作者介紹
李鑫,滴滴資深軟件開發工程師,多年分布式存儲領域設計及開發經驗。曾參與NoSQL/NewSQL數據庫Fusion、分布式時序數據庫sentry、NewSQL數據庫SDB等系統的設計開發工作。
一、背景
Fusion-NewSQL是由滴滴自研的在分布式KV存儲基礎上構建的NewSQL存儲系統。Fusion-NewSQ兼容了MySQL協議,支持二級索引功能,提供超大規模數據持久化存儲和高性能讀寫。
我們的問題滴滴的業務快速持續發展,數據量和請求量急劇增長,對存儲系統等壓力與日俱增。雖然分庫分表在一定程度上可以解決數據量和請求增加的需求,但是由于滴滴多條業務線(快車、專車、兩輪車等)的業務快速變化,數據庫加字段加索引的需求非常頻繁,分庫分表方案對于頻繁的Schema變更操作并不友好,會導致DBA任務繁重,變更周期長,并且對巨大的表操作還會對線上有一定影響。同時,分庫分表方案對二級索引支持不友好或者根本不支持。鑒于上述情況,NewSQL數據庫方案就成為我們解決業務問題的一個方向。
開源產品調研最開始,我們調研了開源的分布式NewSQL方案TiDB。雖然TiDB是非常優秀的NewSQL產品,但是對于我們的業務場景來說,TiDB并不是非常適合,原因如下:
我們需要一款高吞吐,低延遲的數據庫解決方案,但是TiDB由于要滿足事務,2pc方案天然無法滿足低延遲(100ms以內的99rt,甚至50ms內的99rt)。
我們的多數業務,并不真正需要分布式事務,或者說可以通過其他補償機制,繞過分布式事務。這是由于業務場景決定的。
TiDB三副本的存儲空間成本相對比較高。
我們內部一些離線數據導入在線系統的場景,不能直接和TiDB打通。
基于以上原因,我們開啟了自研符合自己業務需求的NewSQL之路。
