POST跟GET的區別
作用
- GET用于獲取資源,而POST用于傳輸實體
參數
- GET的參數以字符串的格式出現在URL中,而POST的參數存儲在請求實體中。
- 因為URL只支持ASCII碼,故GET的參數如果存在中文等字符就需要先進行編碼,POST參考支持標準字符集。
安全
- 安全的 HTTP 方法不會改變服務器狀態,也就是說它只是可讀的。
- GET 方法是安全的,而 POST 卻不是,因為 POST 的目的是傳送實體主體內容,這個內容可能是用戶上傳的表單數據,上傳成功之后,服務器可能把這個數據存儲到數據庫中,因此狀態也就發生了改變。
- 安全的方法除了 GET 之外還有:HEAD、OPTIONS。不安全的方法除了 POST 之外還有 PUT、DELETE。
緩存
- 請求報文的HTTP請求是可緩存的,包括GET和HEAD,但是PUT和DELETE不可緩存,POST在多數情況下不可緩存。
冪等性
- 冪等指同樣的請求被執行一次與連續執行多次的效果是一樣的,服務器的狀態也是一樣的。
- 所有的安全方法都是冪等的,在正確實現條件下,GET、POST、HEAD、PUT和DELETE方法都是冪等的,而POST不是。
- 引入冪等主要是為了處理同一個請求多次重復發送的情況,比如在請求相應前失去連接,如果方法時冪等的,就可以放心的重發一次請求。這也是瀏覽器遇到POST會給用戶提示的原因:POST語義不是冪等的,重復請求可能會帶來意想不到的結果。
- 比如在微博這個場景里,GET的語義會被用在[看看我的timeline上最新的20條微博]這樣的場景,而POST的語義會被用在[發微博、點贊、評論]這樣的場景。
本部分參考:
HTTP
get和post的區別
TCP三次握手以及四次揮手
三次握手

A為客戶端、B為服務器端:
- 首先B處理監聽(Listen)狀態,等待客戶端的請求。
- A向B發送連接請求報文,SYN=1,ACK=0,選擇一個初時的序號x。
- B收到連接請求報文之后,如果同意建立連接,則向A發送連接確認報文,SYN=1,ACK=1,選擇初始序號為y,確認序號為x+1。
- A收到B連接確認報文之后,還要想B發出確認,確認號為y+1,序號為x+1。
- B收到A的確認之后,連接建立。
四次揮手
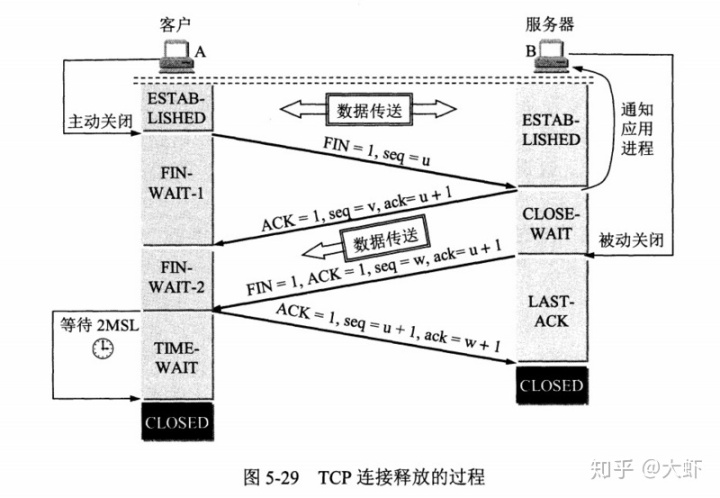
A為客戶端、B為服務器端:
- A發送連接釋放報文,FIN=1,同時選擇序號為u。
- B收到之后發出確認,ACK=1,確認序號為u+1,同時選擇序號v。此時TCP為半關閉狀態,B可以向A發送數據,A不可以向B發送數據。
- 當B不再需要連接之后,想A發送釋放報文,FIN=1,ACK=1,確認序號為u+1,同時序號為w。
