HDFS
Hadoop 1.0:
- 3個組件:
- Namenode
- SecondNamenode
- Datanode
namenode(主節點,master,只有一個,單點故障的風險)中間存儲信息(元數據)
2種映射關系:
- path -> blockid list 列表
- blockid 數據塊 -> datanode 節點地址
元數據存在內存中
元數據進行持久化 — 磁盤fsimage — 目的:避免數據丟失
fsimage : 元數據鏡像文件
只有機器重啟的時候加載fsimage
元數據持久化的過程 — SNN — secondnamenode
內存 -> edit log(磁盤)-> fsimage
SNN 存在意義 : 備份 / 數據恢復
namenode和 edit log關系:
namenode需要把每一次改動都存在 edit log ,整個過程誰來推動?(Datanode和namenode之間心跳機制)
namenode除了單點問題之外,還有不適合存儲太多小文件的問題,因為內存有限
datanode (slave,從節點,多個機器)
- block 數據塊 -> 真實輸據
多副本機制 — 默認3副本 (作用:數據冗余,高可用)
本地化原則 (就近原則):mapreduce:主(jobtracker - namenode),從(tasktracker - datanode)
可靠性保證 :
- 數據校驗
目的 : 保證數據完整性 (通過crc32校驗算法)
整個數據傳輸過程,輸據需要校驗幾次?- client給datanode寫數據:要針對寫的數據,每個檢查單元(512字節)
- 每一個單元創建一個單獨的校驗碼(crc32) , 數據和校驗碼統一發送給Datanode
- Datanode 接受輸據的時候 : 用同樣的加密算法,生成校驗碼,并校驗
- 在后臺還會運行一個掃描進程:DataBlockScanner(定期校驗)
- 一旦檢測出現問題,通過心跳,通知NN,讓NN發起DN修復 (拷貝沒有問題的備份)
- client給datanode寫數據:要針對寫的數據,每個檢查單元(512字節)
2.可靠性保證 :
- 心跳
- 多副本機制
- crc32
- SNN (secondnamenode)
- 回收站 ( .Trash 目錄)
Hadoop 2.0:
?
-
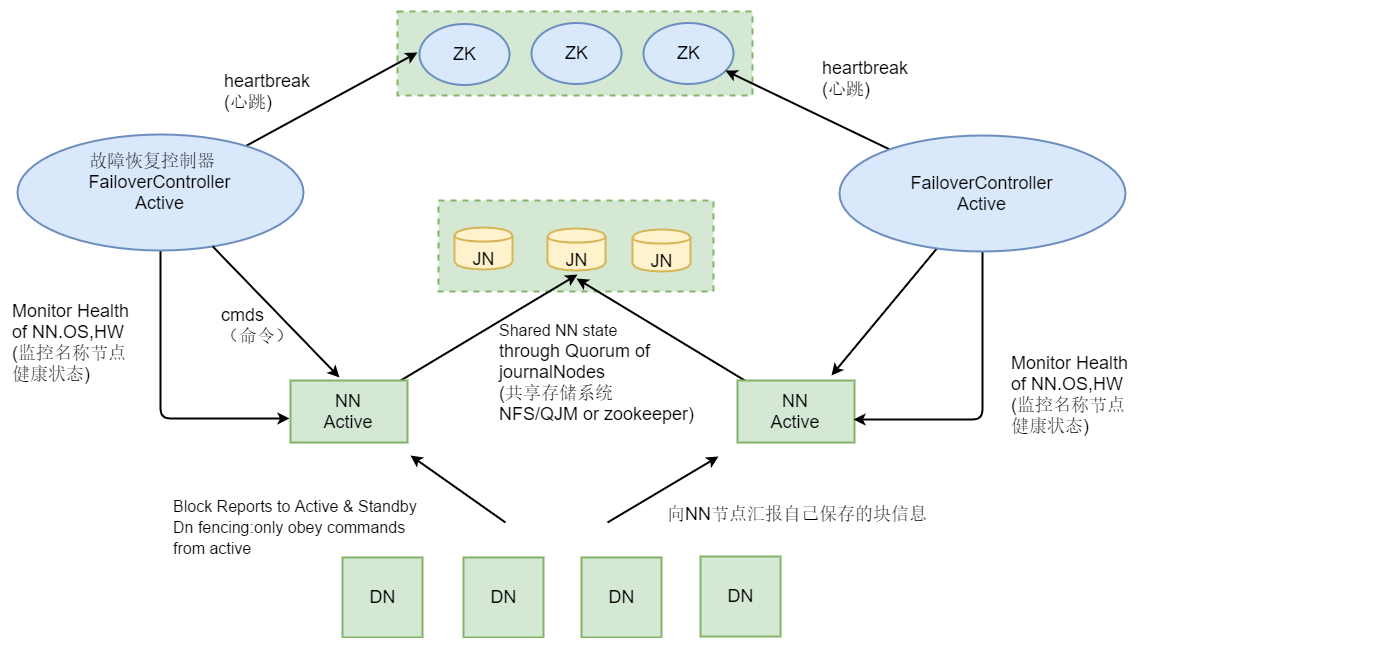
HA 高可用 : 解決了單點故障問題
1.0里有一個SNN,但是不可靠
如何便可靠:需要兩個NN,一個active,一個standby(備用)
為了保證兩個NN的數據一致性,Datanode要對兩個NN同時發送心跳 -
雖然Datanode同時發送心跳,但是為什么還需要JN?
2種映射關系:
path -> blockid list 列表 :JN
blockid 數據塊 -> datanode 節點地址 : Datanode心跳
分工不同::: -
HDFS2.0 需要引入zookeeper , (zookeeper目的:協調分布式集群中各個節點工作有序進行,完成故障轉移)
-
在2.0,引入zkfc(ZookeeperFailoverController)進程,和NN部署到同一個機器上,目的:負責自己管轄之內的NN進行健康檢查
zkfc 進程會在zookeeper上注冊一個臨時節點
目的:監控NN,一旦NN掛掉,相對應的臨時節點消失,接下來開始選主(申請鎖)流程 -
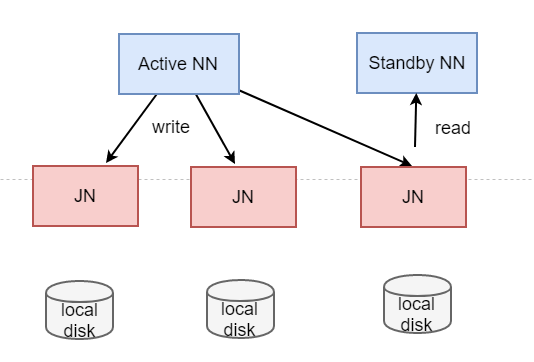
