本文根據京東微信手Q業務部馬老師在京東\u0026amp;DataFun Talk算法架構系列活動中所分享的《京東購物在微信等場景下的算法應用實踐》編輯整理而成,在未改變原意的基礎上稍做修改。
此次分享的是以WQ(微信手Q)購物智能推薦系統介紹智能推薦算法在實際中的應用,介紹的WQ購物從海量服務到簡單的個性服務到現在的個性化服務發展歷程。他從以下四個部分進行了介紹。
首先講解了WQ個性化推薦有哪些產品、有哪些業務;第二部分講如何構建WQ推薦平臺,如何支持這些業務需求;第三部分簡單介紹了用戶畫像(用戶畫像、物料畫像);最后講解WQ大數據平臺如何搭建。通過這次講解讓大家對推薦系統搭建流程有個初步了解,使大家能夠在3-5天時間里通過這種開源框架搭建一個自己的小型推薦系統。
1. WQ個性化推薦
WQ個性化推薦在微信購物界面體現的方方面面,主要有關鍵詞推薦(新用戶主要通過上下文信息推薦,準確度不是很高)、素材推薦(入口圖、焦點圖、品牌特賣)、商品(賣場、秒殺、拼購等)資訊(趣好貨、購物圈)以及其他如猜你喜歡、類目入口(由于手機屏幕大小原因,條目不能全部顯示,智能通過用戶興趣選擇用戶感興趣的條目)欄目館區等,具體見下圖。
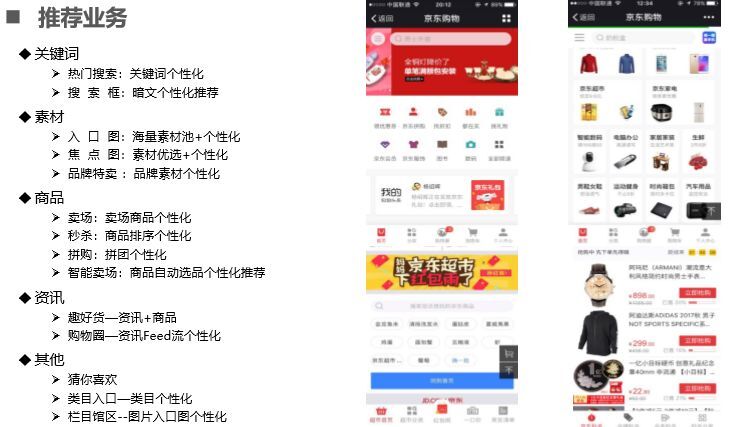