- A收到后發出確認,ACK=1,確認序號為w+1,序號為u+1,進入TIME_WAIT狀態,等待2MSL(最大報文存活時間)后釋放連接。
- B收到A確認之后釋放連接。
三次握手的原因
第三次握手時為了防止失效的連接請求到達服務器,讓服務器錯開的打開鏈接。
客戶端發送的連接請求如果在網絡中滯留,那么就會隔很長一段時間才能收到服務端返回的連接確認。客戶端在等待一個超時重傳時間之后,就會重新發送請求連接,那么這個滯留的請求最后還是會到達服務器,如果不進行三次握手,那么服務器就會打開兩個鏈接。
四次揮手的原因
客戶端發送釋放連接報文之后,服務器收到這個報文,就進入了CLOSE_WAIT狀態,這個狀態時為了讓服務器發送還未傳送完成的數據,傳送完畢之后,服務器會發送釋放報文。
TIME_WATI
客戶端接收到服務器端的FIN報文之后進入此狀態,此時并不是直接進入CLOSED狀態,還需要等待一個時間計算器設置的時間2MSL。這么做有兩個原因:
- 確保最后一個確認報文能夠到達,如果服務器沒有收到客戶端發送的確認報文,那么就會重新發送連接釋放請求報文,客戶端等待一段時間就是為了處理這種情況的發生。
- 等待一段時間是為了讓本連接連續時間內所有的報文都從網絡中消失,使得下一個新的連接不會出現舊的連接請求報文。
TCP和UDP的區別
用戶數據報協議UDP(User Datagram Protocal):無連接,盡最大可能交付,沒有擁塞控制,面向報文(對于應用層傳下來的報文不合并也不拆分,只是天界UDP首部),支持一對一、一對多、多對一和多對多的交互通信。
傳輸控制協議TCP(Transmission Control Protocal):面向連接,提供可靠交互,有流量控制,擁塞控制,面向字節流(把應用層傳下來的報文看成字節流,把字節流組織成大小不等的數據塊),每一條TCP連接只能是對對點的(一對一)。
HTTP
長連接和短連接
在HTPP/1.0中默認使用短連接,也就是客戶端每次與服務端進行一次HTTP操作,都要建立一次連接,任務結束就斷開連接。
而從HTTP/1.1起,默認使用長連接,用以保持連接特性。使用長連接的HTTP協議,會在響應頭加入:Connection:keep-alive
在使用長連接的情況下,當一個網頁打開完成之后,客戶端與服務端之間用于傳輸HTTP數據的TCP連接不會關閉,客戶端再次訪問這個服務器時,會繼續使用一條已經建立的連接。Keep-Alive不會永久保持連接,它有一個保持時間。
HTTP協議的長連接和短連接,實質上是TCP協議的長連接和短連接。
HTTP跟HTTPS
HTTP協議傳輸的數據都是未加密的,也就是明文,因此使用HTTP協議傳輸隱私信息非常不安全,為了保證這些隱私數據能加密傳輸,于是就設計出SSL(Secure Sockets Layer)協議用于對HTTP協議傳輸的數據進行加密,從而誕生了HTTPS。
