在多線程環境下,使用HashMap進行put操作會引起死循環,導致CPU利用率接近100%,HashMap在并發執行put操作時會引起死循環,是因為多線程會導致HashMap的Entry鏈表
形成環形數據結構,一旦形成環形數據結構,Entry的next節點永遠不為空,就會產生死循環獲取Entry。那么這個死循環是如何生成的呢?我們來仔細分析下。
HashMap擴容流程
原理
引發死循環,是在HashMap的擴容操作中,正常的擴容操作是這個流程。HashMap的擴容在put操作中會觸發擴容,主要是三個方法:



綜合來說,HashMap一次擴容的過程:
1、取當前table的2倍作為新table的大小
2、根據算出的新table的大小new出一個新的Entry數組來,名為newTable
3、輪詢原table的每一個位置,將每個位置上連接的Entry,算出在新table上的位置,并以鏈表形式連接
4、原table上的所有Entry全部輪詢完畢之后,意味著原table上面的所有Entry已經移到了新的table上,HashMap中的table指向newTable
實例
現在hashmap中有三個元素,Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都沖突在table[1]這里了。

按照方法中的代碼
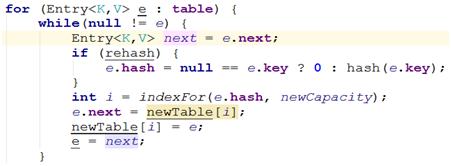
對table[1]中的鏈表來說,進入while循環,此時e=key(3),那么next=key(7),經過計算重新定位e=key(3)在新表中的位置,并把e=key(3)掛在newTable[3]的位置

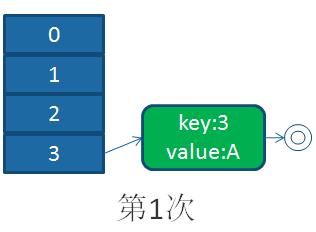
這樣循環下去,將table[1]中的鏈表循環完成后,于是HashMap就完成了擴容
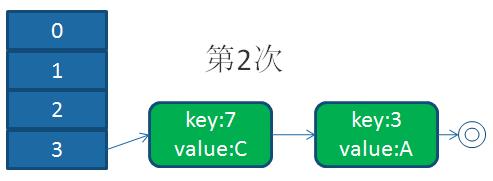
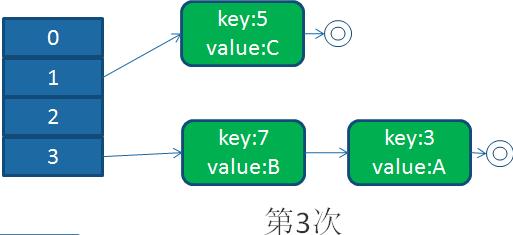
并發下的擴容
上面都是單線程下的擴容,當多線程進行擴容時,會是什么樣子呢?
初始的HashMap還是:

我們現在假設有兩個線程并發操作,都進入了擴容操作, 我們以顏色進行區分兩個線程。

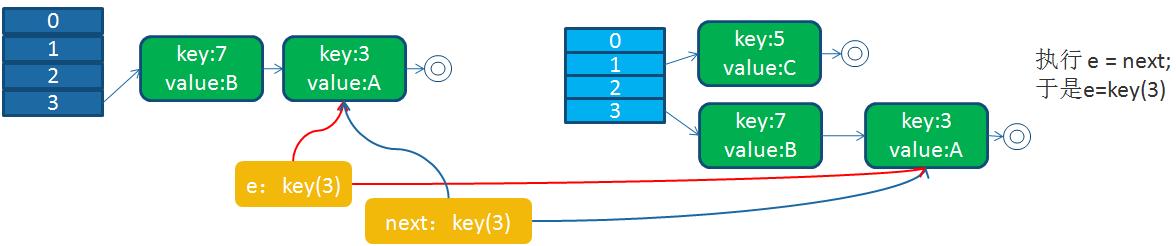
回顧我們的擴容代碼,我們假設,線程1執行到Entry next = e.next;時被操作系統調度掛起了,而線程2執行完成了擴容操作