我們的基礎我們并沒有打算從0開發一個完備的NewSQL系統,而是在自研的分布式KV存儲Fusion的基礎上構建一個能滿足我們業務場景的NewSQL。Fusion是采用了Codis架構,兼容Redis協議和數據結構,使用RocksDB作為存儲引擎的NoSQL數據庫。Fusion在滴滴內部已經有幾百個業務在使用,是滴滴主要的在線存儲之一。
Fusion的架構圖如下:
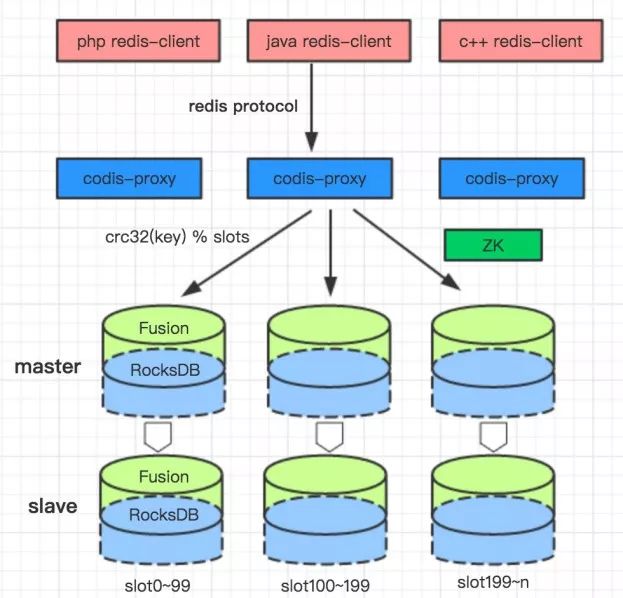
我們采用hash分片的方式來做數據sharding。從上往下看,用戶通過Redis協議的客戶端就可以訪問Fusion,用戶的訪問請求發到proxy,再由proxy轉發數據到后端Fusion的數據節點。proxy到后端數據節點的轉發,是根據請求的key計算hash值,然后對slot分片數取余,得到一個固定的slotid,每個slotid會固定的映射到一個存儲節點,以此解決數據路由問題。
有了一個高并發,低延遲,大容量的存儲層后,我們要做的就是在之上構建MySQL協議以及二級索引。那么如何將MySQL的數據格式轉成Redis的數據結構存儲就是我們必須面臨的問題,后面會詳細說。
二、需求
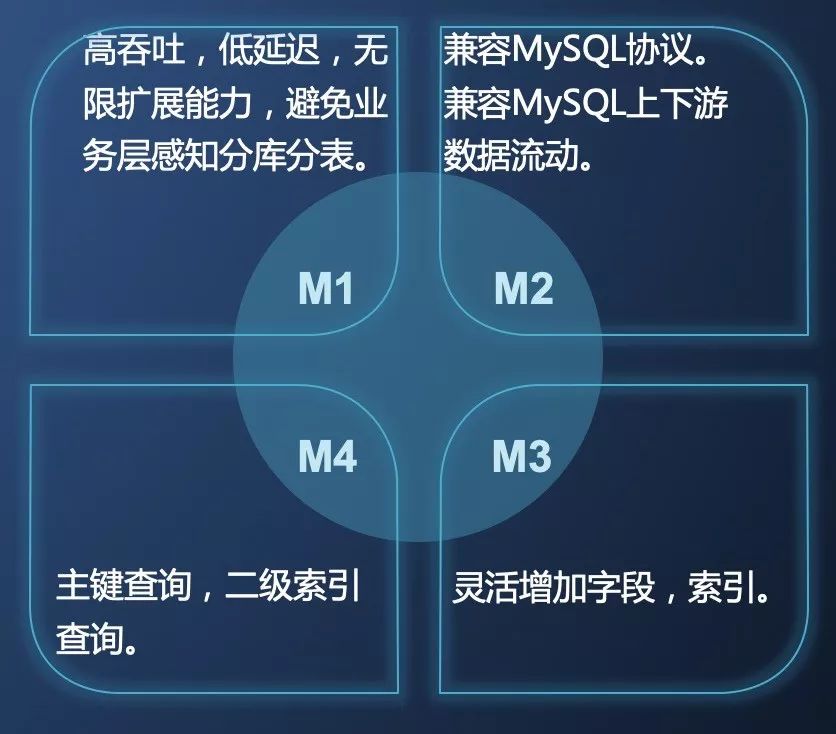
綜合考慮大多數用戶對需求,我們整理了我們的NewSQL需要提供的幾個核心能力:
高吞吐,低延遲,大容量。
兼容MySQL協議及下游生態。
支持主鍵查詢和二級索引查詢。
Schema變更靈活,不影響線上服務穩定性。
三、架構設計
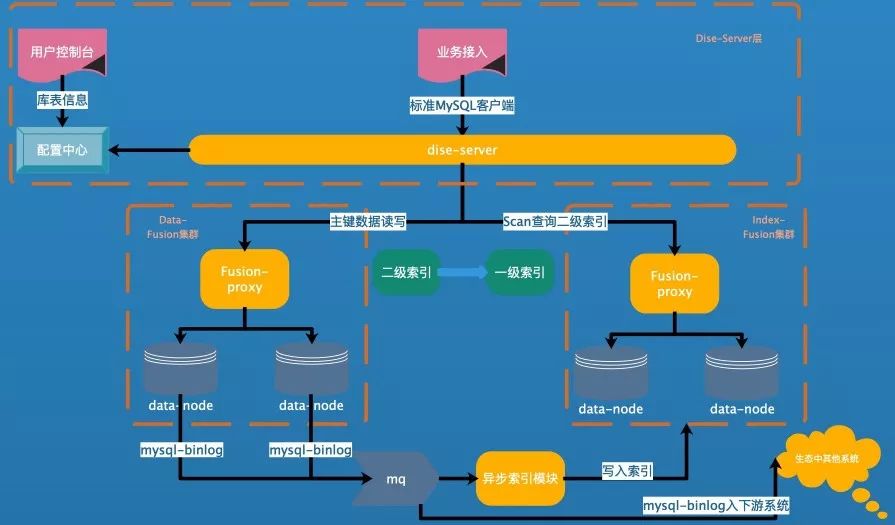