WQ這些海量個性化推薦業務主要由ABC(AI人工智能、BigData大數據、Cloud云服務)技術支持,主要解決用戶體驗問題,運營效率問題、業務效果問題。如金手指(熱搜詞+規則+推薦)的下單轉化率提升為200%-400%,隨著時間略有波動,熱搜詞采用插件式接入(加載js插件,依據你頁面上下文,類目進行熱搜詞推薦),簡單易用;智能賣場由原先運營人員和商家談判、選品、上線,周期為兩人一周構建賣場,通過ABC基于算法、基于不同規則生成不同智能賣場只需一個人員10分鐘就能完成,而且程序自動維護,解決效率問題;入口圖(素材)這一方面主要解決用戶體驗問題,使用戶達到所見即所想,打造觸動內心的極致體驗。
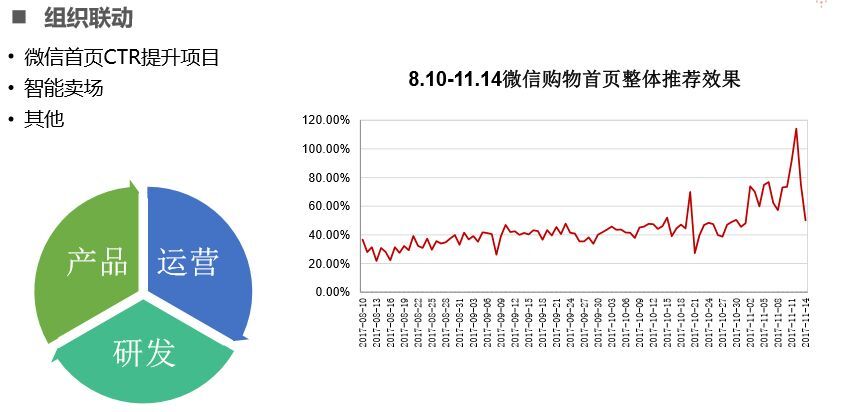
除了ABC技術提高推薦轉化率,團隊發現組織聯動在推薦效果也有明顯提升,上圖是去年8月到11月的推薦效果提升,如果單純的靠算法優化,效果只能提升30%達到50-60%就是算法極限,但是如果和產品聯動效果由30%提升到90%,因此建議在做算法優化是加入產品運營聯動。如在穿搭推薦中先前無論如何算法優化,轉化率一直很低,最后發現是產品素材質量太差,無法引起用戶興趣。另一方面在智能賣場做數據挖掘、爬蟲抓取關聯商品,再進行聚類確實能夠發現人的行為,但是運營能抓住用戶價值點,如果在物料上加入這些價值點,能夠明顯提升推薦效果。
2. WQ推薦平臺
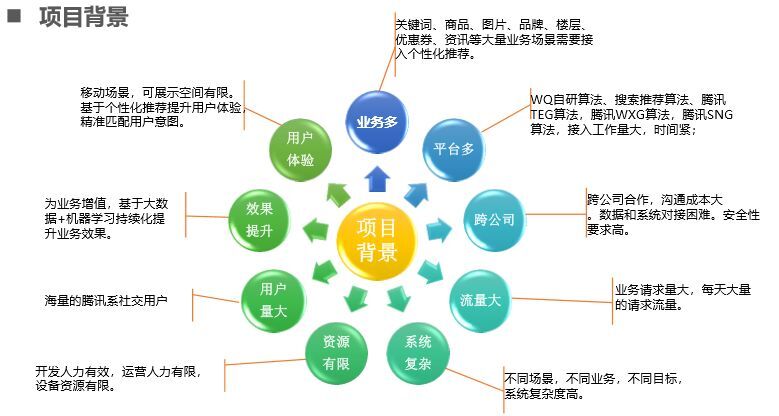
WQ推薦系統需要知道解決那些問題:
(1)首先業務需求多,原先想的是一個一個業務對接,但是關鍵詞開發需要人員,資訊開發也需要人員,但是開發人員資源有限,開發壓力大,無法應對也無需求;
(2)平臺多,接入工作流量大,每個都去對接工作量大;
(3)跨公司問題,數據不是完全共享,安全性能要求高,只能系統對接,因此流量紅點壓力大;
(4)用戶體驗問題,只能向前不能倒退
(5)效果問題,增長放緩,只能從技術、算法方面來提升;
(6)用戶量大,資源有限等。
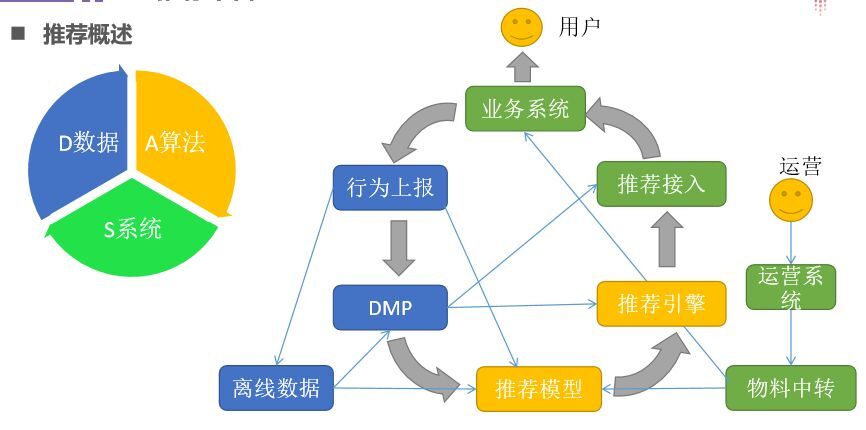
推薦系統核心是“數據”、“算法”、“系統”,有這三種推薦系統就能運行。具體工作是:首先用戶會請求我們的業務系統,之后請求推薦引擎,推薦接入實現業務分流到對應的推薦平臺,然后通過推薦算法、模型返回用戶所需數據。除此之外還有一個數據的反向上報(行為上報),因為我們的推薦都是基于大數據,如果我們能收集用戶的行為越多,對用戶的行為就越準,推薦也就越精確。對用戶的(點擊,搜索,瀏覽)做DMP(大數據管理平臺),讓模型訓練算法,其響應時間一般是限度控制在300-500毫秒。
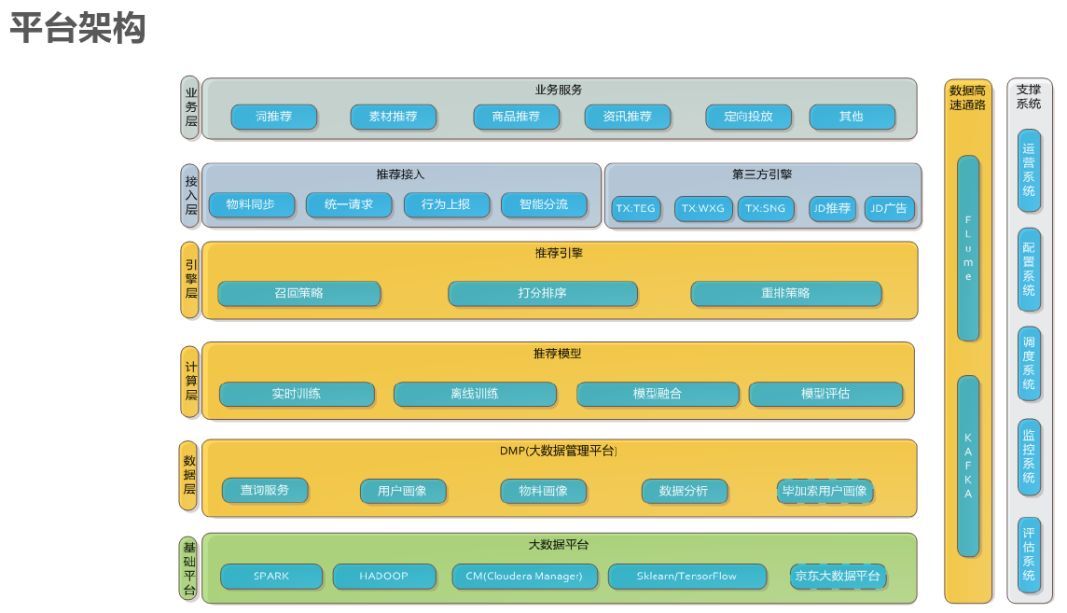
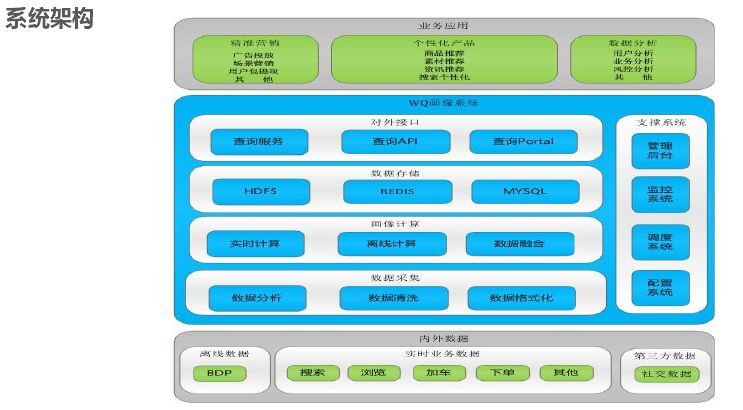