區別
- HTTPS協議需要CA申請證書。
- HTTP是超文本傳輸協議,信息是明文傳輸,HTTPS則是具有安全性的SSL加密傳輸協議。
- HTTP的端口是80,而HTTPS的端口是443。
- HTTP是無狀態的,HTTPS協議是由SSL+HTTP協議構建的可進行加密傳輸、身份認證的網絡協議,比http協議安全。
TCP可靠傳輸
TCP使用超時重傳來實現可靠傳輸,如果一個已經發送的報文段在超時時間內沒有收到確認,那么就重傳這個報文段。
TCP的窗口滑動
窗口是緩存的一部分,用來暫時存放字節流。發送方和接收方各有一個窗口,接收方通過TCP報文段中窗口字段告訴發送方自己的窗口大小,發送方根據這個值和其他信息設置自己的窗口大小。
發送窗口內的字節都允許被發送,接收窗口的字節都允許被接收,如果發送窗口昨部的字節已經發送并且受到確認,那么就講發送窗口向右滑動一定距離,直到左部第一個字節不是已發送并且已確定的狀態。接受窗口類似,接收窗口左部字節已經發送確認并交付主機,講向右滑動窗口。
接收窗口只會對窗口內最后一個按序到達的字節進行確認,例如接收窗口已經收到的字節{31,34,35},其中{31}按序到達,而{34,35}不是,因此只會對字節31進行確認。發送方得到一個字節的確認之后,就知道這個字節之前的所有字節都已經被接收。
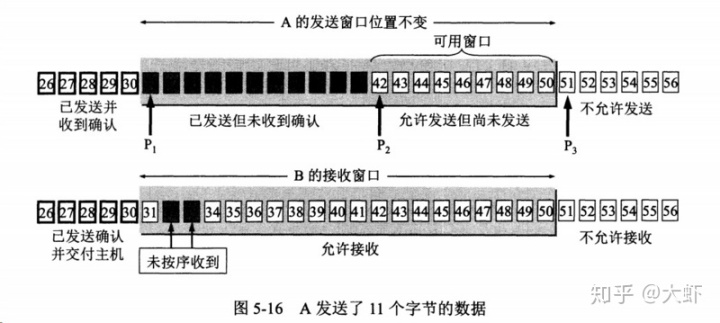
TCP流量控制
流量控制是為了控制發送方發送速率,保證接收方來得及接收。
接收方發送的確認報文中的窗口字段可以用來控制發送窗口大小,從而影響發送方的發送速率。講窗口字段設置為0,則發送方不能發送數據。
TCP擁塞控制
如果網絡出現擁塞,分組將會丟失,此時發送方會繼續重傳,從而導致網絡擁塞程度更高。因此當網絡出現擁塞時,應當控制發送方的速率。這一點跟流量控制很像,但是出發點不同。流量控制是為了讓接收方能來得及接收,而擁塞控制是為了降低整個網絡的擁塞程度。
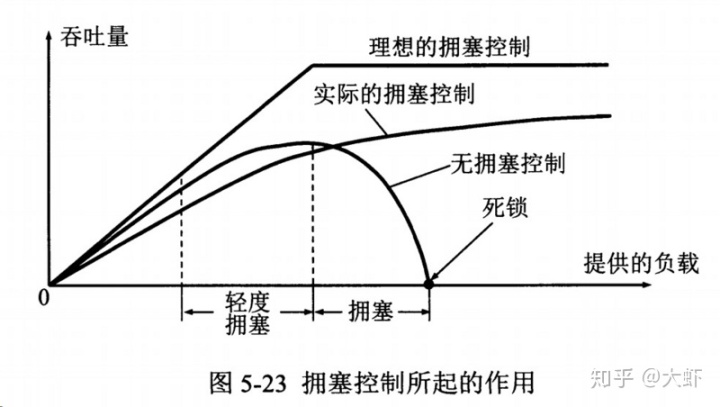
TCP主要通過四種算法來進行擁塞控制:慢開始、擁塞避免、快回復、快重傳。
發送方需要維護一個擁塞窗口(cwnd)的狀態變量,注意擁塞窗口跟發送方窗口的區別,擁塞窗口只是一個狀態變量,實際決定發送方能發送多少數據是發送方窗口。
為了方便討論,做如下假設:
- 接收方有足夠大的接收緩存,因此不會發送流量控制。
- 雖然TCP的窗口基于字節,但是這里設窗口的大小單位為報文段。

慢開始與擁塞避免
發送最初執行慢開始,令cwnd=1,發送方只能發送1個報文段,當收到確認后,令cwnd加倍,因此之后發送方能夠發送的報文段數量為:2、4、8...