Fusion-NewSQL由下面幾個部分組成:
解析MySQL協議的DiseServer;
存儲數據的Fusion集群-Data集群;
存儲索引信息的Fusion集群-Index集群;
負責Schema的管理配置中心-ConfigServer;
異步構建索引程序-Consumer負責消費Data集群寫到MQ中的MySQL-Binlog格式數據,根據schema信息,生成索引數據寫入Index集群;
外部依賴,MQ,Zookeeper。
架構圖如下:
四、詳細設計
存儲結構MySQL的表結構數據如何轉成Redis的數據結構是我們面臨的第一個問題。
如下圖:
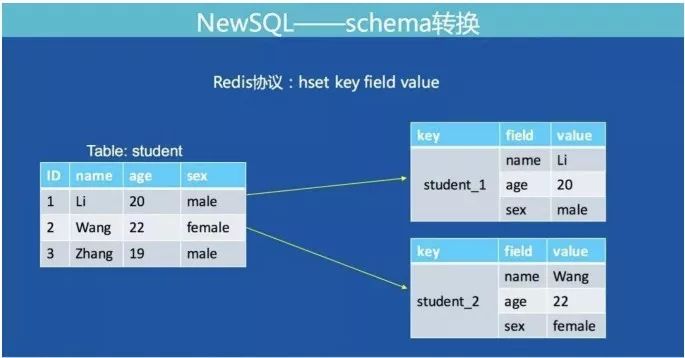
我們將MySQL表的一行記錄轉成Redis的一個Hashmap結構。Hashmap的key由表名+主鍵值組成,滿足了全局唯一的特性。下圖展示了MySQL通過主鍵查詢轉換為Redis協議的方式:
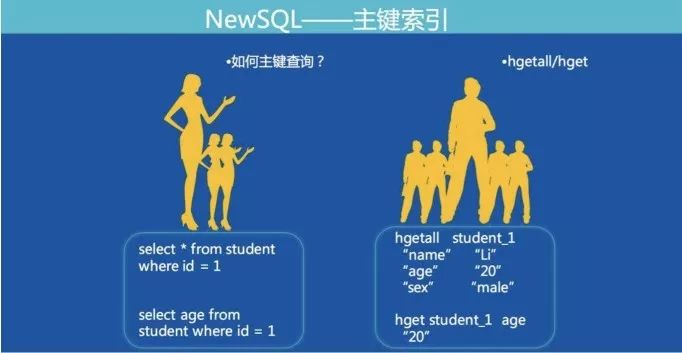
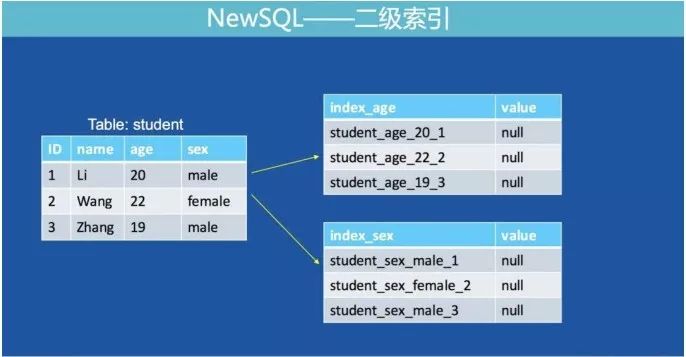
除了數據,索引也需要存儲在Fusion-NewSQL中,和數據存成hashmap不同,索引存儲成key-value結構。根據索引類型不同,組成key-value的格式還有一點細微的差別(下面的格式為了看起來直觀,實際上分隔符,indexname都是做過編碼的):
唯一索引:
Key:?
table_indexname_indexColumnsValue?
Value: Rowkey
非唯一索引:
Key:?
table_indexname_indexColumnsValue_Rowkey?
