一下給大家。點擊跳轉到教程。
本篇進行Spring-data-jpa的介紹,幾乎涵蓋該框架的所有方面,在日常的開發當中,基本上能滿足所有需求。這里不講解JPA和Spring-data-jpa單獨使用,所有的內容都是在和Spring整合的環境中實現。如果需要了解該框架的入門,百度一下,很多入門的介紹。在這篇文章的接下來一篇,會有一個系列來講解mybatis,這個系列從mybatis的入門開始,到基本使用,和spring整合,和第三方插件整合,緩存,插件,最后會持續到mybatis的架構,源碼解釋,重點會介紹幾個重要的設計模式,這樣一個體系。基本上講完之后,mybatis在你面前就沒有了秘密,你能解決mybatis的幾乎所有問題,并且在開發過程中相當的方便,駕輕就熟。
這篇文章由于介紹的類容很全,因此很長,如果你需要,那么可以耐心的看完,本人經歷了很長時間的學識,使用,研究的心血濃縮成為這么短短的一篇博客。
大致整理一個提綱:
1、Spring-data-jpa的基本介紹;
2、和Spring整合;
3、基本的使用方式;
4、復雜查詢,包括多表關聯,分頁,排序等;
現在開始:
1、Spring-data-jpa的基本介紹:JPA誕生的緣由是為了整合第三方ORM框架,建立一種標準的方式,百度百科說是JDK為了實現ORM的天下歸一,目前也是在按照這個方向發展,但是還沒能完全實現。在ORM框架中,Hibernate是一支很大的部隊,使用很廣泛,也很方便,能力也很強,同時Hibernate也是和JPA整合的比較良好,我們可以認為JPA是標準,事實上也是,JPA幾乎都是接口,實現都是Hibernate在做,宏觀上面看,在JPA的統一之下Hibernate很良好的運行。
上面闡述了JPA和Hibernate的關系,那么Spring-data-jpa又是個什么東西呢?這地方需要稍微解釋一下,我們做Java開發的都知道Spring的強大,到目前為止,企業級應用Spring幾乎是無所不能,無所不在,已經是事實上的標準了,企業級應用不使用Spring的幾乎沒有,這樣說沒錯吧。而Spring整合第三方框架的能力又很強,他要做的不僅僅是個最早的IOC容器這么簡單一回事,現在Spring涉及的方面太廣,主要是體現在和第三方工具的整合上。而在與第三方整合這方面,Spring做了持久化這一塊的工作,我個人的感覺是Spring希望把持久化這塊內容也拿下。于是就有了Spring-data-**這一系列包。包括,Spring-data-jpa,Spring-data-template,Spring-data-mongodb,Spring-data-redis,還有個民間產品,mybatis-spring,和前面類似,這是和mybatis整合的第三方包,這些都是干的持久化工具干的事兒。
這里介紹Spring-data-jpa,表示與jpa的整合。
2、我們都知道,在使用持久化工具的時候,一般都有一個對象來操作數據庫,在原生的Hibernate中叫做Session,在JPA中叫做EntityManager,在MyBatis中叫做SqlSession,通過這個對象來操作數據庫。我們一般按照三層結構來看的話,Service層做業務邏輯處理,Dao層和數據庫打交道,在Dao中,就存在著上面的對象。那么ORM框架本身提供的功能有什么呢?答案是基本的CRUD,所有的基礎CRUD框架都提供,我們使用起來感覺很方便,很給力,業務邏輯層面的處理ORM是沒有提供的,如果使用原生的框架,業務邏輯代碼我們一般會自定義,會自己去寫SQL語句,然后執行。在這個時候,Spring-data-jpa的威力就體現出來了,ORM提供的能力他都提供,ORM框架沒有提供的業務邏輯功能Spring-data-jpa也提供,全方位的解決用戶的需求。使用Spring-data-jpa進行開發的過程中,常用的功能,我們幾乎不需要寫一條sql語句,至少在我看來,企業級應用基本上可以不用寫任何一條sql,當然spring-data-jpa也提供自己寫sql的方式,這個就看個人怎么選擇,都可以。我覺得都行。
2.1與Spring整合我們從spring配置文件開始,為了節省篇幅,這里我只寫出配置文件的結構。

<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:context="http://www.springframework.org/schema/context" xmlns:mongo="http://www.springframework.org/schema/data/mongo"xmlns:jpa="http://www.springframework.org/schema/data/jpa"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsdhttp://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.0.xsd http://www.springframework.org/schema/txhttp://www.springframework.org/schema/tx/spring-tx-3.0.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsdhttp://www.springframework.org/schema/data/mongohttp://www.springframework.org/schema/data/mongo/spring-mongo-1.0.xsdhttp://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa.xsd"><!-- 數據庫連接 --><context:property-placeholder location="classpath:your-config.properties" ignore-unresolvable="true" /><!-- service包 --><context:component-scan base-package="your service package" /><!-- 使用cglib進行動態代理 --><aop:aspectj-autoproxy proxy-target-class="true" /><!-- 支持注解方式聲明式事務 --><tx:annotation-driven transaction-manager="transactionManager" proxy-target-class="true" /><!-- dao --><jpa:repositories base-package="your dao package" repository-impl-postfix="Impl" entity-manager-factory-ref="entityManagerFactory" transaction-manager-ref="transactionManager" /><!