于是,在線程1,2看來,就應該是這個樣子
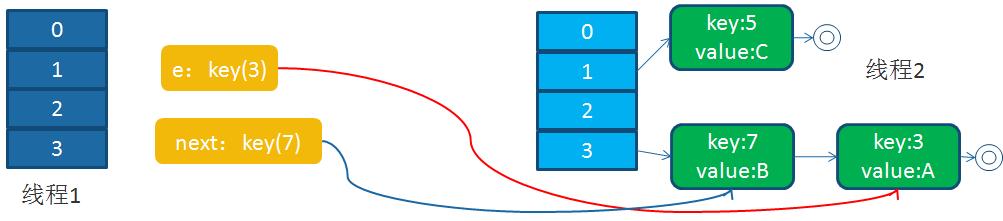
接下來,線程1被調度回來執行:
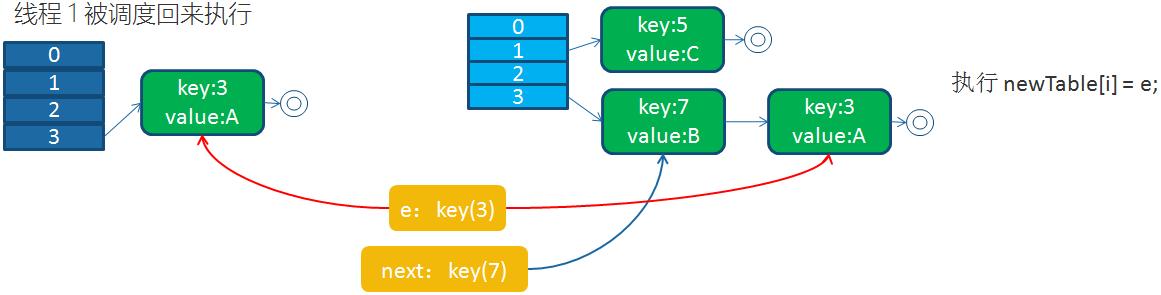
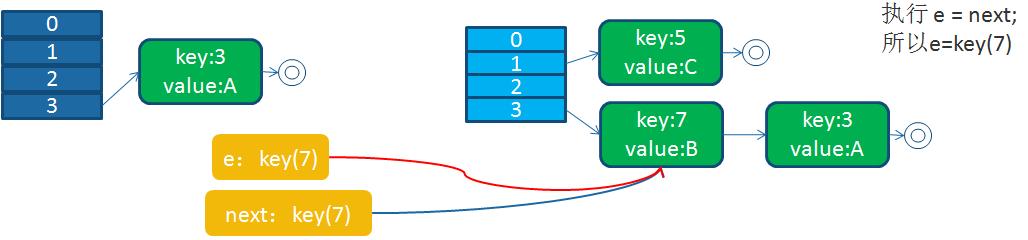
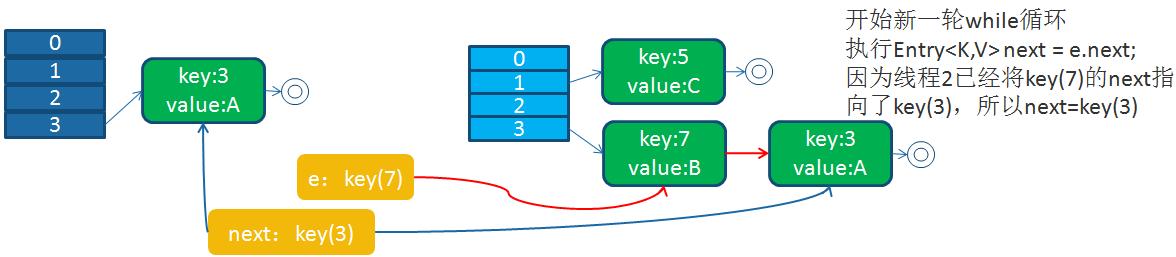

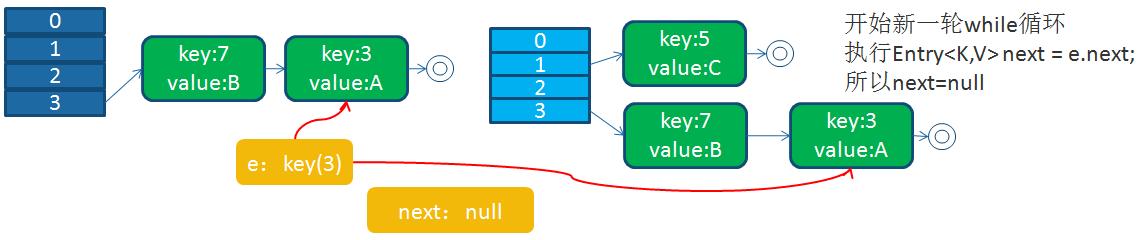
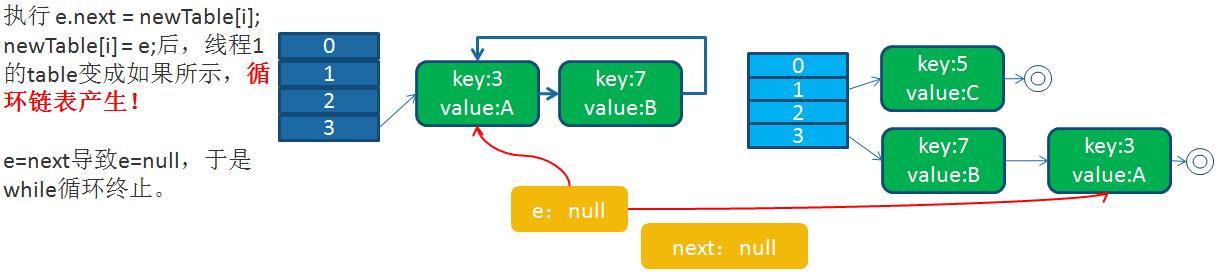
循環列表產生后,一旦線程1調用get(11,15之類的元素)時,就會進入一個死循環的情況,將CPU的消耗到100%。
總結
HashMap之所以在并發下的擴容造成死循環,是因為,多個線程并發進行時,因為一個線程先期完成了擴容,將原的鏈表重新散列到自己的表中,并且鏈表變成了倒序,后一個線程再擴容時,又進行自己的散列,再次將倒序鏈表變為正序鏈表。于是形成了一個環形鏈表,當表中不存在的元素時,造成死循環。
雖然在JDK1.8中,Java的開發小組修正了這個問題,但是HashMap始終存在著其他的線程安全問題。所以在并發情況下,我們應該使用HastTable或者ConcurrentHashMap來代替HashMap。
最后在這分享一下一直以來整理的Java學習資料,大家關注后私聊我,我會免費分享給大家的!

)

_java中double類型精度丟失問題及解決方法](http://pic.xiahunao.cn/double operator[](int i)_java中double類型精度丟失問題及解決方法)








 和 for (;;) 到底哪個更快)






