文章目錄
- 目錄
- 什么是數據不平衡問題?
- 數據不平衡會造成什么影響?
- 如何處理數據不平衡問題?
- 1、重新采樣訓練集
- 1.1隨機欠抽樣
- 1.2.基于聚類的過采樣
- 2.使用K-fold交叉驗證
- 3.轉化為一分類問題
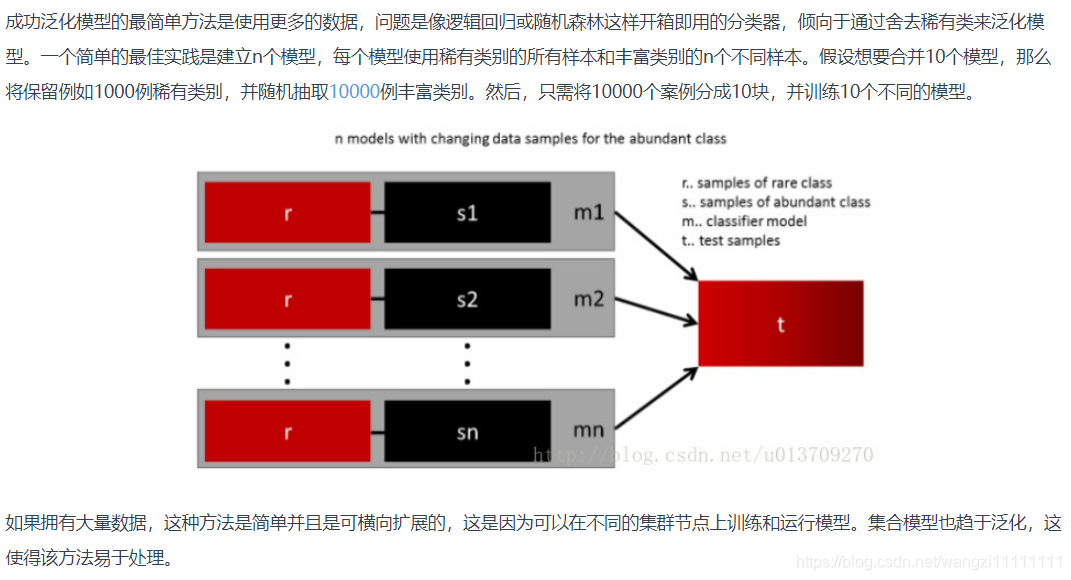
- 4.組合不同的重采樣數據集
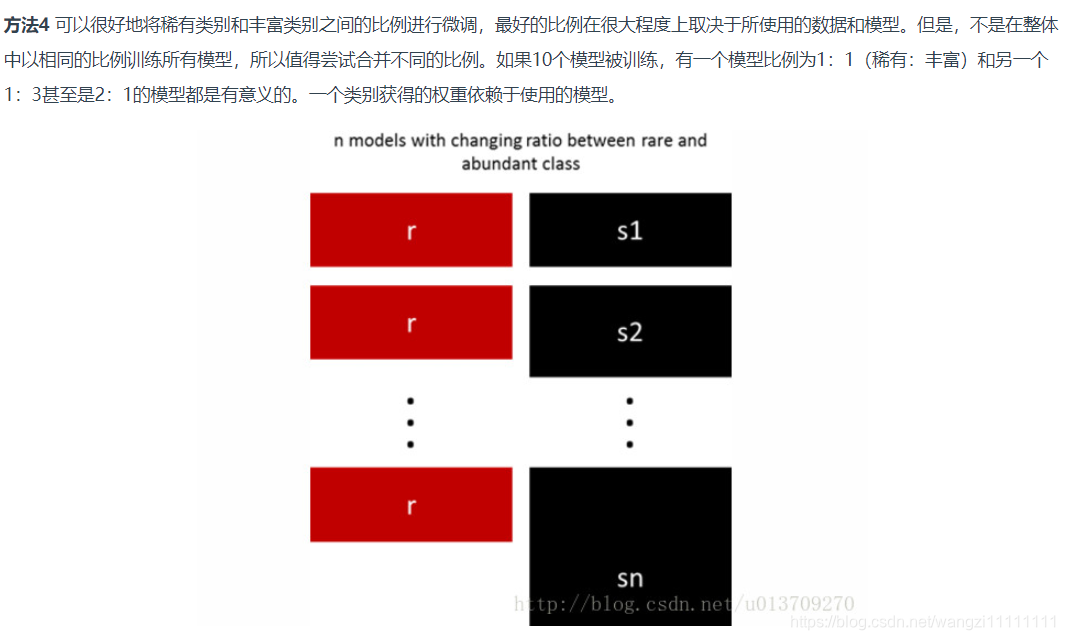
- 5.用不同比例重新采樣
- 6.多模型Bagging
- 7.集群豐富類
- 8.設計適用于不平衡數據集的模型
- 總結:
目錄
什么是數據不平衡問題?
在學術研究與教學中,很多算法都有一個基本假設,那就是數據分布是均勻的。當我們把這些算法直接應用于實際數據時,大多數情況下都無法取得理想的結果。因為實際數據往往分布得很不均勻,都會存在“長尾現象”,也就是所謂的“二八原理”。
在處理機器學習等數據科學問題時,經常會碰到不均衡種類分布的情況,即在樣本數據中一個或多個種類的觀察值明顯少于其他種類的觀察值的現象。在我們更關心少數類的問題時這個現象會非常突出,例如竊電問題、銀行詐騙性交易、罕見病鑒定等。在這種情況下,運用常規的機器學習算法的預測模型可能會無法準確預測。這是因為機器學習算法通常是通過減少錯誤來增加準確性,而不考慮種類的平衡。這篇文章講了不同的方法來解決這個不均衡分類問題,同時說明了這些方法的好處和壞處。