-- 實體管理器 --><bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"><property name="dataSource" ref="dataSource" /><property name="packagesToScan" value="your entity package" /><property name="persistenceProvider"><bean class="org.hibernate.ejb.HibernatePersistence" /></property><property name="jpaVendorAdapter"><bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"><property name="generateDdl" value="false" /><property name="database" value="MYSQL" /><property name="databasePlatform" value="org.hibernate.dialect.MySQL5InnoDBDialect" /><!-- <property name="showSql" value="true" /> --></bean></property><property name="jpaDialect"><bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect" /></property><property name="jpaPropertyMap"><map><entry key="hibernate.query.substitutions" value="true 1, false 0" /><entry key="hibernate.default_batch_fetch_size" value="16" /><entry key="hibernate.max_fetch_depth" value="2" /><entry key="hibernate.generate_statistics" value="true" /><entry key="hibernate.bytecode.use_reflection_optimizer" value="true" /><entry key="hibernate.cache.use_second_level_cache" value="false" /><entry key="hibernate.cache.use_query_cache" value="false" /></map></property></bean><!-- 事務管理器 --><bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"><property name="entityManagerFactory" ref="entityManagerFactory"/></bean><!-- 數據源 --><bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"><property name="driverClassName" value="${driver}" /><property name="url" value="${url}" /><property name="username" value="${userName}" /><property name="password" value="${password}" /><property name="initialSize" value="${druid.initialSize}" /><property name="maxActive" value="${druid.maxActive}" /><property name="maxIdle" value="${druid.maxIdle}" /><property name="minIdle" value="${druid.minIdle}" /><property name="maxWait" value="${druid.maxWait}" /><property name="removeAbandoned" value="${druid.removeAbandoned}" /><property name="removeAbandonedTimeout" value="${druid.removeAbandonedTimeout}" /><property name="timeBetweenEvictionRunsMillis" value="${druid.timeBetweenEvictionRunsMillis}" /><property name="minEvictableIdleTimeMillis" value="${druid.minEvictableIdleTimeMillis}" /><property name="validationQuery" value="${druid.validationQuery}" /><property name="testWhileIdle" value="${druid.testWhileIdle}" /><property name="testOnBorrow" value="${druid.testOnBorrow}" /><property name="testOnReturn" value="${druid.testOnReturn}" /><property name="poolPreparedStatements" value="${druid.poolPreparedStatements}" /><property name="maxPoolPreparedStatementPerConnectionSize" value="${druid.maxPoolPreparedStatementPerConnectionSize}" /><property name="filters" value="${druid.filters}" /></bean><!-- 事務 --><tx:advice id="txAdvice" transaction-manager="transactionManager"><tx:attributes><tx:method name="*" /><tx:method name="get*" read-only="true" /><tx:method name="find*" read-only="true" /><tx:method name="select*" read-only="true" /><tx:method name="delete*" propagation="REQUIRED" /><tx:method name="update*" propagation="REQUIRED" /><tx:method name="add*" propagation="REQUIRED" /><tx:method name="insert*" propagation="REQUIRED" /></tx:attributes></tx:advice><!-- 事務入口 --><aop:config><aop:pointcut id="allServiceMethod" expression="execution(* your service implements package.*.*(..))" /><aop:advisor pointcut-ref="allServiceMethod" advice-ref="txAdvice" /></aop:config></beans>