WQ推薦系統平臺架構如下所示,依據架構依據相關開源軟件能夠3-5天搭建一個推薦系統。首先業務層,主要是有哪些業務;其次是接入層,我們有第三方接入引擎,還要做分流,都要做A/B text;接入后要做推薦引擎,我們分為三層:為召回策略(添加條件,選擇最相關)、打分排序、重排策略;引擎打分需要模型,這一塊為計算層。再然后是數據層,這塊主要是用戶畫像和物料畫像以及數據分析等;最底層是基礎平臺,來支持我們做推薦,算法訓練,我們的實時用的是Spark,離線用的是Hadoop,用CM做集成,用Sklearn/TensorFlow做離線分析,對于大賬號推送用全站數據(京東大數據平臺)比WQ效果要好。除此之外比較重要的一個是數據上報,最開始用的是自己研發的用C/C++實現,后來需要與業界對標,采用Flume和Kafka。集群時間是分鐘級,但是用戶畫像是毫秒級,用戶畫像是基于用戶行為而不是數據庫。
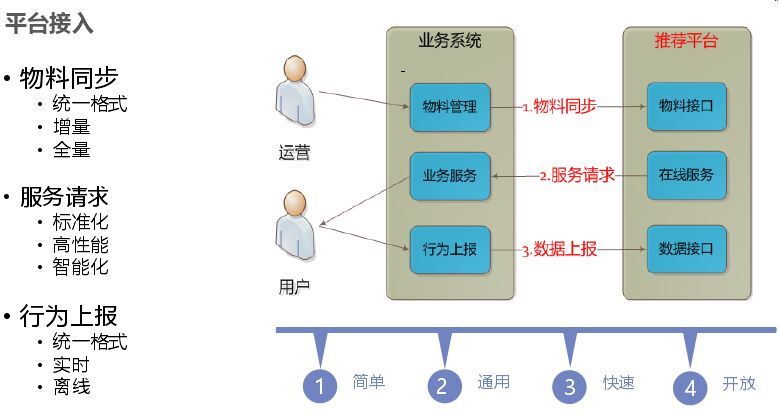
在平臺接入時,需要簡單、通用、快速、開放為目標。將業務抽象為物料,統一格式,業務只需要實現物料上報、請求服務、行為上報三步。對于算法選擇前期配置就能快速上線,選擇快速上線算法是熱度和IOR算法。智能接入:由于平臺多,通過物料、用戶、平臺判斷哪個平臺轉化效率高,就將平臺流量多分給推薦平臺,達到整體最優,對于模型選擇各自去訓練,然后選擇、融合。
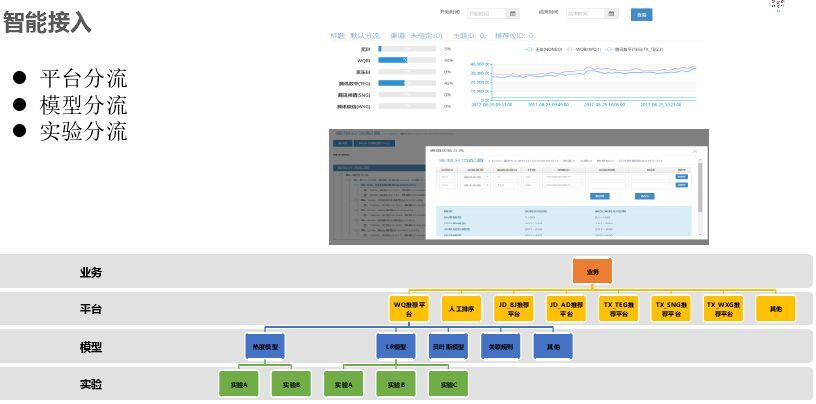
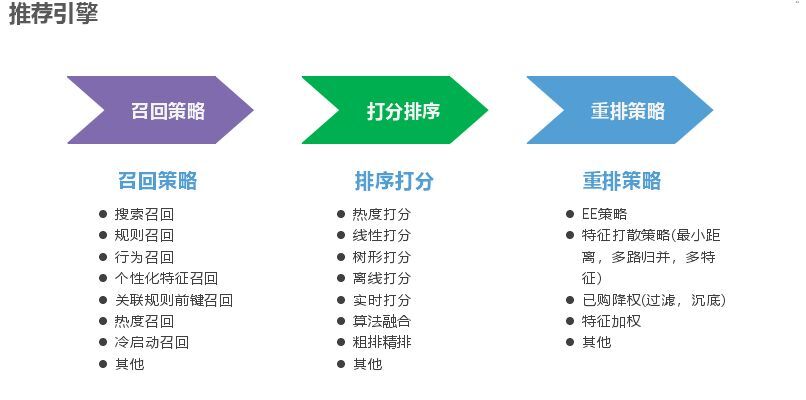
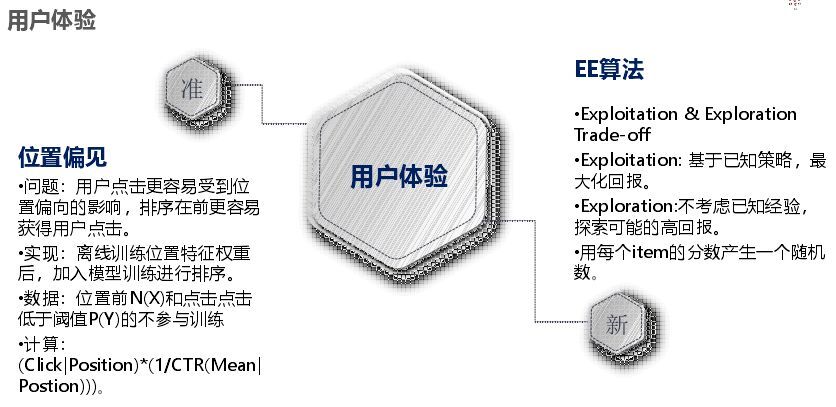