Value:null
造成這種差異的原因就是非唯一索引在加入Rowkey之前的部分是有可能重復的,無法全局唯一。另外,唯一索引不將Rowkey編碼在key中,是因為在查詢語句是單純的“=”查詢的時候直接get操作就可以找到對應的Rowkey內容,而不需要通過scan,這樣的效率更高。
后面會在查詢流程中重點講述如何通過二級索引查詢到數據。
數據讀寫流程1)數據寫入
用戶通過MySQL-sdk將協議發給dise-server;
dise-server根據schema對用戶寫入的SQL做校驗;
dise-server將校驗通過的SQL轉成Redis的Hashmap結構,通過Redis協議發給Data集群;
Data集群將數據寫入wal文件,并將數據存儲rocksdb;
Data集群后臺線程將wal文件消費,轉成MySQL-Binlog格式。將數據發到MQ;
異步索引模塊消費MQ,將MySQL-Binlog根據操作類型(insert,update,delete)配合schema信息,構建索引信息,并將索引數據寫入index集群。
通過上面的鏈路,用戶的一條MySQL寫操作就完成了數據存儲和索引構建。由于通過數據構建索引這一步是通過MQ異步完成,所以會存在數據和索引有一定的時間差的情況。
2)查詢
下面是一個使用二級索引查詢數據的案例:
dise-server接收到SQL查詢,根據條件,選擇索引,如果沒有命中任何索引,給用戶返回錯誤(Fusion-NewSQL不能以非索引字段作為查詢條件)。
根據選中的索引,構建查詢范圍,通過scan命令遍歷Index集群,獲取符合條件的主鍵集合。下圖以一個SQL查詢,展示使用scan遍歷二級索引的例子:

根據主鍵,通過hgetall命令向Data集群查詢符合條件的結果集。
將結果集構建成MySQL的結果返回給用戶。
根據上面索引數據的格式可以看到,scan范圍的時候,前綴必須固定,映射到SQL語句到時候,意味著where到條件中,范圍查詢只能有一個字段,而不能多個字段。比如:

索引是age和name兩個字段的聯合索引。如果查詢語句如下:
select * from student where age > 20 and name >‘W’;
scan就沒有辦法確定前綴,也就無法通過index_age_name這個索引查詢到滿足條件的數據,所以使用KV形式存儲到索引只能滿足where條件中有一個字段是范圍查詢。當然可以通過將聯合索引分開存放,多次交互搜索取交集的方式解決,但是這就和我們降低RPC次數,降低延遲的設計初衷相違背了。為了解決這個問題,我們引入了Elastic Search搜索引擎,這部分后面會詳細說明。