注意到沒開始每個輪次都講cwnd加倍,這樣會讓cwnd增長速度非常快,從而發送方的發送速率增長過快,網絡擁塞的可能就越高。設置一個慢開始門限ssthresh,當cwnd >= ssthresh時,進入擁塞避免,每個輪次只將cwnd加1。
如果出現了超時,則令ssthresh = cwnd / 2,然后重新執行慢開始。
快恢復和快重傳
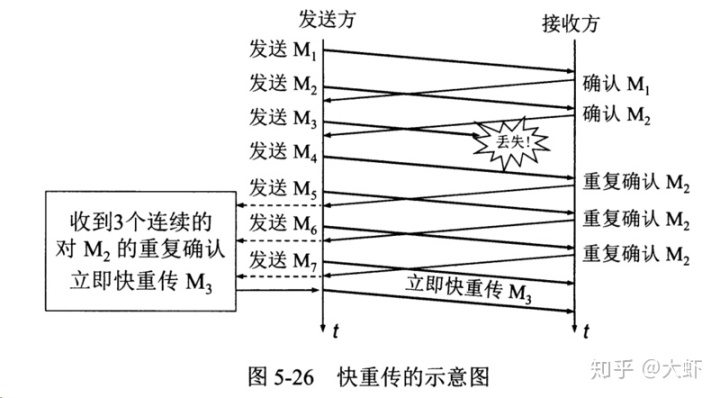
在接收方,要求每次接收到報文段都應該對最后一個已收到的有序報文段進行確認,例如接收到M1和M2,此時收到M4,應當發送M2的確認。
在發送方,如果收到三個重復確認,那么就可以知道下一個報文段丟失,此時執行快重傳,立即重傳下一個報文段。例如收到三個M2,則M3丟失,立即重傳M3。
在這種情況下,只是丟失個別報文段,而不是網絡擁塞。因此執行快恢復,令ssthresh = cwnd / 2,cwnd = ssthresh,注意此時直接進入擁塞避免。
慢開始和快恢復的快慢指的是cwnd的設定值,而不是cwnd的增長速率。慢開始cwnd設定為1,而快恢復cwnd設定為ssthresh。
TCP拆包跟粘包
TCP是個面向字節流協議,就是沒有界限的一串數據,大家可以想想河里的流水,是連成一片的,其間并沒有分界線。TCP底層并不了解上層業務數據的具體含義,它會根據TCP緩存區的實際情況進行包的劃分。所以業務上認為,一個完整的包可能會被TCP拆分為多個包進行發送也有可能多個小的包封裝成一個大的數據包發送,這就是所謂的TCP粘包和拆包問題。
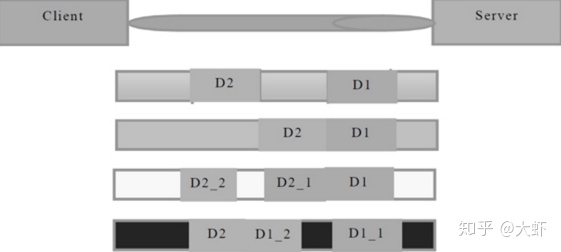
產生原因:
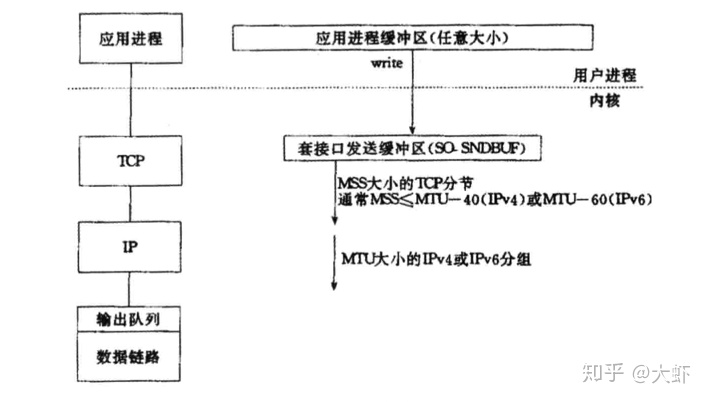
- 應用程序write寫入的字節大小大于套接字發送緩存區的大小。
- 進行MSS大小的TCP分段。
- 以太網的payload大于MTU進行IP分片。
解決策略:
由于底層的TCP無法理解上層的業務數據,所以在底層是無法保證用戶數據包不被拆分和重組的,這個問題只能通過上層的應用協議棧設計來解決,根據業界的主流協議的解決方案,可以歸納如下:
- 消息定長,規定每個報文的大小固定為200字節,如果不夠,空位補空格。
- 在包尾添加換行符進行分割,例如FTP協議。
- 將消息分為消息頭和消息體,消息頭包含表示消息總長度(或消息體長度)的字段,通常設計思路為消息頭的第一個字段使用int32來表示消息的總長度。
- 更復雜的應用層協議。
Cookie跟Session
- HTTP是一種無狀態的協議,無法分辨連接是誰發起的,Cookie跟Session就是為了解決這個問題的機制。
Cookie
Cookie 是服務器發送到用戶瀏覽器并保存在本地的一小塊數據,它會在瀏覽器之后向同一服務器再次發起請求時被攜帶上,用于告知服務端兩個請求是否來自同一瀏覽器。由于之后每次請求都會需要攜帶 Cookie 數據,因此會帶來額外的性能開銷(尤其是在移動環境下)。
Cookie 曾一度用于客戶端數據的存儲,因為當時并沒有其它合適的存儲辦法而作為唯一的存儲手段,但現在隨著現代瀏覽器開始支持各種各樣的存儲方式,Cookie 漸漸被淘汰。新的瀏覽器 API 已經允許開發者直接將數據存儲到本地,如使用 Web storage API (本地存儲和會話存儲)或 IndexedDB。