數據不平衡會造成什么影響?
不平衡程度相同(即正負樣本比例類似)的兩個問題,解決的難易程度也可能不同,因為問題難易程度還取決于我們所擁有數據有多大。比如在預測微博互動數的問題中,雖然數據不平衡,但每個檔位的數據量都很大——最少的類別也有幾萬個樣本,這樣的問題通常比較容易解決;而在癌癥診斷的場景中,因為患癌癥的人本來就很少,所以數據不但不平衡,樣本數還非常少,這樣的問題就非常棘手。綜上,可以把問題根據難度從小到大排個序:大數據+分布均衡<大數據+分布不均衡<小數據+數據均衡<小數據+數據不均衡。對于需要解決的問題,拿到數據后,首先統計可用訓練數據有多大,然后再觀察數據分布情況。經驗表明,訓練數據中每個類別有5000個以上樣本,數據量是足夠的,正負樣本差一個數量級以內是可以接受的,不太需要考慮數據不平衡問題(完全是經驗,沒有理論依據,僅供參考)。

如何處理數據不平衡問題?
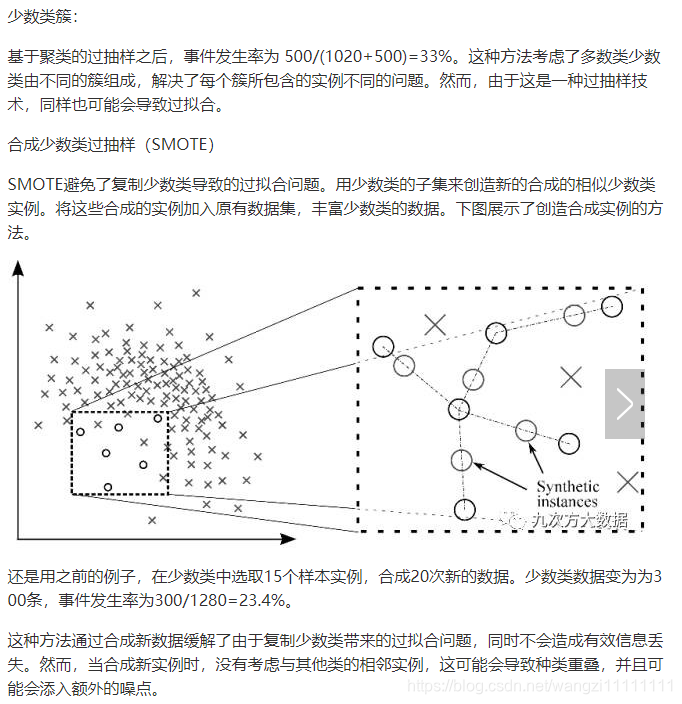
在將數據用于建模之前,先運用重抽樣技術使數據變平衡。平衡數據主要通過兩種方式達到:增加少數類的頻率或減少多數類的頻率。通過重抽樣來改變兩個種類所占的比例。
1、重新采樣訓練集
1.1隨機欠抽樣

