C++和C的區別
總覽
- C是一個結構化語言,它的重點在于算法和數據結構。C程序的設計首要考慮的是如何通過一個過程,對輸入(或環境條件)進行運算處理得到輸出(或實現過程(事務)控制)。
- C++,首要考慮的是如何構造一個對象模型,讓這個模型能夠契合與之對應的問題域,這樣就可以通過獲取對象的狀態信息得到輸出或實現過程(事務)控制。 所以C與C++的最大區別在于它們的用于解決問題的思想方法不一樣。之所以說C++比C更先進,是因為“ 設計這個概念已經被融入到C++之中 ”。
設計思想上:
- C++是面向對象的語言,而C是面向過程的結構化編程語言
語法上:
- C++具有封裝、繼承和多態三種特性。封裝體現在類,繼承體現在類,多態體現在虛函數、類、友元
- C++相比C,增加多許多類型安全的功能,比如強制類型轉換(四個),const、private、智能指針、引用
- C++支持范式編程,比如模板類、函數模板等,STL
C++對C的增強
- (1) 類型檢查更為嚴格:C++ 通過使用基類指針或引用來代替 void* 的使用,避免了這個問題(其實也是體現了類繼承的多態性)
- (2) 增加了面向對象的機制:C++允許結構體中封裝函數,而在其他的地方直接調用這個函數。這個封裝好的可直接調用的模塊有個新名詞——對象;并且也把結構體換一個名字——類。這就是面向對象的思想。在構建對象的時候,把對象的一些操作全部定義好并且給出接口的方式,對于外部使用者而言,可以不需要知道函數的處理過程,只需要知道調用方式、傳遞參數、返回值、處理結果。
- (3)增加了泛型編程的機制(Template):不同的類型采用相同的方式來操作,模版技術具有比類、函數更高的抽象水平,因為模版能夠生成出(實例化)類和函數。可以用來: 1,替換類型(最常用的 vector<T>);2,判定類型(is_integral<T>)和類型間的關系(is_convertible<From, To>) ;3,控制模版函數的實例化(SFINAE ---> enable_if<bool, T>)
- (4)增加了異常處理:C++ 提供了一系列標準的異常,定義在 <exception> 中,可以在程序中使用這些標準的異常。它們是以父子類層次結構組織起來的,如下所示:
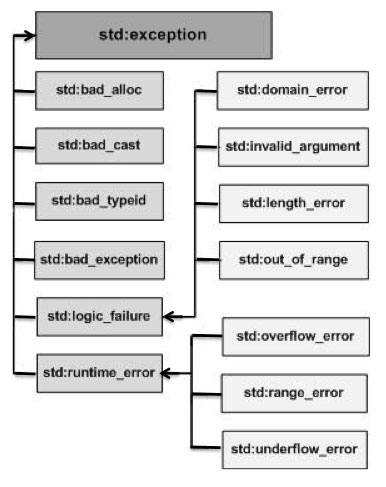

- (5)增加了運算符重載:C++ 可以實現函數重載,條件是:函數名必須相同,返回值類型也必須相同,但參數的個數、類型或順序至少有其一不同。而重載的運算符是帶有特殊名稱的函數,函數名是由關鍵字 operator 和其后要重載的運算符符號構成的。大多數的重載運算符可被定義為普通的非成員函數(
func(a, b)形式調用)或者被定義為類成員函數(a.func(b)形式調用) - (6)增加了標準模板庫(STL)STL 的數據結構和內部實現
- (7)C和C++動態管理內存的方法不一樣:C是使用malloc、free函數,而C++不僅有malloc/free,還有new/delete關鍵字。那malloc/free和new/delete差別? malloc/free和new/delete差別: ①、malloc/free是C和C++語言的標準庫函數,new/delete是C++的運算符。它們都可用于申請動態內存和釋放內存。 ②、由于malloc/free是庫函數不是運算符,不在編譯器范圍之內,不能夠把執行構造函數和析構函數的任務強加入malloc/free。因此C++需要一個能完成動態內存分配和初始化工作的運算符new,一個能完成清理與釋放內存工作的運算符delete。 ③、new可以認為是malloc加構造函數的執行。new出來的指針是直接帶類型信息的。而malloc返回的都是void指針。 ④、malloc是從堆上開辟空間,而new是從自由存儲區開辟(自由存儲區是從C++抽象出來的概念,不僅可以是堆,還可以是靜態存儲區)。 ⑤、malloc對開辟的空間大小有嚴格指定,而new只需要對象名。 ⑥、malloc開辟的內存如果太小,想要換一塊大一點的,可以調用relloc實現,但是new沒有直觀的方法來改變。
- (8)C++有很多特有的輸入輸出流
- (9)C++中有引用,而C沒有。 那指針和引用有什么差別? 指針和引用的區別: ①、指針有自己的一塊空間,而引用只是一個別名。 ②、使用sizeof查看一個指針大小為4(32位),而引用的大小是被引用對象的大小。 ③、指針可以是NULL,而引用必須被初始化且必須是對一個以初始化對象的引用。 ④、作為參數傳遞時,指針需要被解引用才可以對對象進行操作,而直接對引用的修改都會改變引用所指向的對象。 ⑤、指針在使用中可以指向其它對象,但是引用只能是一個對象的引用,不能被修改。 ⑥、指針可以有多級指針(**p),而引用只有一級。 ⑦、指針和引用使用++運算符的意義不一樣。
參考鏈接
- C 與 C++ 的區別
請說一下C/C++ 中指針和引用的區別?