Session
存在服務器的一種用來存放用戶數據的類HashTable結構。
瀏覽器第一次發送請求時,服務器自動生成了一HashTable和一Session ID來唯一標識這個HashTable,并將其通過響應發送到瀏覽器。瀏覽器第二次發送請求會將前一次服務器響應中的Session ID放在請求中一并發送到服務器上,服務器從請求中提取出Session ID,并和保存的所有Session ID進行對比,找到這個用戶對應的HashTable。
一般這個值會有個時間限制,超時后毀掉這個值,默認30分鐘。
區別
- Cookie數據存放在瀏覽器,session數據存放在服務器上。
- Cookie數據不是很安全,別人可以分析放在本地Cookie進行Cookie欺騙。
- Session會在一定時間保存在服務器,當訪問增多時,會占有服務器性能。
跨域
跨域指發起請求的域與該請求指向的資源所在的域不一樣。
同域指:協議+域名+端口號均相同。
通常瀏覽器會對跨域做出限制,瀏覽器之所以要對跨域請求做出限制,是處于安全方法的考慮,因為跨域請求可能被不法分子利用來發動CSRF攻擊。
跨域的解決方式
JSONP
- JSONP是一種非官方的跨域數據交互協議,其本質上是利用<script><img><iframe>等標簽不受同源策略限制,可以從不用域加載并執行資源的特性,來實現數據跨域傳輸。
- JSONP有兩部分組成,回調函數和數據,回調函數是當響應到來時應該在頁面中調用的函數,而數據就是傳入回調函數中的JSON數據。
- JSONP的理念是,與服務端Javascript代碼中調用了約定好的回調函數,并且將數據作為參數進行傳遞。當網頁接收到這段javascript代碼后,就會執行這個回調函數,這時數據已經成功傳輸到客戶端了。
CORS
跨域資源共享Cross-Origin Resource sharing是一種新的W3C的標準,它新增的一組HTTP首部字段,運行服務端起聲明哪些源站有權限訪問哪些資源。
HTTP協議Header解析
CORS 中新增的 HTTP 首部字段:
- Access-Control-Allow-Origin:響應首部中可以攜帶這個頭部表示服務器允許哪些域可以訪問該資源。
- Access-Control-Allow-Methods:該首部字段用戶預測請求的響應,指明實際請求所允許使用的HTTP方法。
- Access-Control-Allow-Header:允許攜帶的首部字段。
- Access-Control-Max-Age:請求能被緩存多久。
- Access-Control-Allow-Credentials:可選,是否允許發送cookie。
- Origin:請求源站,不管是否跨域,Origin字段總是被發送。
- Access-Control-Request-Method:實際請求的方法。
- Access-Control-Request-Header:實際請求所攜帶的首部。
參考
HTTP長連接、短連接究竟是什么
HTTP與HTTPS的區別
什么是跨域請求以及實現跨域的方案



【第三卷:從仿函數到std::function再到虛幻4Delegate】...)

與vw)





萬字長文,慎點。)







