轉自:https://blog.csdn.net/jaster_wisdom/article/details/78240949#commentBox
1.區分一下易混淆的兩個概念,梯度下降和隨機梯度下降:
? ? ? ? 梯度下降:一次將誤分類集合中所有誤分類點的梯度下降;
? ? ? ? 隨機梯度下降:隨機選取一個誤分類點使其梯度下降。
2.對于誤分類的數據來說,當w*xi + b>0時,yi = -1,也就是,明明是正例,預測成負例。因此,誤分類點到超平面的距離為:

?因此所有誤分類點到超平面的總距離為:

?忽略1/||w||,我們就可以得到感知機學習的損失函數。
?3.損失函數

4.對偶形式
?對偶形式的一般性描述:
輸出Ni,b;?感知機模型為:
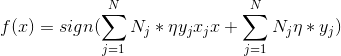
(1)Ni = 0
(2)在訓練集中選取數據(xi,yi)
(3)若

則更新:
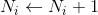
?(4)轉至(2)直到沒有誤分類的數據。
為了方便后期的計算,可先求出Gram矩陣。
? ? ? ? ??? ? ? ? ? ? ? ? ? ? ? ?

?例如,正例:x1 = (3,3)^T, x2 = (4,3)^T, 負例: x3 = (1,1)^T
? 那么Gram矩陣就是:
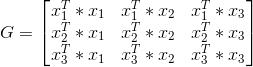
因為對偶形式中會大量用到xi*xj的值,所以提前求出Gram矩陣會方便很多。



![go語言漸入佳境[6]-operator運算符](http://pic.xiahunao.cn/go語言漸入佳境[6]-operator運算符)
的調用時機)
)


)










