什么是會話?
??會話可簡單理解為:用戶開一個瀏覽器,點擊多個超鏈接,訪問服務器多個web資源,然后關閉瀏覽器,整個過程稱之為一個會話。
?會話過程中要解決的一些問題?
–每個用戶不可避免各自會產生一些數據,程序要想辦法為每個用戶保存這些數據。
–例如:用戶點擊超鏈接通過一個servlet購買了一個商品,程序應該想辦法保存用戶購買的商品,以便于用戶點結帳servlet時,結帳servlet可以得到用戶購買的商品為用戶結帳。
?Cookie
–Cookie是客戶端技術,程序把每個用戶的數據以cookie的形式寫給用戶各自的瀏覽器。當用戶使用瀏覽器再去訪問服務器中的web資源時,就會帶著各自的數據去。這樣,web資源處理的就是用戶各自的數據了。
?HttpSession
–Session是服務器端技術,利用這個技術,服務器在運行時可以為每一個用戶的瀏覽器創建一個其獨享的HttpSession對象,由于session為用戶瀏覽器獨享,所以用戶在訪問服務器的web資源時,可以把各自的數據放在各自的session中,當用戶再去訪問服務器中的其它web資源時,其它web資源再從用戶各自的session中取出數據為用戶服務。
總結:cookie存在客戶端,session存在服務器端
?通常結合使用。
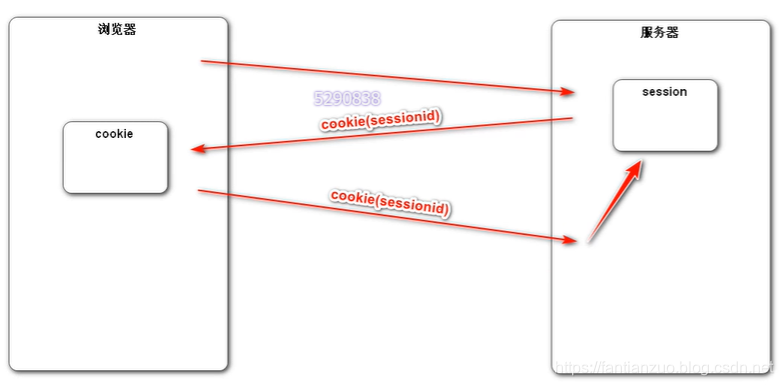
我們先用sprintboot演示一下cookie和session操作
@RequestMapping(path = "/cookie/set",method = RequestMethod.GET)@ResponseBodypublic String setCookie(HttpServletResponse httpServletResponse){Cookie cookie=new Cookie("code", CommunityUtil.generateUUID());cookie.setPath("/community/alpha");cookie.setMaxAge(60*10);httpServletResponse.addCookie(cookie);return "set cookie";}@RequestMapping(path = "/cookie/get",method = RequestMethod.GET)@ResponseBodypublic