2.2對上面的配置文件進行簡單的解釋,只對“實體管理器”和“dao”進行解釋,其他的配置在任何地方都差不太多。
1.對“實體管理器”解釋:我們知道原生的jpa的配置信息是必須放在META-INF目錄下面的,并且名字必須叫做persistence.xml,這個叫做persistence-unit,就叫做持久化單元,放在這下面我們感覺不方便,不好,于是Spring提供了
org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean這樣一個類,可以讓你的隨心所欲的起這個配置文件的名字,也可以隨心所欲的修改這個文件的位置,只需要在這里指向這個位置就行。然而更加方便的做法是,直接把配置信息就寫在這里更好,于是就有了這實體管理器這個bean。使用
<property name="packagesToScan" value="your entity package" />這個屬性來加載我們的entity。
2.3 解釋“dao”這個bean。這里衍生一下,進行一下名詞解釋,我們知道dao這個層叫做Data Access Object,數據庫訪問對象,這是一個廣泛的詞語,在jpa當中,我們還有一個詞語叫做Repository,這里我們一般就用Repository結尾來表示這個dao,比如UserDao,這里我們使用UserRepository,當然名字無所謂,隨意取,你可以意會一下我的意思,感受一下這里的含義和區別,同理,在mybatis中我們一般也不叫dao,mybatis由于使用xml映射文件(當然也提供注解,但是官方文檔上面表示在有些地方,比如多表的復雜查詢方面,注解還是無解,只能xml),我們一般使用mapper結尾,比如我們也不叫UserDao,而叫UserMapper。
上面拓展了一下關于dao的解釋,那么這里的這個配置信息是什么意思呢?首先base-package屬性,代表你的Repository接口的位置,repository-impl-postfix屬性代表接口的實現類的后綴結尾字符,比如我們的UserRepository,那么他的實現類就叫做UserRepositoryImpl,和我們平時的使用習慣完全一致,于此同時,spring-data-jpa的習慣是接口和實現類都需要放在同一個包里面(不知道有沒有其他方式能分開放,這不是重點,放在一起也無所謂,影響不大),再次的,這里我們的UserRepositoryImpl這個類的定義的時候我們不需要去指定實現UserRepository接口,根據spring-data-jpa自動就能判斷二者的關系。
比如:我們的UserRepository和UserRepositoryImpl這兩個類就像下面這樣來寫。
public interface UserRepository extends JpaRepository<User, Integer>{}
public class UserRepositoryImpl {}那么這里為什么要這么做呢?原因是:spring-data-jpa提供基礎的CRUD工作,同時也提供業務邏輯的功能(前面說了,這是該框架的威力所在),所以我們的Repository接口要做兩項工作,繼承spring-data-jpa提供的基礎CRUD功能的接口,比如JpaRepository接口,同時自己還需要在UserRepository這個接口中定義自己的方法,那么導致的結局就是UserRepository這個接口中有很多的方法,那么如果我們的UserRepositoryImpl實現了UserRepository接口,導致的后果就是我們勢必需要重寫里面的所有方法,這是Java語法的規定,如此一來,悲劇就產生了,UserRepositoryImpl里面我們有很多的@Override方法,這顯然是不行的,結論就是,這里我們不用去寫implements部分。
spring-data-jpa實現了上面的能力,那他是怎么實現的呢?這里我們通過源代碼的方式來呈現他的來龍去脈,這個過程中cglib發揮了杰出的作用。
在spring-data-jpa內部,有一個類,叫做
public class SimpleJpaRepository<T, ID extends Serializable> implements JpaRepository<T, ID>,JpaSpecificationExecutor<T>我們可以看到這個類是實現了JpaRepository接口的,事實上如果我們按照上面的配置,在同一個包下面有UserRepository,但是沒有UserRepositoryImpl這個類的話,在運行時期UserRepository這個接口的實現就是上面的SimpleJpaRepository這個接口。而如果有UserRepositoryImpl這個文件的話,那么UserRepository的實現類就是UserRepositoryImpl,而UserRepositoryImpl這個類又是SimpleJpaRepository的子類,如此一來就很好的解決了上面的這個不用寫implements的問題。我們通過閱讀這個類的源代碼可以發現,里面包裝了entityManager,底層的調用關系還是entityManager在進行CRUD。
3. 下面我們通過一個完整的項目來基本使用spring-data-jpa,然后我們在介紹他的高級用法。
a.數據庫建表:user,主鍵自增

b.對應實體:User
@Entity
@Table(name = "user")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Integer id;private String name;private String password;private String birthday;// getter,setter
}
c.簡歷UserRepository接口
public interface UserRepository extends JpaRepository<User, Integer>{}通過上面3步,所有的工作就做完了,User的基礎CRUD都能做了,簡約而不簡單。
d.我們的測試類UserRepositoryTest
public class UserRepositoryTest {@Autowiredprivate UserRepository userRepository;@Testpublic void baseTest() throws Exception {User user = new User();user.setName("Jay");user.setPassword("123456");user.setBirthday("2008-08-08");userRepository.save(user);
