為什么80%的碼農都做不了架構師?>>> ??

阿里妹導讀:2018年4月阿里巴巴業務平臺事業部——知識圖譜團隊聯合清華大學、浙江大學、中科院自動化所、中科院軟件所、蘇州大學等五家機構,聯合發布藏經閣(知識引擎)研究計劃。
藏經閣計劃依賴阿里強大的計算能力(例如Igraph圖數據庫),和先進的機器學習算法(例如PAI平臺)。計劃發布一年以來,阿里知識圖譜團隊有哪些技術突破?今天一起來了解。
背景
藏經閣計劃發布一年以來,我們對知識引擎技術進行了重新定義,將其定義成五大技術模塊:知識獲取、知識建模、知識推理、知識融合、知識服務,并將其開發落地。

其中知識建模的任務是定義通用/特定領域知識描述的概念、事件、規則及其相互關系的知識表示方法,建立通用/特定領域知識圖譜的概念模型;知識獲取是對知識建模定義的知識要素進行實例化的獲取過程,將非結構化數據結構化為圖譜里的知識;而知識融合是對異構和碎片化知識進行語義集成的過程,通過發現碎片化以及異構知識之間的關聯,獲得更完整的知識描述和知識之間的關聯關系,實現知識互補和融合;知識推理是根據知識圖譜提供知識計算和推理模型,發現知識圖譜中的相關知識和隱含知識的過程。知識服務則是通過構建好的知識圖譜提供以知識為核心的知識智能服務,提升應用系統的智能化服務能力。

圖1 藏經閣-知識引擎產品
經過一年的工作,在知識建模模塊我們開發了Ontology自動搭建、屬性自動發現等算法,搭建了知識圖譜Ontology構建的工具;在知識獲取模塊我們研發了新實體識別、緊湊型事件識別,關系抽取等算法,達到了業界最高水平;在知識融合模塊,我們設計了實體對齊和屬性對齊的深度學習算法,使之可以在不同知識庫上達到更好的擴展性,大大豐富了知識圖譜里的知識;在知識推理模塊,我們提出了基于Character Embedding的知識圖譜表示學習模型CharTransE、可解釋的知識圖譜學習表示模型XTransE,并開發出了強大的推理引擎。
基于上面的這些技術模塊,我們開發了通用的知識引擎產品,目前已經在全阿里經濟體的淘寶、天貓、盒馬鮮生、飛豬、天貓精靈等幾十種產品上取得了成功應用,每天有8000多萬次在線調用,日均離線輸出9億條知識。目前在知識引擎產品上,已經構建成功并運行著商品、旅游、新制造等5個垂直領域圖譜的服務。