接入之后就是推薦引擎,常見的有召回策略、打分策略、重排策略。召回策略如下所示,所謂個性化召回就是畫像打上的那些標簽,是偏向某個類目還是某個品牌偏好等做召回,關聯規則前鍵召回是根據用戶前面的行為來關聯后續感興趣的商品;打分就是和模型結合;重排也有很多算法,例如特征加權就是用戶有什么偏好給他提前。重排主要是基于個人,模型是基于群體特征,重排命中也能很好提升效率,EE策略主要改善體驗問題,我們發現如果一個人行為很少,進來之后什么都不點,如果模型在5-10分鐘未更新,推薦的就是一直是這個,如果特別偏門,群體又比較小,模型就沒有影響,個人就需要推薦一些新的東西,EE策略就是以一定概率來顯示推薦而不是單純以排名推薦,我們用的是湯姆森算法。
接下來講一下模型,我們的推薦模型就是解決GMV(成交)最大化、CTR * CVR最大化、CTR最大化(首頁、中間頁引流,最容易,點擊轉化率)核心是“他點的”/“他看的”。這個模型還有一個瞬息系約束,一方面就是EE策略,另一個就是某一類商品在一定時間不能超過多少,保證用戶體驗。在評價推薦效果方面,如果直接做到下單,其中很多因素不可控,這時考慮CTR * CVR模型,提升轉化率,主要考慮物料、用戶以及上下文場景。
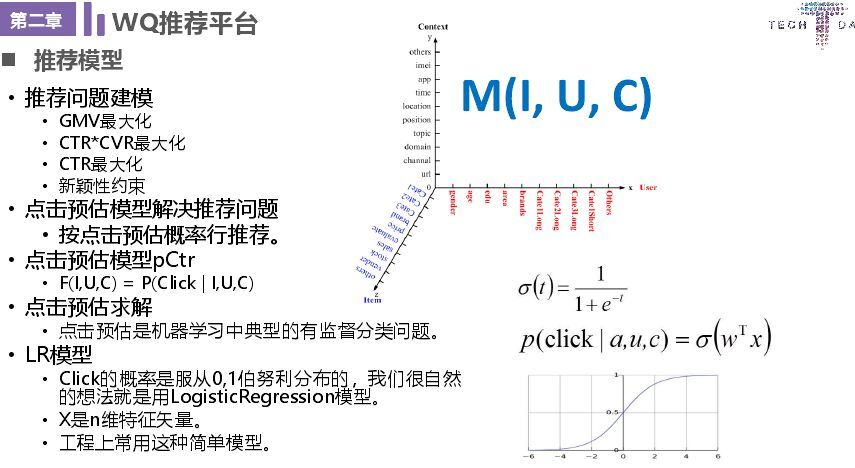