- 1.指針有自己的一塊空間,而引用只是一個別名;
- 2.使用sizeof看一個指針的大小是4,而引用則是被引用對象的大小;
- 3.指針可以被初始化為NULL,而引用必須被初始化且必須是一個已有對象 的引用;
- 4.作為參數傳遞時,指針需要被解引用才可以對對象進行操作,而直接對引 用的修改都會改變引用所指向的對象;
- 5.可以有const指針,但是沒有const引用;
- 6.指針在使用中可以指向其它對象,但是引用只能是一個對象的引用,不能 被改變;
- 7.指針可以有多級指針(**p),而引用至于一級;
- 8.指針和引用使用++運算符的意義不一樣;
- 9.如果返回動態內存分配的對象或者內存,必須使用指針,引用可能引起內存泄露。
怎么判斷一個數是二的倍數,怎么求一個數中有幾個1,說一下你的思路并手寫代碼
- 判斷一個數是不是二的倍數,即判斷該數二進制末位是不是0:
- a % 2 == 0 或者a & 0x0001 == 0。
- 2、求一個數中1的位數,可以直接逐位除十取余判斷:
#include <iostream>
#include <memory>int judgment_function(size_t &number){int count = 0;while (number){if (number % 10 == 1){count++;}number /= 10;}return count;
}int main()
{size_t a = 11123422234411111111;std::cout << judgment_function(a) << std::endl;
}數組和指針的區別
- 鏈接:https://www.nowcoder.com/questionTerminal/68dfbfbb8dd349168b252849bf526e87
- 數組:數組是用于儲存多個相同類型數據的集合。
- 指針:指針相當于一個變量,但是它和不同變量不一樣,它存放的是其它變量在內存中的地址。
區別
- 賦值:同類型指針變量可以相互賦值,數組不行,只能一個一個元素的賦值或拷貝
- 存儲方式:數組:數組在內存中是連續存放的,開辟一塊連續的內存空間。數組是根據數組的下標進行訪問的,可以隨機訪問。指針:指針很靈活,它可以指向任意類型的數據。指針的類型說明了它所指向地址空間的內存。
- 求sizeof:數組所占存儲空間的內存:sizeof(數組名),數組的大小 =? sizeof(數組名)/sizeof(數據類型)。在32位平臺下,無論指針的類型是什么,sizeof(指針名)都是4,在64位平臺下,無論指針的類型是什么,sizeof(指針名)都是8。
初始化方式不同
- 傳參方式:數組傳參時,會退化為指針,C語言將數組的傳參進行了退化。將整個數組拷貝一份傳入函數時,將數組名看做常量指針,傳數組首元素的地址。一級指針傳參可以接受的參數類型:(1)可以是一個整形指針 (2)可以是整型變量地址 (3)可以是一維整型數組數組名;
- 當函數參數部分是二級指針時,可以接受的參數類型:(1)二級指針變量(2)一級指針變量地址(3)一維指針數組的數組名
野指針
- “野指針”不是NULL指針,是指向“垃圾”內存的指針。人們一般不會錯用NULL指針,因為用if語句很容易判斷。但是“野指針”是很危險的,if語句對它不起作用。野指針的成因主要有兩種:
- 一、指針變量沒有被初始化。任何指針變量剛被創建時不會自動成為NULL指針,它的缺省值是隨機的,它會亂指一氣。所以,指針變量在創建的同時應當被初始化,要么將指針設置為NULL,要么讓它指向合法的內存。
- 二、指針p被free或者delete之后,沒有置為NULL,讓人誤以為p是個合法的指針。別看free和delete的名字惡狠狠的(尤其是delete),它們只是把指針所指的內存給釋放掉,但并沒有把指針本身干掉。通常會用語句if (p != NULL)進行防錯處理。很遺憾,此時if語句起不到防錯作用,因為即便p不是NULL指針,它也不指向合法的內存塊。
C++面經 基本語言(二)
請你回答一下為什么析構函數必須是虛函數?為什么C++默認的析構函數不是虛函數 考點:虛函數 析構函數
- 將可能會被繼承的父類的析構函數設置為虛函數,可以保證new一個子類,然后使用基類指針指向該子類對象,釋放基類指針時可以釋放掉子類的空間,防止內存泄漏。