JN目的:讓activeNN和standbyNN保持輸據同步(文件 -> block)
同步問題:需要以來JN(JournalNodes)守護進程,完成元數據的一致性 -
JN 角色有兩種選擇:
1) NFS — 網絡系統 (network file system)
需要額外的磁盤空間
2)QJM — 最低法人管理機制 (投票)
不需要額外的磁盤空間
需要用2n+1臺機器存儲edit log (奇數是為了投票)
QJM本質是小集群
好處:
* 不需要空間
* 無但點問題
* 不會因為個別機器延遲,影響整體性能
* 只需要通過簡單的系統配置可以實現 -
NN 和 JN 通常不再一個機器上
FC 和 NN 在同一個機器上
RM(Yarn主) 和 NN(HDFS主) 通常在同一臺機器上
zookeeper 需要單獨維護一套獨立集群
?
HDFS Federation(聯邦) : 水平擴展
集群中提供多個Name Node,每個NameNode負責管理一部分DataNode
每一個NN只管理自己管轄之內的DN
目的:減輕單一NN壓力,將一部分文件轉移到其他NN上管理
如果集群中一個目錄比較大,那么可以用單獨的NN維護起來
橫向虧站,突破了NN的限制
不同的NN,會可以訪問所有的DN嗎? 會的?
聯邦的本質:將元數據管理NN和存儲DN進行解耦
可以把聯邦和高可用同時體現出來
快照:真實數據(不是元數據) ::: 數據備份/災備/快速恢復
本質:僅僅記錄block列表和大小而已,并不涉及數據本身的復制
某個目錄的某一時刻的鏡像
創建和恢復,都非常快 — 瞬間完成,高效
HDFS快照是一個只讀的基于時間點文件系統拷貝
HDFS快照是對目錄進行設定,是某個目錄的某一個時刻的鏡像
- 快照可以是整個文件系統的也可以是一部分
- 常用來作為數據備份,防止用戶錯誤操作和容災恢復
- Snapshot并不會影響HDFS的正常操作:修改會按照時間的反序記錄,這樣可以直接讀取到最新的數據
- 快照數據是當前數據減去修改部分計算出來的
- 快照會存儲在snapeshottable的目錄下
?
快照的各種命令
hdfs dfsadmin -allowSnapshot /user/spark
hdfs dfs -createSnapshot /user/spark s0
hdfs dfs -renameSnapshot /user/spark s0 s_init
hdfs dfs -deleteSnapshot /user/spark s_init
hdfs dfsadmin -disallowSnapshot /user/spark
?
?
緩存(集中式緩存 — 不局限具體的機器的cpu和操作系統層面上的優化)
對于重復訪問的文件很有用
優點:速度快
- 允許用戶指定要緩存的HDFS路徑
- 明確的鎖定可以阻止頻繁使用的數據被從內存中清除
- 集中化緩存管理對于重復訪問的文件很有用
- 可以換成目錄或文件,但目錄是非遞歸的
?
權限控制 ACL
類似于linux系統acl
例:rwx - rwx - rwx
自己 - 組 - 其他
設置權限: setacl命令
需要開啟功能:
dfs.permissions.enableddfs.namenode.acls.enabledhadoop fs -getfacl /input/aclhdfs dfs -setfacl -m user:mapred:r-- /input/aclhdfs dfs -setfacl -x user:mapred /input/acl









 ...)


)






)