接下來就是機器學習過程,主要有環境搭建、收集數據、分析數據、準備數據、訓練算法、測試算法、應用算法。這個過程很簡單,但是我們要解決冷啟動問題、假曝光問題(這個主要是產品預加載,在用戶還未看數據就顯示,這種就是假曝光)異常數據清洗問題(爬蟲、刷單)、正負樣本問題、數據稀疏問題等問題。在推薦過程中數據是基礎中的基礎,下面是數據處理中常用的方法。

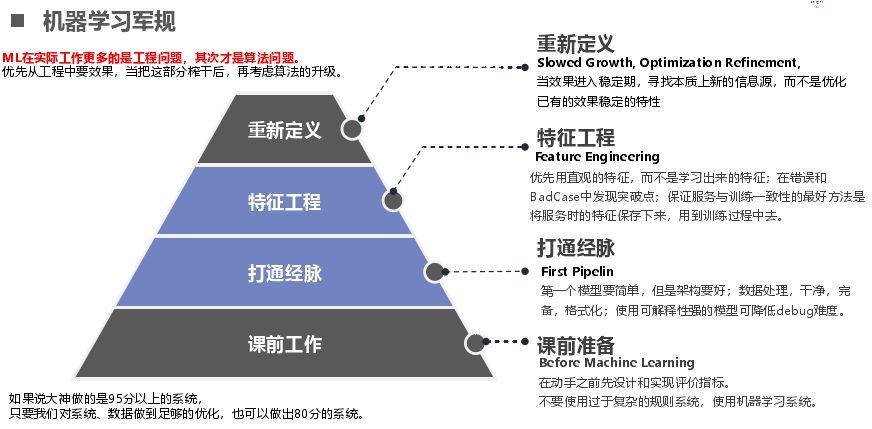
在算法里面對我們比較受益的是機器學習軍規,做C++或前端時有雅虎軍規、effective C++這些都有很規則性的東西告訴你怎么做。在機器學中有一個機器學習軍規,其實在ML中首要的是工程問題,其次才是算法問題。我們把數據做好了效果也就好了,如果大神能做95分,我們做好了這些也有80分。
而用戶體驗方面,一個是要準,另一個是要新。新就是EE算法,準就是位置偏見,例如冷啟動時你把某一個商品放在前面,那么他的轉化率一直高;這種就不能他分值高就一直在前面,這種情況就要看不同商品在此位置時的轉化率,這個就是位置偏見。
3. WQ用戶畫像
接下來簡單介紹下用戶畫像,做推薦時你首先要知道用戶是誰,如果你只用cookie Mapping的話效果太差,這個我們是和微信合作,我們是拿到open ID的,如果有微信場景可以參考這種方式;其次用戶是什么用戶,這就是用戶畫像;再者用戶還是那個用戶么(可能前一秒和下一秒不是同一個用戶)因此要注意更新。畫像主要解決身份問題,還有就是WQ數據和自己收集數據以及全站數據,這些數據整個融合而做的一個用戶畫像。
