Java大文本并行計算實現過程解析
簡單提高文本讀取效率,使用BufferedReader是個不錯的選擇。速度最快的方法是MappedByteBuffer,但是,相比BufferedReader而言,效果不是非常明顯。也就是說,后者雖然快,但也快的有限(不要抱有性能提升幾倍的幻想)。
對于大文本的讀取,性能瓶頸主要在IO,read占時間多是正常的,硬盤本身就不快,讀入內存后還要轉成對象,都比較耗時間。
想要提速應當用并行的辦法,用多線程同時讀取和處理數據,但Java寫多線程程序很麻煩,并行分段讀同一個文件時還要考慮調整邊界,也比較麻煩。
比如要這么個場景:分組匯總每個客戶的銷售額,部分源數據如下:
O_ORDERKEY O_CUSTKEY O_ORDERDATE O_TOTALPRICE
10262 RATTC 1996-07-22 14487.0
10263 ERNSH 1996-07-23 43818.0
10264 FOLKO 2007-07-24 1101.0
10265 BLONP 1996-07-25 5528.0
10266 WARTH 1996-07-26 7719.0
10267 FRANK 1996-07-29 20858.0
10268 GROSR 1996-07-30 19887.0
10269 WHITC 1996-07-31 456.0
10270 WARTH 1996-08-01 13654.0
...
期望的結果:
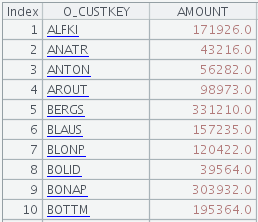
如果有集算器就簡單多了,它對Java的多線程進行了封裝,提供了對大文件分段并行的功能,寫起來容易多了,對人員要求也低。比如上面問題,2行就搞定了(集算器內置了并行選項@m,不設置并行數,默認按核數做為并行數):
=file("/workspace/orders.txt").cursor@mt()
=A1.groups(O_CUSTKEY;sum(O_TOTALPRICE):AMOUNT)
Java大文本并行計算實現過程解析相關教程


--SpringMVC入門)














...)