// userRepository.delete(user);
// userRepository.findOne(1);}
}
測試通過。
說到這里,和spring已經完成。接下來第三點,基本使用。
4.前面把基礎的東西說清楚了,接下來就是spring-data-jpa的正餐了,真正威力的地方。
4.1 我們的系統中一般都會有用戶登錄這個接口,在不使用spring-data-jpa的時候我們怎么做,首先在service層定義一個登錄方法。如:
User login(String name, String password);然后在serviceImpl中寫該方法的實現,大致這樣:
@Overridepublic User login(String name, String password) {return userDao.login(name, password);}接下來,UserDao大概是這么個樣子:
User getUserByNameAndPassword(String name, String password);然后在UserDaoImpl中大概是這么個樣子:
public User getUserByNameAndPassword(String name, String password) {Query query = em.createQuery("select * from User t where t.name = ?1 and t.password = ?2");query.setParameter(1, name);query.setParameter(2, password);return (User) query.getSingleResult();}ok,這個代碼運行良好,那么這樣子大概有十來行代碼,我們感覺這個功能實現了,很不錯。然而這樣子真正簡捷么?如果這樣子就滿足了,那么spring-data-jpa就沒有必要存在了,前面提到spring-data-jpa能夠幫助你完成業務邏輯代碼的處理,那他是怎么處理的呢?這里我們根本不需要UserDaoImpl這個類,只需要在UserRepository接口中定義一個方法
User findByNameAndPassword(String name, String password);然后在service中調用這個方法就完事了,所有的邏輯只需要這么一行代碼,一個沒有實現的接口方法。通過debug信息,我們看到輸出的sql語句是
select * from user where name = ? and password = ?跟上面的傳統方式一模一樣的結果。這簡單到令人發指的程度,那么這一能力是如何實現的呢?原理是:spring-data-jpa會根據方法的名字來自動生成sql語句,我們只需要按照方法定義的規則即可,上面的方法findByNameAndPassword,spring-data-jpa規定,方法都以findBy開頭,sql的where部分就是NameAndPassword,被spring-data-jpa翻譯之后就編程了下面這種形態:
where name = ? and password = ?在舉個例,如果是其他的操作符呢,比如like,前端模糊查詢很多都是以like的方式來查詢。比如根據名字查詢用戶,sql就是
select * from user where name like = ?這里spring-data-jpa規定,在屬性后面接關鍵字,比如根據名字查詢用戶就成了
User findByNameLike(String name);被翻譯之后的sql就是
select * from user where name like = ?這也是簡單到令人發指,spring-data-jpa所有的語法規定如下圖: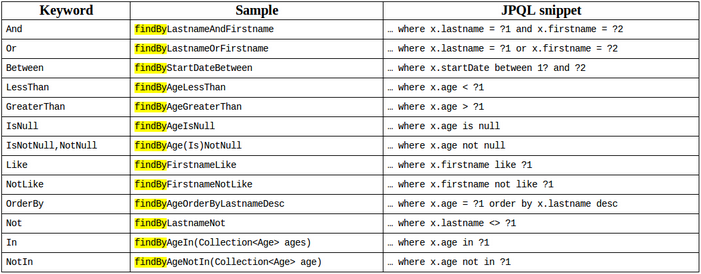
通過上面,基本CRUD和基本的業務邏輯操作都得到了解決,我們要做的工作少到僅僅需要在UserRepository接口中定義幾個方法,其他所有的工作都由spring-data-jpa來完成。
?接下來:就是比較復雜的操作了,比如動態查詢,分頁,下面詳細介紹spring-data-jpa的第二大殺手锏,強大的動態查詢能力。
在上面的介紹中,對于我們傳統的企業級應用的基本操作已經能夠基本上全部實現,企業級應用一般都會有一個模糊查詢的功能,并且是多條的查詢,在有查詢條件的時候我們需要在where后面接上一個 xxx = yyy 或者 xxx like '% + yyy + %'類似這樣的sql。那么我們傳統的JDBC的做法是使用很多的if語句根據傳過來的查詢條件來拼sql,mybatis的做法也類似,由于mybatis有強大的動態xml文件的標簽,在處理這種問題的時候顯得非常的好,但是二者的原理都一致,那spring-data-jpa的原理也同樣很類似,這個道理也就說明了解決多表關聯動態查詢根兒上也就是這么回事。
那么spring-data-jpa的做法是怎么的呢?有兩種方式。可以選擇其中一種,也可以結合使用,在一般的查詢中使用其中一種就夠了,就是第二種,但是有一類查詢比較棘手,比如報表相關的,報表查詢由于涉及的表很多,這些表不一定就是兩兩之間有關系,比如字典表,就很獨立,在這種情況之下,使用拼接sql的方式要容易一些。下面分別介紹這兩種方式。
a.使用JPQL,和Hibernate的HQL很類似。
前面說道了在UserRepository接口的同一個包下面建立一個普通類UserRepositoryImpl來表示該類的實現類,同時前面也介紹了完全不需要這個類的存在,但是如果使用JPQL的方式就必須要有這個類。如下:
public class StudentRepositoryImpl {@PersistenceContextprivate EntityManager em;@SuppressWarnings("unchecked")public Page<Student> search(User user) {String dataSql = "select t from User t where 1 = 1";String countSql = "select count(t) from User t where 1 = 1";if(null != user && !StringUtils.isEmpty(user.getName())) {dataSql += " and t.name = ?1";countSql += " and t.name = ?1";}Query dataQuery = em.createQuery(dataSql);Query countQuery = em.createQuery(countSql);if(null != user && !StringUtils.isEmpty(user.getName())) {dataQuery.setParameter(1, user.getName());countQuery.setParameter(1, user.getName());}long totalSize = (long) countQuery.getSingleResult();Page<User> page = new Page();page.setTotalSize(totalSize);List<User> data = dataQuery.getResultList();page.setData(data);return page;}}