圖2 知識引擎四個層次圖示
在每個模塊的構建過程中,我們陸續攻克了一系列的技術問題。本文將選取其中的兩項工作來介紹給大家:
1、在眾包數據上進行對抗學習的命名實體識別方法
知識獲取模塊包含實體識別、實體鏈接、新實體發現、關系抽取、事件挖掘等基本任務,而實體識別(NER)又是其中最核心的任務。
目前學術界最好的命名實體識別算法主要是基于有監督學習的。構建高性能NER系統的關鍵是獲取高質量標注語料。但是高質量標注數據通常需要專家進行標注,代價高并且速度較慢,因此目前工業界比較流行的方案是依賴眾包來標注數據,但是由于眾包人員素質參差不齊,對問題理解也千差萬別,所以用其訓練的算法效果會受到影響。基于此問題,我們提出了針對眾包標注數據,設計對抗網絡來學習眾包標注員之間的共性,消除噪音,提高中文NER的性能的方法。
這項工作的具體網絡框架如圖3所示:
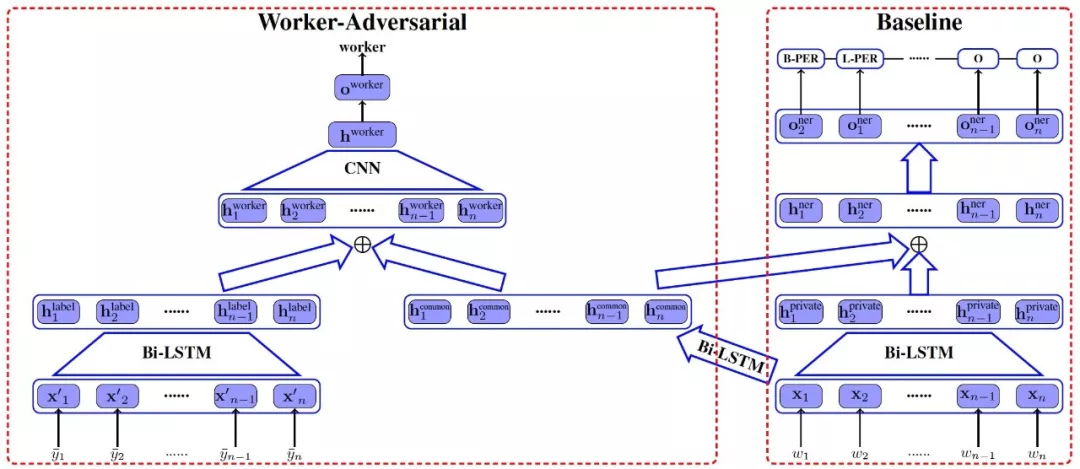
圖3基于對抗網絡的實體識別模型
標注員ID:對于各個標注員ID信息,我們使用一個Looking-up表,表內存儲著每個WorkerID的向量表示。向量的初始值通過隨機數進行初始化。在模型訓練過程中,ID向量的所有數值作為模型的參數,在迭代過程中隨同其他參數一起優化。在訓練時每個標注樣例的標注員,我們直接通過查表獲取對應的ID向量表示。在測試時,由于缺乏標注員信息,我們使用所有向量的平均值作為ID向量輸入。
對抗學習(WorkerAdversarial):眾包數據作為訓練語料,存在一定數量的標注錯誤,即“噪音”。這些標注不當或標注錯誤都是由標注員帶來的。不同標注員對于規范的理解和背景認識是不同的。對抗學習的各LSTM模塊如下:
- 私有信息的LSTM稱為“private”,它的學習目標是擬合各位標注員的獨立分布;而共有信息的LSTM稱為“common”,它的輸入是句子,它的作用是學習標注結果之間的共有特征,