Schema變更用戶涉及Schema變更時,會以工單形式發給管控系統。管控系統審批過后,會將變更請求推給配置中心,配置中心進行安全性檢查后,將新的Schema寫入到存儲中,并給各個節點推送變更。
字段變更:
節點接收到推送,更新本地的Schema。對于歷史數據,并不真正去修改數據,而是在查詢的時候,根據Schema信息匹配字段,如果數據比Schema缺失某些字段,就使用默認值代替;如果數據比Schema多了字段,就隱藏掉多余字段不展示。
新增索引分為兩步處理:
新增索引,歷史數據不處理,增量數據立刻走索引構建流程。
通過歷史索引構建工具,掃描歷史數據,構建新索引的KV,將歷史數據完成索引構建。這里有個優化點,掃描slave而不是master,避免對線上產生影響。
五、生態構建
一個單獨的存儲產品解決所有問題的時代早已經過去,數據孤島是沒有辦法很好服務業務的,Fusion-NewSQL從設計的那天起就考慮了和其他存儲系統的打通。
Fusion-NewSQL到其他存儲系統Fusion-NewSQL通過兼容MySQL的Binlog格式,將數據發到MQ中。下游各個系統凡是能接入MySQL數據的,都可以通過消費MQ中相同格式的Fusion-NewSQL數據,將數據存到其他系統中。這樣的方式用最小的工作量最大程度做到了兼容。
Hive到Fusion-NewSQLFusion-NewSQL還支持將離線的Hive表中的數據通過Fusion-NewSQL提供的FastLoad(DTS)工具,將Hive表數據轉入到Fusion-NewSQL,滿足離線數據到在線的數據流動。
如果用戶自己完成數據流轉,一般會掃描Hive表,然后構建MySQL的寫入語句,一條條將數據寫入到Fusion-NewSQL,流程如下面這樣:
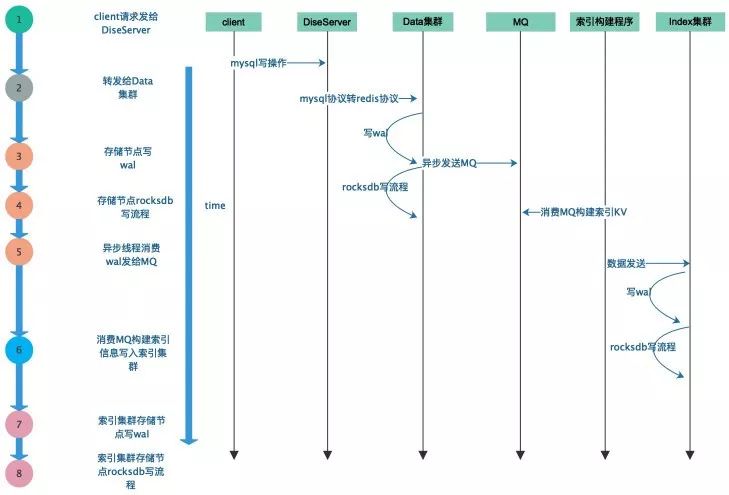
MySQL-client將寫請求發給DiseServer。
DiseServer將MySQL寫做解析,轉成hashmap將轉換后的數據以Redis協議發給Data集群。
Data集群的存儲節點收到數據,將數據寫到wal文件。
Data集群的存儲節點走RocksDB的寫流程,這里包括了寫memtable,還有可能memtable寫滿,發生flush以及觸發后臺的compact。
異步線程消費wal,將數據構建MySQL-Binlog格式發到MQ。