通過上面的方法,我們查詢并且封裝了一個User對象的分頁信息。代碼能夠良好的運行。這種做法也是我們傳統的經典做法。那么spring-data-jpa還有另外一種更好的方式,那就是所謂的類型檢查的方式,上面我們的sql是字符串,沒有進行類型檢查,而下面的方式就使用了類型檢查的方式。這個道理在mybatis中也有體現,mybatis可以使用字符串sql的方式,也可以使用接口的方式,而mybatis的官方推薦使用接口方式,因為有類型檢查,會更安全。
b.使用JPA的動態接口,下面的接口我把注釋刪了,為了節省篇幅,注釋也沒什么用,看方法名字大概都能猜到是什么意思。
public interface JpaSpecificationExecutor<T> {T findOne(Specification<T> spec);List<T> findAll(Specification<T> spec);Page<T> findAll(Specification<T> spec, Pageable pageable);List<T> findAll(Specification<T> spec, Sort sort);long count(Specification<T> spec);
}
?上面說了,使用這種方式我們壓根兒就不需要UserRepositoryImpl這個類,說到這里,仿佛我們就發現了spring-data-jpa為什么把Repository和RepositoryImpl文件放在同一個包下面,因為我們的應用很可能根本就一個Impl文件都不存在,那么在那個包下面就只有一堆接口,即使把Repository和RepositoryImpl都放在同一個包下面,也不會造成這個包下面有正常情況下2倍那么多的文件,根本原因:只有接口而沒有實現類。
上面我們的UserRepository類繼承了JpaRepository和JpaSpecificationExecutor類,而我們的UserRepository這個對象都會注入到UserService里面,于是如果使用這種方式,我們的邏輯直接就寫在service里面了,下面的代碼:一個學生Student類,一個班級Clazz類,Student里面有一個對象Clazz,在數據庫中是clazz_id,這是典型的多對一的關系。我們在配置好entity里面的關系之后。就可以在StudentServiceImpl類中做Student的模糊查詢,典型的前端grid的模糊查詢。代碼是這樣子的:
@Service
public class StudentServiceImpl extends BaseServiceImpl<Student> implements StudentService {@Autowiredprivate StudentRepository studentRepository;@Overridepublic Student login(Student student) {return studentRepository.findByNameAndPassword(student.getName(), student.getPassword());}@Overridepublic Page<Student> search(final Student student, PageInfo page) {return studentRepository.findAll(new Specification<Student>() {@Overridepublic Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) {Predicate stuNameLike = null;if(null != student && !StringUtils.isEmpty(student.getName())) {// 這里也可以root.get("name").as(String.class)這種方式來強轉泛型類型stuNameLike = cb.like(root.<String> get("name"), "%" + student.getName() + "%");}Predicate clazzNameLike = null;if(null != student && null != student.getClazz() && !StringUtils.isEmpty(student.getClazz().getName())) {clazzNameLike = cb.like(root.<String> get("clazz").<String> get("name"), "%" + student.getClazz().getName() + "%");}if(null != stuNameLike) query.where(stuNameLike);if(null != clazzNameLike) query.where(clazzNameLike);return null;}}, new PageRequest(page.getPage() - 1, page.getLimit(), new Sort(Direction.DESC, page.getSortName())));}
}
先解釋下這里的意思,然后我們在結合框架的源碼來深入分析。
這里我們是2個表關聯查詢,查詢條件包括Student表和Clazz表,類似的2個以上的表方式差不多,但是正如上面所說,這種做法適合所有的表都是兩兩能夠關聯上的,涉及的表太多,或者是有一些字典表,那就使用sql拼接的方式,簡單一些。
先簡單解釋一下代碼的含義,然后結合框架源碼來詳細分析。兩個Predicate對象,Predicate按照中文意思是判斷,斷言的意思,那么放在我們的sql中就是where后面的東西,比如
name like '% + jay + %';下面的PageRequest代表分頁信息,PageRequest里面的Sort對象是排序信息。上面的代碼事實上是在動態的組合最終的sql語句,這里使用了一個策略模式,或者callback,就是
studentRepository.findAll(一個接口)studentRepository接口方法調用的參數是一個接口,而接口的實現類調用這個方法的時候,在內部,參數對象的實現類調用自己的toPredicate這個方法的實現內容,可以體會一下這里的思路,就是傳一個接口,然后接口的實現自己來定義,這個思路在nettyJavaScript中體現的特別明顯,特別是JavaScript的框架中大量的這種方式,JS框架很多的做法都是上來先閉包,和瀏覽器的命名空間分開,然后入口方法就是一個回調,比如ExtJS:
Ext.onReady(function() {// xxx
});參數是一個function,其實在框架內部就調用了這個參數,于是這個這個方法執行了。這種模式還有一個JDK的排序集合上面也有體現,我們的netty框架也采用這種方式來實現異步IO的能力。