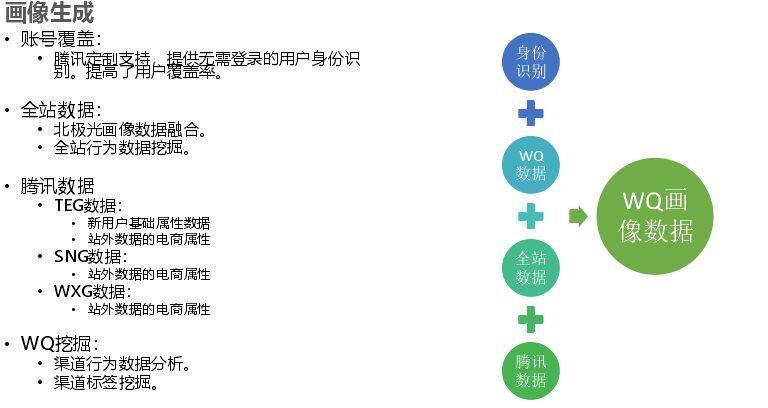
用戶畫像的系統架構首先是一個內外部數據的融合,然后是做采集(分析、清洗、格式化然后做一些畫像計算)這里用到很多算法,如統計算法等。

4. WQ大數據平臺
大數據平臺主要解決實時問題、系統復雜問題、業務支持(支持ML算法等)下面是系統需要的達到的目標。
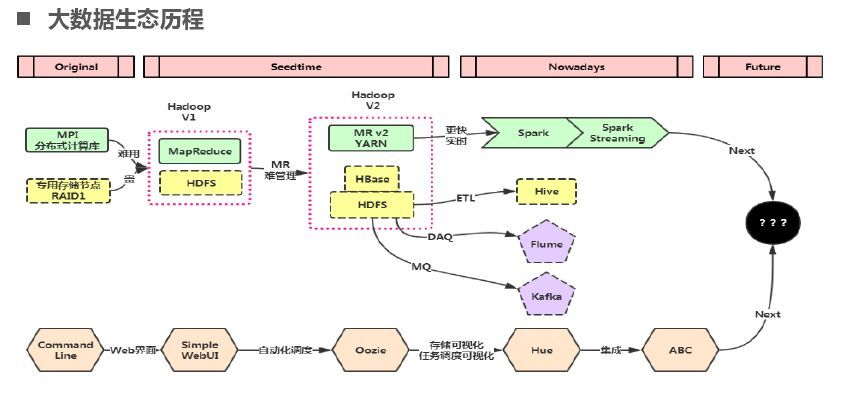
接下來講一下大數據生態,最開始時是并行計算(最原始的那種命令行并行計算)然后就是Hadoop(MapReduce和HDFS開始也是簡單UI)在Hadoop V2就有了HBase之后就是更快的Spark(Hive、Flume、Kafka),下面是整個大數據生態。
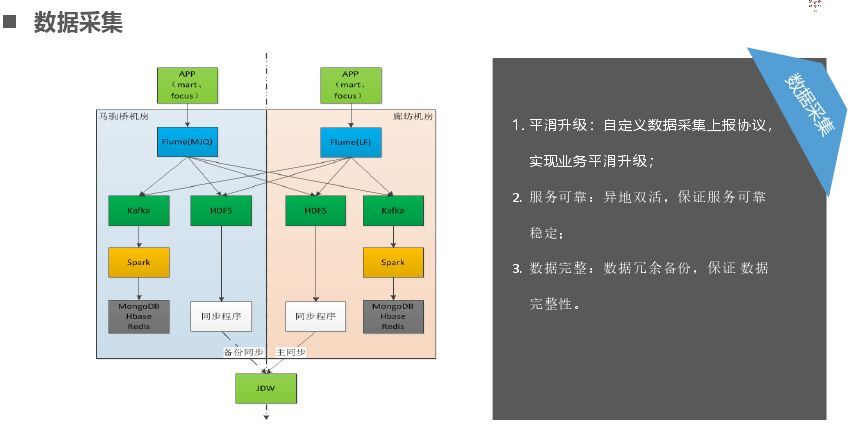
最后講一下大數據采集,對于我們做賬務,事務型的數據不能丟,可以慢不能丟,所以可以異地多活(主要是做一個異地防或多級防的備份),這個需要看具體業務需求。
本文來自京東微信手Q業務部馬老師在 DataFun 社區的演講,由 DataFun 編輯整理。










)







![Luogu P3731 [HAOI2017]新型城市化](http://pic.xiahunao.cn/Luogu P3731 [HAOI2017]新型城市化)