異步索引程序消費MySQL-Binlog,構建Index集群需要的數據,向Index集群發送寫入請求。
Index集群的存儲節點寫wal。
Index集群的存儲節點進入RocksDB的寫流程。
從上面的流程可以看出這種遷移方式有幾個痛點:
有這種Hive到Fusion-NewSQL數據導入需求的用戶都需要開發一套相同邏輯的代碼,維護成本高。
每條Hive數據都要經過較長鏈路,數據導入耗時較長。
離線平臺的數據量大,吞吐高,直接大幅提升在線系統的QPS,對在線系統的穩定性有較大影響。
基于上述的痛點,我們設計了Fastload數據導入平臺,通過約定Hive到Fusion-NewSQL的表格式,使用Hadoop并發處理數據,并構建RocksDB能識別的sst存儲文件,繞過復雜的DISE寫鏈路,直接將數據導入到Fusion-NewSQL中,流程如下:
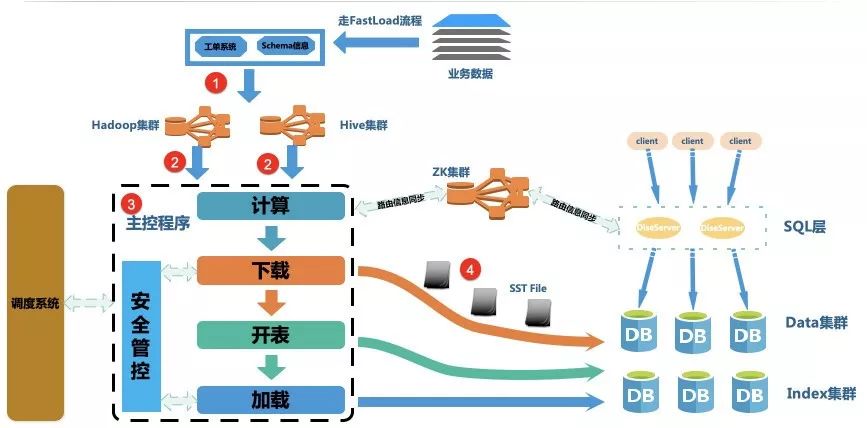
用戶填寫工單,選中將指定Hive表的某些字段映射為Fusion-NewSQL表的字段(這里可以Hive中多個字段組成一個Fusion-NewSQL字段)。
Hadoop遍歷Hive表,并且通過Zookeeper獲取數據應該存放在Data集群和Index集群的路由信息。
通過上面的遍歷,計算,之后,將數據直接構建成、Rocksdb能識別的sst,并且其中存的數據已經是按DISE的表結構信息組成的KV數據。
將sst文件直接發送到指定的存儲節點,存儲節點或通過Rocksdb提供的ingest功能,直接將sst文件加載到Fusion-NewSQL中,用戶可以讀到。
這個方案避免了冗長復雜的寫鏈路,同時不會增加系統的QPS,在磁盤和網絡IO沒有達到瓶頸的情況下對線上訪問幾乎是沒有任何影響;同時,用戶只需要填寫Hive到Fusion-NewSQL的Schema映射關系即可,不必再關心實現。
通過ElasticSearch實現復雜查詢在業務使用MySQL或Fusion-NewSQL的過程中,我們發現有這樣一種場景:業務的查詢條件很復雜,涉及的字段數,條件,聚合都比較多,這種場景下,業務會選擇將ElasticSearch作為MySQL或Fusion-NewSQL的下游,將數據導入Elastic Search,然后通過ElasticSearch豐富的搜索能力,先從ElasticSearch中獲取數據在MySQL或Fusion-NewSQL的主鍵,然后再根據主鍵獲取全部數據。