- C++默認的析構函數不是虛函數是因為虛函數需要額外的虛函數表和虛表指針,占用額外的內存。而對于不會被繼承的類來說,其析構函數如果是虛函數,就會浪費內存。因此C++默認的析構函數不是虛函數,而是只有當需要當作父類時,設置為虛函數。
- 如果基類的構造函數不使用虛函數 virtual,其派生的子類都會使用父類的構造方法,不會使用自己重新定義構造函數
- 詳見??C++ 查漏補缺? ? 使用 “多態 虛函數理論” 作為索引
請你來說一下函數指針
定義
- 函數指針是指向函數的指針變量
- 函數指針本身首先是一個指針變量,該指針變量指向一個具體的函數。這正如用指針變量可指向整型變量、字符型、數組一樣,這里是指向函數。
- C在編譯時,每一個函數都有一個入口地址,該入口地址就是函數指針所指向的地址。有了指向函數的指針變量后,可用該指針變量調用函數,就如同用指針變量可引用其他類型變量一樣,在這些概念上是大體一致的。
用途
- 調用函數和做函數的參數,比如回調函數。
示例
- char?* fun(char?* p) ?{…} ??????// 函數fun
- char?* (*pf)(char?* p);?????????????// 函數指針pf
- pf = fun;????????????????????????// 函數指針pf指向函數fun
- pf(p);????????????????????????// 通過函數指針pf調用函數fun
#include <iostream>int max(int x,int y){return x > y ? x : y;
}int main(void)
{//p是函數指針//typedef int (*fun_ptr)(int,int); // 聲明一個指向同樣參數、返回值的函數指針類型int (*p)(int,int) = &max; //&可以省略int a = 2,b=3,c=4;/* 與直接調用函數等價,d = max(max(a, b), c) */int d = p(p(a,b),c);std::cout << "最大的數字是:" << d << std::endl;
}參考鏈接
- 函數指針及其定義和用法,C語言函數指針詳解
- 函數指針
回調函數
函數指針作為某個函數的參數
- 函數指針變量可以作為某個函數的參數來使用的,回調函數就是一個通過函數指針調用的函數。
- 簡單講:回調函數是由別人的函數執行時調用你實現的函數。
以下是來自知乎作者常溪玲的解說:
你到一個商店買東西,剛好你要的東西沒有貨,于是你在店員那里留下了你的電話,過了幾天店里有貨了,店員就打了你的電話,然后你接到電話后就到店里去取了貨。在這個例子里,你的電話號碼就叫回調函數,你把電話留給店員就叫登記回調函數,店里后來有貨了叫做觸發了回調關聯的事件,店員給你打電話叫做調用回調函數,你到店里去取貨叫做響應回調事件。
實例
- 實例中 populate_array 函數定義了三個參數,其中第三個參數是函數的指針,通過該函數來設置數組的值。
- 實例中我們定義了回調函數 getNextRandomValue,它返回一個隨機值,它作為一個函數指針傳遞給 populate_array 函數。
- populate_array 將調用 10 次回調函數,并將回調函數的返回值賦值給數組。
#include <iostream>//回調函數
void populate_array(int *array,size_t array_size,int(*get_next_value)(void)){for (auto i = 0; i < array_size; ++i) {array[i] = get_next_value();}
}//獲取隨機數值
int get_next_value(void){return rand();
}int main(void)
{int array[10]{};/* getNextRandomValue 不能加括號,否則無法編譯,因為加上括號之后相當于傳入此參數時傳入了 int , 而不是函數指針*/populate_array(array,10,get_next_value);for (auto i = 0; i < 10; ++i) {printf("%d ",array[i]);}printf("\n");return 0;
}請你來說一下fork函數