接下來結合框架源碼來詳細介紹這種機制,以及這種機制提供給我們的好處。
?這里首先從JPA的動態查詢開始說起,在JPA提供的API中,動態查詢大概有這么一些方法,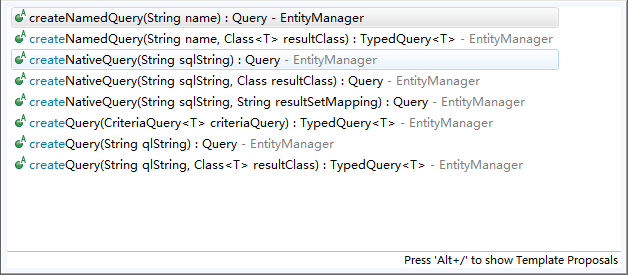
從名字大概可以看出這些方法的意義,跟Hibernate或者一些其他的工具也都差不多,這里我們介紹參數為CriteriaQuery類型的這個方法,如果我們熟悉多種ORM框架的話,不難發現都有一個Criteria類似的東西,中文意思是“條件”的意思,這就是各個框架構建動態查詢的主體,Hibernate甚至有兩種,在線和離線兩種Criteria,mybatis也能從Example中創建Criteria,并且添加查詢條件。
那么第一步就需要構建出這個參數CriteriaQuery類型的參數,這里使用建造者模式,
CriteriaBuilder builder = em.getCriteriaBuilder();
CriteriaQuery<Student> query = builder.createQuery(Student.class);接下來:
Root<Student> root = query.from(Student.class);在這里,我們看方法名from,意思是獲取Student的Root,其實也就是個Student的包裝對象,就代表這條sql語句里面的主體。接下來:
Predicate p1 = builder.like(root.<String> get("name"), "%" + student.getName() + "%");Predicate p2 = builder.equal(root.<String> get("password"), student.getPassword());Predicate是判斷的意思,放在sql語句中就是where后面 xxx = yyy, xxx like yyy這種,也就是查詢條件,這里構造了2個查詢條件,分別是根據student的name屬性進行like查詢和根據student的password進行“=”查詢,在sql中就是
name like = ? and password = ?這種形式,接下來
query.where(p1, p2);這樣子一個完整的動態查詢就構建完成了,接下來調用getSingleResult或者getResultList返回結果,這里jpa的單個查詢如果為空的話會報異常,這點感覺框架設計的不好,如果查詢為空直接返回一個null或者一個空的List更好一點。
這是jpa原生的動態查詢方式,過程大致就是,創建builder => 創建Query => 構造條件 => 查詢。這么4個步驟,這里代碼運行良好,如果不使用spring-data-jpa,我們就需要這么來做,但是spring-data-jpa幫我們做得更為徹底,從上面的4個步驟中,我們發現:所有的查詢除了第三步不一樣,其他幾步都是一模一樣的,不使用spring-data-jpa的情況下,我們要么4步驟寫完,要么自己寫個工具類,封裝一下,這里spring-data-jpa就是幫我們完成的這樣一個動作,那就是在JpaSpecification<T>這個接口中的
Page<T> findAll(Specification<T> spec, Pageable pageable);這個方法,前面說了,這是個策略模式,參數spec是個接口,前面也說了框架內部對于這個接口有默認的實現類
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository<T, ID extends Serializable> implements JpaRepository<T, ID>,JpaSpecificationExecutor<T> {},我們的Repository接口就是繼承這個接口,而通過cglib的RepositoryImpl的代理類也是這個類的子類,默認也就實現了該方法。這個方法的方法體是這樣的:
/** (non-Javadoc)* @see org.springframework.data.jpa.repository.JpaSpecificationExecutor#findOne(org.springframework.data.jpa.domain.Specification)*/public T findOne(Specification<T> spec) {try {return getQuery(spec, (Sort) null).getSingleResult();} catch (NoResultException e) {return null;}}
這里的
getQuery(spec, (Sort) null)返回類型是
TypedQuery<T>進入這個getQuery方法:
/*** Creates a {@link TypedQuery} for the given {@link Specification} and {@link Sort}.* * @param spec can be {@literal null}.* @param sort can be {@literal null}.* @return*/protected TypedQuery<T> getQuery(Specification<T> spec, Sort sort) {CriteriaBuilder builder = em.getCriteriaBuilder();CriteriaQuery<T> query = builder.createQuery(getDomainClass());Root<T> root = applySpecificationToCriteria(spec, query);query.select(root);if (sort != null) {query.orderBy(toOrders(sort, root, builder));}return applyRepositoryMethodMetadata(em.createQuery(query));}
一切玄機盡收眼底,這個方法的內容和我們前面使用原生jpa的api的過程是一樣的,而再進入
Root<T> root = applySpecificationToCriteria(spec, query);這個方法:
/*** Applies the given {@link Specification} to the given {@link CriteriaQuery}.* * @param spec can be {@literal null}.* @param query must not be {@literal null}.* @return*/private <S> Root<T> applySpecificationToCriteria(Specification<T> spec, CriteriaQuery<S> query) {Assert.notNull(query);Root<T> root = query.from(getDomainClass());if (spec == null) {return root;}CriteriaBuilder builder = em.getCriteriaBuilder();Predicate predicate = spec.toPredicate(root, query, builder);if (predicate != null) {query.where(predicate);}return root;}