1.2.基于聚類的過采樣


2.使用K-fold交叉驗證
值得注意的是,使用過采樣方法來解決不平衡問題時應適當地應用交叉驗證。這是因為過采樣會觀察到罕見的樣本,并根據分布函數應用自舉生成新的隨機數據,如果在過采樣之后應用交叉驗證,那么我們所做的就是將我們的模型過擬合于一個特定的人工引導結果。這就是為什么在過度采樣數據之前應該始終進行交叉驗證,就像實現特征選擇一樣。只有重復采樣數據可以將隨機性引入到數據集中,以確保不會出現過擬合問題。
K-fold交叉驗證就是把原始數據隨機分成K個部分,在這K個部分中選擇一個作為測試數據,剩余的K-1個作為訓練數據。交叉驗證的過程實際上是將實驗重復做K次,每次實驗都從K個部分中選擇一個不同的部分作為測試數據,剩余的數據作為訓練數據進行實驗,最后把得到的K個實驗結果平均。
3.轉化為一分類問題

4.組合不同的重采樣數據集
5.用不同比例重新采樣
6.多模型Bagging


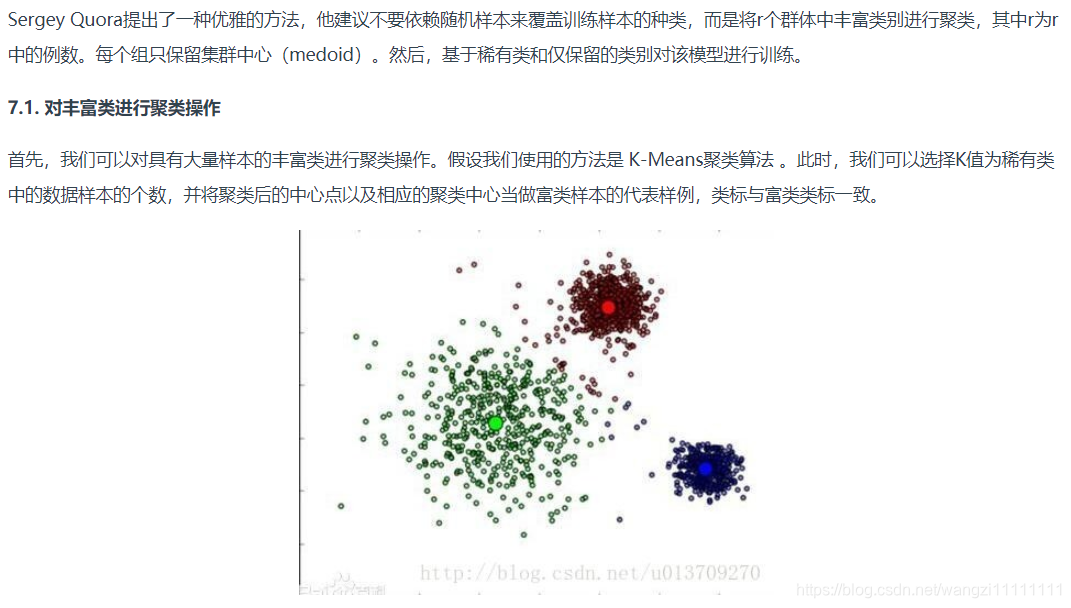
7.集群豐富類
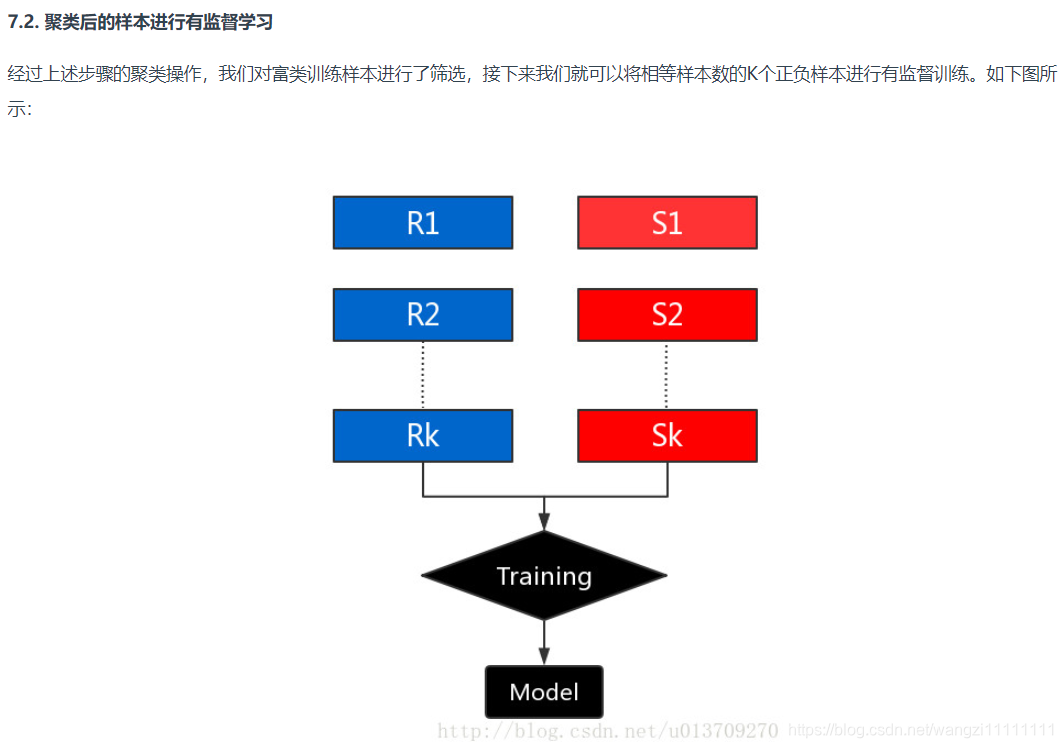
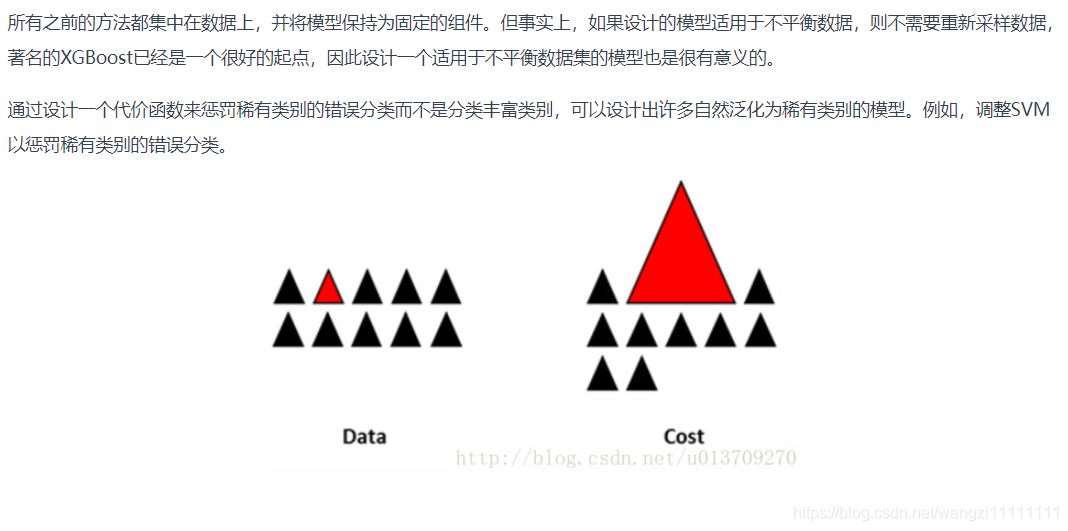
8.設計適用于不平衡數據集的模型
總結:


參考博客1
參考博客2




---avazu_ctr_predictor(baseline))



----Introduction and Linear Regression)

)

--c++,Python版本)
)
--c++,Python版本)

)

)
--c++,Python版本)