根據上面的場景,Fusion-NewSQL提供一個特殊的索引類型:ES。用戶在創建索引的時候,可以將需要做復雜查詢的字段勾選出來,共同構建成一個ES索引,這樣既滿足了業務需求,避免了每個業務都需要開發一套和ElasticSearch交互的復雜邏輯,又統一了數據庫使用接口都為MySQL。同時,還彌補了前面提到的Fusion-NewSQL的KV二級索引不能支持多個字段范圍檢索的能力。
架構圖如下:
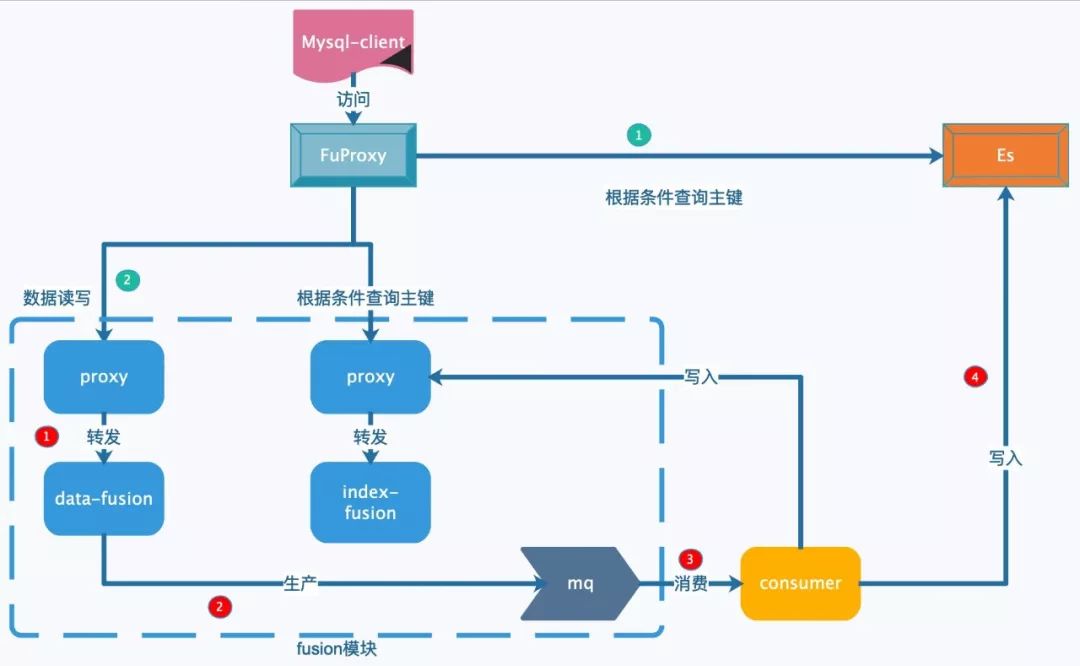
ES索引只是在上圖紅4處,將ES索引中包含的字段信息和主鍵寫入到ElasticSearch中。在查詢時綠1如果選中了ES類型的索引,就根據where條件中涉及的字段,組裝成ElasticSearch的DSL語句,從ElasticSearch獲取主鍵,再從Data集群獲取。由于ElasticSearch查詢的延遲比較慢,Fusion-NewSQL可以支持一張表的多個索引采用KV索引和ES索引并存,對于延遲要求高,查詢條件相對簡單的使用KV索引;對于查詢條件復雜,延遲要求不高的使用ES索引。
六、總結
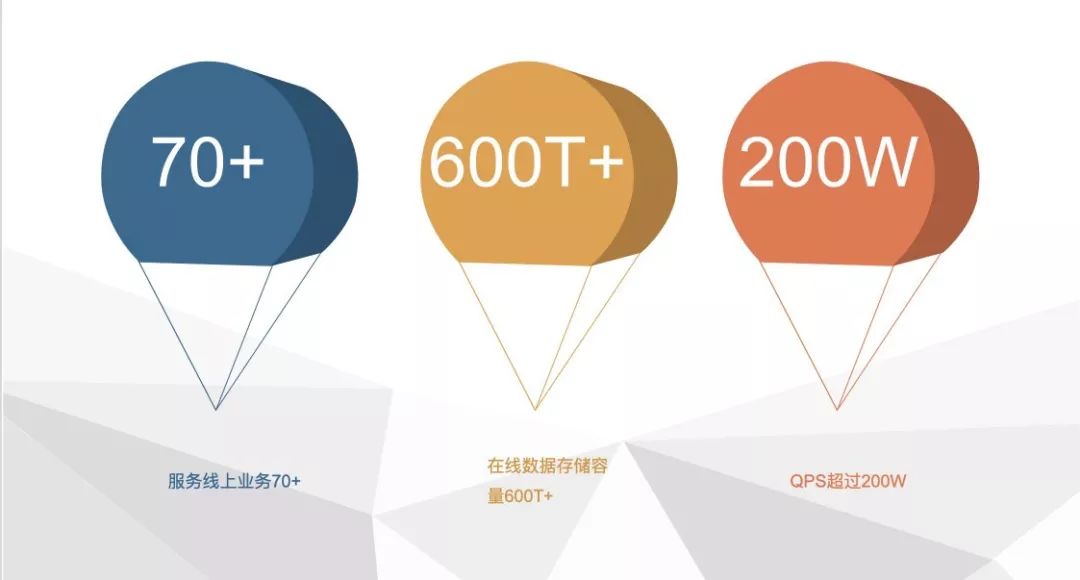
Fusion-NewSQL當前已經接入訂單、預估、賬單、用戶中心、交易引擎等70個核心業務,總QPS超過200W,總數據超過600TB。
當然,Fusion-New不是一個通用完備的NewSQL方案,而是在已有的NoSQL數據庫基礎上,通過對SQL協議的支持以及組合各種組件,構建一個對外表達的數據庫,但是這種方式,可以以最小的開發代價,滿足大多數的業務場景,具備較高的投入產出比。?
七、后續工作
有限制的事物支持,比如讓業務規劃落在一個節點的數據可以支持單機跨行事務。
實時索引替代異步索引,滿足即寫即讀。目前已經有一個寫穿+補償機制的方案,在沒有分布式事務的前提下滿足正常狀態的實時索引,異常情況下保證數據索引最終一致的方案。
更多的SQL協議和功能支持。
參與相關討論,請在公眾號回復關鍵詞:讀者群。
參與相關討論,請在公眾號回復關鍵詞:讀者群。
往期推薦? ??? ?架構師技術領導力成長之路
初創型公司,如何選擇技術方案?
單機和分布式場景下,流控方案大全
干貨 | 攜程容器偶發性超時問題案例
DDD如何講清楚,做出來?
? ? ???……
? ?關注本公眾號,歡迎訂閱。
技術瑣話?
以分布式設計、架構、體系思想為基礎,兼論研發相關的點點滴滴,不限于代碼、質量體系和研發管理。本號由坐館老司機技術團隊維護。













)




...)