我們可以發現spec參數調用了toPredicate方法,也就是我們前面service里面匿名內部類的實現。
到這里spring-data-jpa的默認實現已經完全明了。總結一下使用動態查詢:前面說的原生api需要4步,而使用spring-data-jpa只需要一步,那就是重寫匿名內部類的toPredicate方法。在重復一下上面的Student和Clazz的查詢代碼,
1 @Override2 public Page<Student> search(final Student student, PageInfo page) {4 return studentRepository.findAll(new Specification<Student>() {5 @Override6 public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) {7 8 Predicate stuNameLike = null;9 if(null != student && !StringUtils.isEmpty(student.getName())) {
10 stuNameLike = cb.like(root.<String> get("name"), "%" + student.getName() + "%");
11 }
12
13 Predicate clazzNameLike = null;
14 if(null != student && null != student.getClazz() && !StringUtils.isEmpty(student.getClazz().getName())) {
15 clazzNameLike = cb.like(root.<String> get("clazz").<String> get("name"), "%" + student.getClazz().getName() + "%");
16 }
17
18 if(null != stuNameLike) query.where(stuNameLike);
19 if(null != clazzNameLike) query.where(clazzNameLike);
20 return null;
21 }
22 }, new PageRequest(page.getPage() - 1, page.getLimit(), new Sort(Direction.DESC, page.getSortName())));
23 }
到這里位置,spring-data-jpa的介紹基本上就完成了,涵蓋了該框架使用的方方面面。接下來還有一塊比較實用的東西,我們看到上面第15行位置的條件查詢,這里使用了一個多級的get,這個是spring-data-jpa支持的,就是嵌套對象的屬性,這種做法一般我們叫方法的級聯調用,就是調用的時候返回自己本身,這個在處理xml的工具中比較常見,主要是為了代碼的美觀作用,沒什么其他的用途。
最后還有一個小問題,我們上面說了使用動態查詢和JPQL兩種方式都可以,在我們使用JPQL的時候,他的語法和常規的sql有點不太一樣,以Student、Clazz關系為例,比如:
select * from student t left join clazz tt on t.clazz_id = tt.id這是一個很常規的sql,但是JPQL是這么寫:
select t from Student t left join t.clazz ttleft join右邊直接就是t的屬性,并且也沒有了on t.clazz_id == tt.id,然而并不會出現笛卡爾積,這里解釋一下為什么沒有這個條件,在我們的實體中配置了屬性的映射關系,并且ORM框架的最核心的目的就是要讓我們以面向對象的方式來操作數據庫,顯然我們在使用這些框架的時候就不需要關心數據庫了,只需要關系對象,而t.clazz_id = tt.id這個是數據庫的字段,由于配置了字段映射,框架內部自己就會去處理,所以不需要on t.clazz_id = tt.id就是合理的。
前面介紹了spring-data-jpa的使用,還有一點忘了,悲觀所和樂觀鎖問題,這里的樂觀鎖比較簡單,jpa有提供注解@Version,加上該注解,自動實現樂觀鎖,byId修改的時候sql自動變成:update ... set ... where id = ? and version = ?,比較方便。
?in操作的查詢:
在日常手動寫sql的時候有in這種查詢是比較多的,比如select * from user t where t.id in (1, 2, 3);有人說in的效率不高,要少用,但是其實只要in是主鍵,或者說是帶有索引的,效率是很高的,mysql中如果in是子查詢貌似不會走索引,不過我個人經驗,在我遇到的實際應用中,in(ids)這種是比較多的,所以一般來說是沒有性能問題的。
那么,sql里面比較好寫,但是如果使用spring-data-jpa的動態查詢方式呢,就和前面的稍微有點區別。大致上是這么一個思路:
if(!CollectionUtils.isEmpty(ids)) {In<Long> in = cb.in(root.<Long> get("id"));for (Long id : parentIds) {in.value(id);}query.where(in);
}
cb創建一個in的Predicate,然后給這個in賦值,最后把in加到where條件中。
手動配置鎖:
spring-data-jpa支持注解方式的sql,比如:@Query(xxx),另外,關于鎖的問題,在實體中的某個字段配置@Version是樂觀鎖,有時候為了使用一個悲觀鎖,或者手動配置一個樂觀鎖(如果實體中沒有version字段),那么可以使用@Lock這個注解,它能夠被解析成為相關的鎖。
一對多、多對多查詢(查詢條件在關聯對象中時):
1、在JPA中,一個實體中如果存在多個關聯對象,那么不能同時eager獲取,只能有一個是eager獲取,其他只能lazy;在Hibernate當中有幾種獨有的解決方法,在JPA當中有2中方法,i.就是前面的改成延時加載;ii.把關聯對象的List改成Set(List允許重復,在多層抓去的時候無法完成映射,Hibernate默認抓去4層,在第三層的時候如果是List就無法完成映射)。
2、在多對多的查詢中,我們可以使用JPQL,也可以使用原生SQL,同時還可以使用動態查詢,這里介紹多對多的動態查詢,這里有一個條件比較苛刻,那就是查詢參數是關聯對象的屬性,一對多類似,多對一可以利用上面介紹的級聯獲取屬性的方式。這里介紹這種方式的目的是為了更好的利用以面向對象的方式進行動態查詢。
舉例:2張表,分別是Employee(id, name)和Company(id, name),二者是多對多的關系,那么當查詢Employee的時候,條件是更具公司名稱。那么做法如下:
@Overridepublic List<Employee> findByCompanyName(final String companyName) {List<Employee> employeeList = employeeRepository.findAll(new Specification<Employee>() {public Predicate toPredicate(Root<Employee> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
// ListJoin<Employee, Company> companyJoin = root.join(root.getModel().getList("companyList", Company.class), JoinType.LEFT);Join<Employee, Company> companyJoin = root.join("companyList", JoinType.LEFT);return cb.equal(companyJoin.get("name"), companyName);}});return employeeList;}
? 我們可以使用上面注釋掉的方式,也可以使用下面這種比較簡單的方式。因為我個人的習慣是盡量不去寫DAO的實現類,除非查詢特別復雜,萬不得已的情況下采用,否則我個人比較偏向于這種方式。
上面的情況如果更為極端的話,關聯多個對象,可以按照下面的方式:
@Overridepublic List<Employee> findByCompanyName(final String companyName, final String wage) {List<Employee> employeeList = employeeRepository.findAll(new Specification<Employee>() {public Predicate toPredicate(Root<Employee> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
// ListJoin<Employee, Company> companyJoin = root.join(root.getModel().getList("companyList", Company.class), JoinType.LEFT);Join<Employee, Company> companyJoin = root.join("companySet", JoinType.LEFT);Join<Employee, Wage> wageJoin = root.join("wageSet", JoinType.LEFT);Predicate p1 = cb.equal(companyJoin.get("name"), companyName);Predicate p2 = cb.equal(wageJoin.get("name"), wage);
// return cb.and(p1, p2);根據spring-data-jpa的源碼,可以返回一個Predicate,框架內部會自動做query.where(p)的操作,也可以直接在這里處理,然后返回null,/// 也就是下面一段源碼中的實現query.where(p1, p2);return null;}});return employeeList;}
/*** Applies the given {@link Specification} to the given {@link CriteriaQuery}.* * @param spec can be {@literal null}.* @param query must not be {@literal null}.* @return*/private <S> Root<T> applySpecificationToCriteria(Specification<T> spec, CriteriaQuery<S> query) {Assert.notNull(query);Root<T> root = query.from(getDomainClass());if (spec == null) {return root;}CriteriaBuilder builder = em.getCriteriaBuilder();Predicate predicate = spec.toPredicate(root, query, builder);// 這里如果我們重寫的toPredicate方法的返回值predicate不為空,那么調用query.where(predicate)if (predicate != null) {query.where(predicate);}return root;}
?
說明:雖然說JPA中這種方式查詢會存在著多次級聯查詢的問題,對性能有所影響,但是在一般的企業級應用當中,為了開發的便捷,這種性能犧牲一般來說是可以接受的。
特別的:在一對多中或者多對一中,即便是fetch為eager,也會先查詢主對象,再查詢關聯對象,但是在eager的情況下雖然是有多次查詢問題,但是沒有n+1問題,關聯對象不會像n+1那樣多查詢n次,而僅僅是把關聯對象一次性查詢出來,因此,在企業級應用當中,訪問量不大的情況下一般來說沒什么問題。
補充一段題外話,關于Hibernate/JPA/Spring-Data-Jpa與MyBatis的區別聯系,這種話題很多討論,對于Hibernate/JPA/Spring-Data-Jpa,我個人而言基本上能夠熟練使用,談不上精通,對于mybatis,由于深入閱讀過幾次它的源碼,對mybatis的設計思想以及細化到具體的方法,屬性,參數算是比較熟悉,也開發過一些mybatis的相關插件。對于這兩個持久化框架,總體來說的區別是,Hibernate系列的門檻相對較高,配置比較多,相對來說難度要大一些,主要體現在各種關系的問題上,據我所知,很多人的理解其實并不深刻,很多時候甚至配置得有一定的問題,但是優勢也很明顯,SQL自動生成,改數據庫表結構僅僅需要調整幾個注解就行了,在熟練使用的基礎上相對來說要便捷一點。對于mybatis來說,門檻很低,真的很低,低到分分鐘就能入門的程度,我個人最喜歡也是mybatis最吸引人的地方就是靈活,特別的靈活,但是修改數據庫表結構之后需要調整的地方比較多,但是利用目前比較優秀的插件,對于單表操作也基本上能夠達到和Hibernate差不多的境界(會稍微犧牲一點點性能),多表的情況下就要麻煩一點。性能方面的比較,由于我沒做過測試,不太好比較,不過應該mybatis要稍微高一些,畢竟他的查詢SQL可控一些(當然Hibernate也支持原生sql,但是對結果集的處理不夠友好)。
?
不知道最初的出處,轉自同樣轉載的:http://blog.csdn.net/mendeliangyang/article/details/52366799

?)
、rank()、dense_rank() 的區別)
)

?)


)



)