- Fork:可以通過fork( )系統調用,創建一個和當前進程映像一樣的進程:
- #include <sys/types.h>
- #include <unistd.h>
- pid_t fork(void);
- 成功調用fork( )會創建一個新的進程,它幾乎與調用fork( )的進程一模一樣,這兩個進程都會繼續運行。在子進程中,成功的fork( )調用會返回0。在父進程中fork( )返回子進程的pid。如果出現錯誤,fork( )返回一個負值。? fork函數會有兩個返回值,父進程返回子進程的pid,新創建的子進程返回0,通過返回值確定當前進程是父親還是孩子。如果出現錯誤,返回負數。
- 最常見的fork( )用法是創建一個新的進程,然后使用exec( )載入二進制映像,替換當前進程的映像(起一個進程執行用戶指定的程序)。這種情況下,派生(fork)了新的進程,而這個子進程會執行一個新的二進制可執行文件的映像。這種“派生加執行”的方式是很常見的。
- 在早期的Unix系統中,創建進程比較原始。當調用fork時,內核會把所有的內部數據結構復制一份,復制進程的頁表項,然后把父進程的地址空間中的內容逐頁的復制到子進程的地址空間中。但從內核角度來說,逐頁的復制方式是十分耗時的。現代的Unix系統采取了更多的優化,例如Linux,采用了寫時復制的方法,而不是對父進程空間進程整體復制。
- 每個進程都有一個獨特(互不相同)的進程標識符(process ID),可以通過getpid()函數獲得
參考鏈接
- fork(2) — Linux manual page
- linux中fork()函數詳解(原創!!實例講解)
?請你來說一下C++中析構函數的作用
- 析構函數與構造函數對應,當對象結束其生命周期,如對象所在的函數已調用完畢時,系統會自動執行析構函數。
- 析構函數名也應與類名相同,只是在函數名前面加一個位取反符~,例如~stud( ),以區別于構造函數。它不能帶任何參數,也沒有返回值(包括void類型)。只能有一個析構函數,不能重載。
- 如果用戶沒有編寫析構函數,編譯系統會自動生成一個缺省的析構函數(即使自定義了析構函數,編譯器也總是會為我們合成一個析構函數,并且如果自定義了析構函數,編譯器在執行時會先調用自定義的析構函數再調用合成的析構函數),它也不進行任何操作。所以許多簡單的類中沒有用顯式的析構函數。
- 如果一個類中有指針,且在使用的過程中動態的申請了內存,那么最好顯示構造析構函數在銷毀類之前,釋放掉申請的內存空間,避免內存泄漏。
- 類析構順序:1)派生類本身的析構函數;2)對象成員析構函數;3)基類析構函數。
- 將基類的析構函數弄成虛函數的形式,派生類繼承基類的析構函數,并對其進行函數的重載。適用于使用數組存儲多個對象的情形,只能使用派生類自定義的析構函數,釋放其申請的內存空間。
- 什么時候需要自定義析構函數?比如在堆上申請了一大段內存空間,使用delete []p,進行資源的釋放
- delete 對象,先調用用戶自定義的析構函數,再調用編譯系統自動生成的缺省的析構函數
#include <iostream>
#include <fstream>
#include <sstream>class Car{
public:Car(){m_pName = new char [20];std::cout << " 對象創建" << std::endl;};~Car(){delete[] m_pName;std::cout << " 對象銷毀 " << std::endl;}
private:char *m_pName;
};
int main(void)
{Car *car = new Car();delete car;car = nullptr;return 0;
}請你來說一下靜態函數和虛函數的區別
- 靜態函數在編譯的時候就已經確定運行時機,虛函數在運行的時候動態綁定。虛函數因為用了虛函數表機制,調用的時候會增加一次內存開銷
- 類的靜態函數是沒有this指針的,調用它時不需要創建對象,通過:類名 ::函數名(參數)的形式直接調用。靜態函數只有唯一的一份,因此它的地址是固定不變的, 所以編譯的時候但凡遇到調用該靜態函數的時候就知道調用的是哪一個函數,因此說靜態函數在編譯的時候就已經確定運行時機