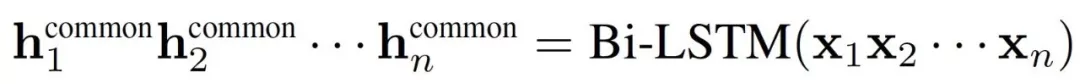 。
。
- 標注信息的LSTM稱為“label”,以訓練樣例的標注結果序列為輸入,
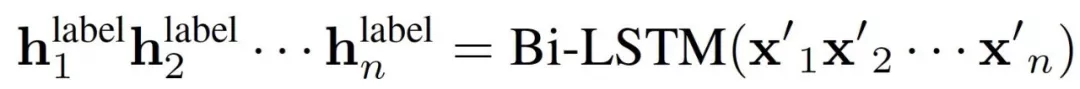
再通過標注員分類器把label和common的LSTM特征合并,輸入給CNN層進行特征組合提取,最終對標注員進行分類。要注意的是,我們希望標注員分類器最終失去判斷能力,也就是學習到特征對標注員沒有區分能力,也就是共性特征。所以在訓練參數優化時,它要反向更新。
在實際的實體識別任務中,我們把common和private的LSTM特征和標注員ID向量合并,作為實體標注部分的輸入,最后用CRF層解碼完成標注任務。
實驗結果如圖4所示,我們的算法在商品Title和用戶搜索Query的兩個數據集上均取得最好的性能:
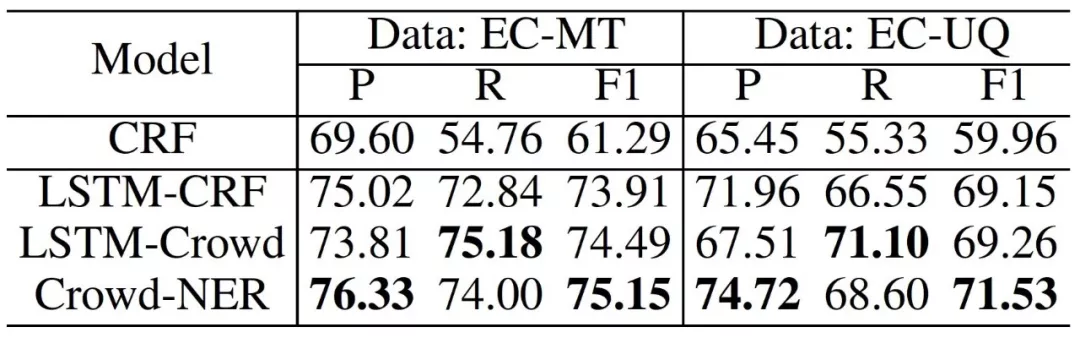
圖4基于對抗網絡的實體識別模型實驗結果
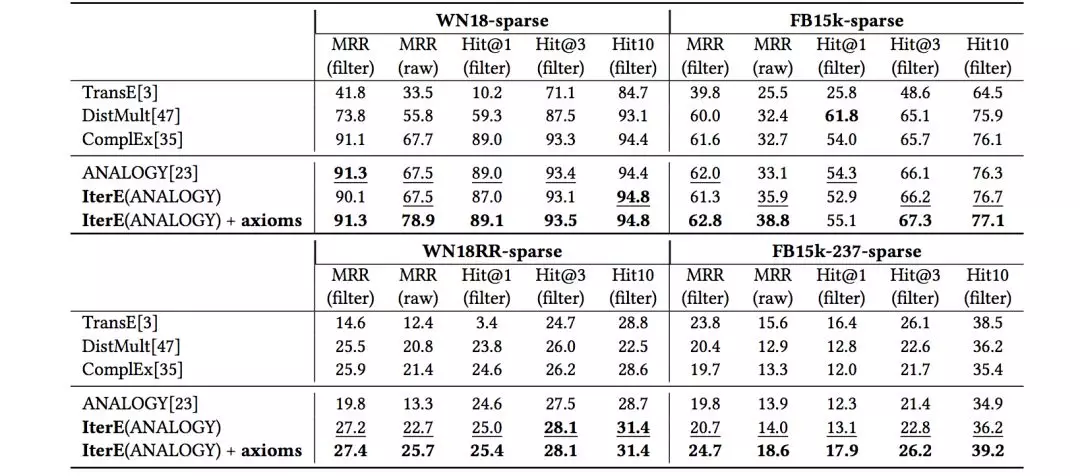
2、基于規則與graph embedding迭代學習的知識圖譜推理算法
知識圖譜推理計算是補充和校驗圖譜關系及屬性的必不可少的技術手段。規則和嵌入(Embedding)是兩種不同的知識圖譜推理的方式,并各有優劣,規則本身精確且人可理解,但大部分規則學習方法在大規模知識圖譜上面臨效率問題,而嵌入(Embedding)表示本身具有很強的特征捕捉能力,也能夠應用到大規模復雜的知識圖譜上,但好的嵌入表示依賴于訓練信息的豐富程度,所以對稀疏的實體很難學到很好的嵌入表示。我們提出了一種迭代學習規則和嵌入的思路,在這項工作中我們利用表示學習來學習規則,并利用規則對稀疏的實體進行潛在三元組的預測,并將預測的三元組添加到嵌入表示的學習過程中,然后不斷進行迭代學習。工作的整體框架如圖5所示:
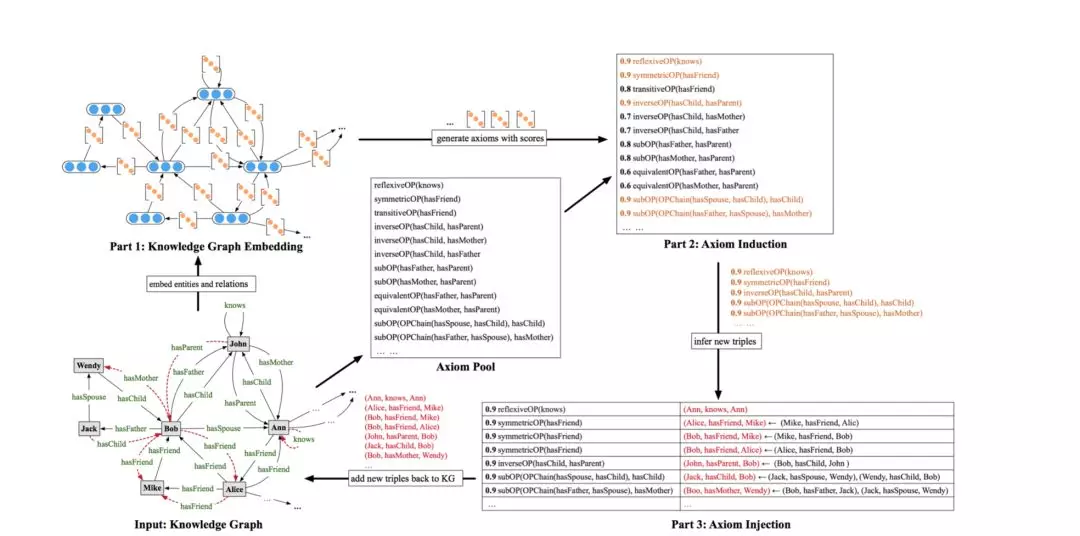
圖5基于對抗網絡的實體識別模型實驗結果
嵌入學習優化的目標函數是:
嵌入學習優化的目標函數是:
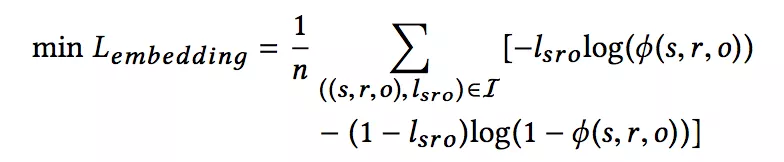
其中: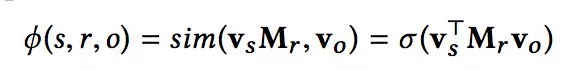
lsro表示三元組的標記,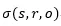
表示三元組的評分函數,vs表示圖譜三元組中主語(subject)的映射,Mr表示圖譜中兩個實體間關系的映射,vo表示圖譜三元組中賓語(object)的映射。
基于學習到的規則(axiom),就可以進行推理執行了。通過一種迭代策略,先使用嵌入(Embedding)的方法從圖譜中學習到規則,再將規則推理執行,將新增的關系再加入到圖譜中,通過這種不斷學習迭代的算法,能夠將圖譜中的關系預測做的越來越準。最終我們的算法取得了非常優秀的性能:
除了上述兩項工作以外,在知識引擎技術的研發上我們還有一系列的前沿工作,取得了領先業界的效果,研究成果發表在AAAI、WWW、EMNLP、WSDM等會議上。
之后阿里巴巴知識圖譜團隊會持續推進藏經閣計劃,構建通用可遷移的知識圖譜算法,并將知識圖譜里的數據輸出到阿里巴巴內外部的各項應用之中,為這些應用插上AI的翅膀,成為阿里巴巴經濟體乃至全社會的基礎設施。
作者:阿里知識圖譜團隊?
原文鏈接
本文為云棲社區原創內容,未經允許不得轉載。




![Luogu P3731 [HAOI2017]新型城市化](http://pic.xiahunao.cn/Luogu P3731 [HAOI2017]新型城市化)



![[flask]gunicorn配置文件](http://pic.xiahunao.cn/[flask]gunicorn配置文件)


)



)