- 類A與類B構成多態,創建了 A類指針pb指向 B類對象,當程序編譯的時候只對語法等進行檢測,該語句沒有什么問題,但是編譯器此時無法確定調用的是哪一個 fun() 函數,因為類A類B中都含有fun函數,因此只能是在程序運行的時候通過 pb指針 查看對象的虛函數表(訪問虛函數表就是所謂的訪問內存 內存)才能確定該函數的地址,即確定調用的是哪一個函數。這就解釋了所說的“虛函數在運行的時候動態綁定。虛函數因為用了虛函數表機制,調用的時候會增加一次內存開銷
#include <iostream>class A{
public:virtual void fun(){std::cout << " A " << std::endl;}
};class B : public A{
public:virtual void fun(){std::cout << " B " << std::endl;}
};int main(void)
{A a{};B b{};A* pb = &b;pb->fun();a.fun();b.fun();return 0;
}參考鏈接
- C++ 靜態函數與虛函數的區別
面向對象的三個基本特征
- 封裝可以隱藏實現細節,使得代碼模塊化;繼承可以擴展已存在的代碼模塊(類);它們的目的都是為了——代碼重用。而多態則是為了實現另一個目的——接口重用
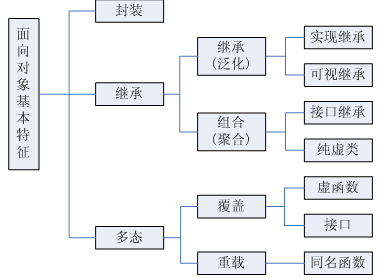
封裝
- 封裝:就是把客觀事物封裝成抽象的類,并且類可以把自己的數據和方法只讓可信的類或者對象操作,對不可信的進行信息隱藏。封裝是面向對象的特征之一,是對象和類概念的主要特性。 簡單的說,一個類就是一個封裝了數據以及操作這些數據的代碼的邏輯實體。在一個對象內部,某些代碼或某些數據可以是私有的,不能被外界訪問。通過這種方式,對象對內部數據提供了不同級別的保護,以防止程序中無關的部分意外的改變或錯誤的使用了對象的私有部分。
繼承
- 繼承是指可以讓某個類型的對象獲得另一個類型的對象的屬性的方法。它支持按級分類的概念。繼承是指這樣一種能力:它可以使用現有類的所有功能,并在無需重新編寫原來的類的情況下對這些功能進行擴展。 通過繼承創建的新類稱為“子類”或“派生類”,被繼承的類稱為“基類”、“父類”或“超類”。繼承的過程,就是從一般到特殊的過程。要實現繼承,可以通過“繼承”(Inheritance)和“組合”來實現。繼承概念的實現方式有二類:實現繼承與接口繼承。實現繼承是指直接使用基類的屬性和方法而無需額外編碼的能力;接口繼承是指僅使用屬性和方法的名稱、但是子類必須提供實現的能力;
多態
- 多態意味著調用成員函數時,會根據調用函數的對象的類型來執行不同的函數。
參考鏈接
- C++—繼承與多態
- C++基礎復習
請你來說一說重載和覆蓋
- 重載:一個類中,兩個函數名相同,但是參數列表不同(個數,類型),返回值類型沒有要求,在同一作用域中
- 重寫:子類繼承了父類,父類中的函數是虛函數,在子類中重新定義了這個虛函數,這種情況是重寫
請你來說一說static關鍵字
- 1.加了static關鍵字的全局變量只能在本文件中使用。例如在a.c中定義了static int a=10;那么在b.c中用extern int a是拿不到a的值,a的作用域只在a.c中。
- 2.static定義的靜態局部變量分配在數據段上,普通的局部變量分配在棧上,會因為函數棧幀的釋放而被釋放掉。
- 3. 對一個類中成員變量和成員函數來說,加了static關鍵字,則此變量/函數就沒有了this指針了,必須通過類名才能訪問
?請你說一說strcpy和strlen
- strcpy是字符串拷貝函數,原型:? char *strcpy(char* dest, const char *src);
- 從src逐字節拷貝到dest,直到遇到'\0'結束,因為沒有指定長度,可能會導致拷貝越界,造成緩沖區溢出漏洞,安全版本是strncpy函數。
- strlen函數是計算字符串長度的函數,返回從開始到'\0'之間的字符個數。
請你說一說你理解的虛函數和多態
- 多態的實現主要分為靜態多態和動態多態,靜態多態主要是重載,在編譯的時候就已經確定;動態多態是用虛函數機制實現的,在運行期間動態綁定。
- 舉個例子:一個父類類型的指針指向一個子類對象時候,使用父類的指針去調用子類中重寫了的父類中的虛函數的時候,會調用子類重寫過后的函數,在父類中聲明為加了virtual關鍵字的函數,在子類中重寫時候不需要加virtual也是虛函數。
- 虛函數的實現:在有虛函數的類中,類的最開始部分是一個虛函數表的指針,這個指針指向一個虛函數表,表中放了虛函數的地址,實際的虛函數在代碼段(.text)中。當子類繼承了父類的時候也會繼承其虛函數表,當子類重寫父類中虛函數時候,會將其繼承到的虛函數表中的地址替換為重新寫的函數地址。使用了虛函數,會增加訪問內存開銷,降低效率。

請你來回答一下++i和i++的區別
- ++i先自增1,再返回,i++先返回i,再自增1
- ++i 實現
int& int::operator++()
{
*this +=1;
return *this;
}- i++
const int int::operator(int)
{
int oldValue = *this;
++(*this);
return oldValue;
}請你來寫個函數在main函數執行前先運行
#include<iostream>__attribute((constructor))void before()
{printf("before main\n");
}int main(){std::cout << "main 函數!" << std::endl;
}
有段代碼寫成了下邊這樣,如果在只修改一個字符的前提下,使代碼輸出20個hello?
- for(int i = 0; i < 20; i--) cout << "hello" << endl;
#include<iostream>int main(){for(int i = 0; i + 20; i--)std::cout << i << " hello" << std::endl;
}請你來說一下智能指針shared_ptr的實現
參考鏈接
- C++11 shared_ptr智能指針(超級詳細)
- 智能指針shared_ptr實現
以下四行代碼的區別是什么?
-
const char * arr = "123"; char * brr = "123"; const char crr[] = "123"; char drr[] = "123";
- const char * arr = "123";? //字符串123保存在常量區,const本來是修飾arr指向的值不能通過arr去修改,但是字符串“123”在常量區,本來就不能改變,所以加不加const效果都一樣
- char * brr = "123";? //字符串123保存在常量區,這個arr指針指向的是同一個位置,同樣不能通過brr去修改"123"的值
- const char crr[] = "123";? //這里123本來是在棧上的,但是編譯器可能會做某些優化,將其放到常量區
- char drr[] = "123";? ?//字符串123保存在棧區,可以通過drr去修改
?請你來說一下C++里是怎么定義常量的?常量存放在內存的哪個位置?
- 常量在C++里的定義就是一個top-level const加上對象類型,常量定義必須初始化。
- 對于局部對象,常量存放在棧區,
- 對于全局對象,常量存放在全局/靜態存儲區。
- 對于字面值常量,常量存放在常量存儲區。
- 會被人打的方式:
#define CONSTANT value - 高級一點的方式:
const auto constant = value; - 最新潮的方式:
constexpr auto constant = value;
補充知識
- constexpr是c++11新添加的特征,目的是將運算盡量放在編譯階段,而不是運行階段。這個從字面上也好理解,const是常量的意思,也就是后面不會發生改變,因此當然可以將計算的過程放在編譯過程。constexpr可以修飾函數、結構體。
- constexpr用法
- 才搞清楚常量的存儲位置
請你來回答一下const修飾成員函數的目的是什么?
- const修飾的成員函數表明函數調用不會對對象做出任何更改,事實上,如果確認不會對對象做更改,就應該為函數加上const限定,這樣無論const對象還是普通對象都可以調用該函數。
OOP(面向對象編程) Vs. GP(泛型編程))







)










![C語言二維數組 int arr[2][3]](http://pic.xiahunao.cn/C語言二維數組 int arr[2][3])