String getCookie(@CookieValue("code") String code){System.out.println(code);return "get cookie";}@RequestMapping(path = "/session/set", method = RequestMethod.GET)@ResponseBodypublic String setSession(HttpSession session){session.setAttribute("id",1);session.setAttribute("name","Test");return "set session";}@RequestMapping(path = "/session/get", method = RequestMethod.GET)@ResponseBodypublic String getSession(HttpSession session) {System.out.println(session.getAttribute("id"));System.out.println(session.getAttribute("name"));return "get session";}隨著服務器要處理的請求越來越多,我們不得不分布式部署,減小服務器壓力。
為了負載均衡,我們一般采用nginx來分發請求給各個服務器處理
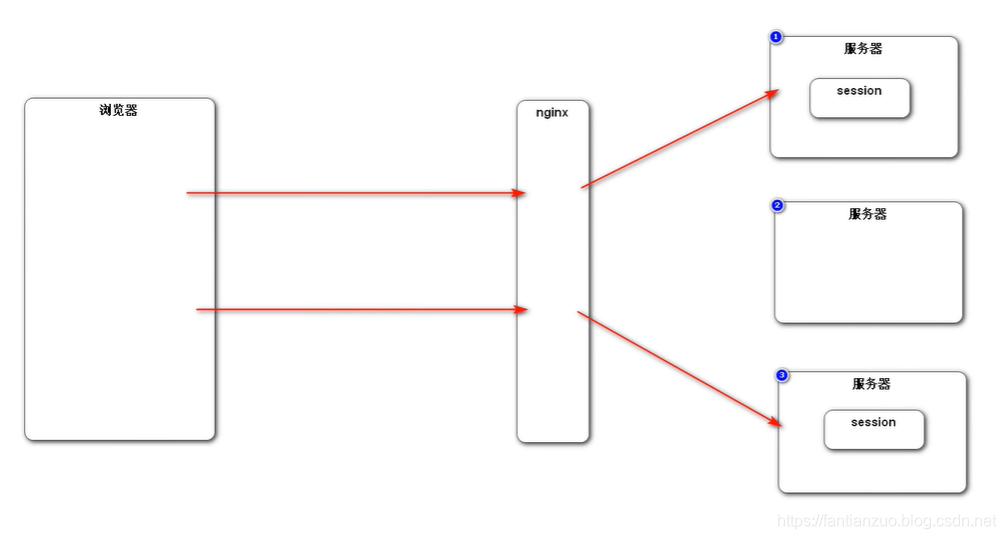
但是這樣session是無法共享的。
(粘性session)
你可以設置nginx的分配策略,下次同一個還讓同一個服務器來處理
但是很顯然,這就和分布式和nginx初衷違背了:負載很難保證均衡。
(同步session)
一臺服務器的session給所有服務器復制一份
第一,性能不好。第二,產生了一定的耦合
(專門session)
專門一臺服務器來解決,存session,其它服務器來這個服務器取session再用。
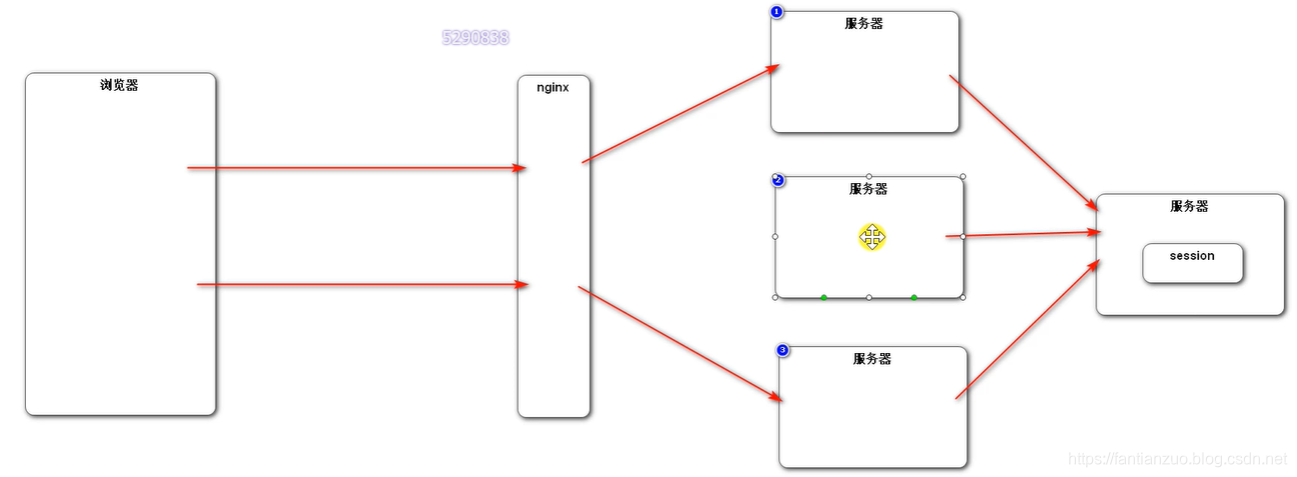
但是也有問題:你這個服務器掛了怎么辦?別的服務器都是依賴這個服務器工作的。我們分布式部署本來就是為了解決性能的瓶頸啊。
很容易想到,我們把那個處理session的服務器搞個集群:
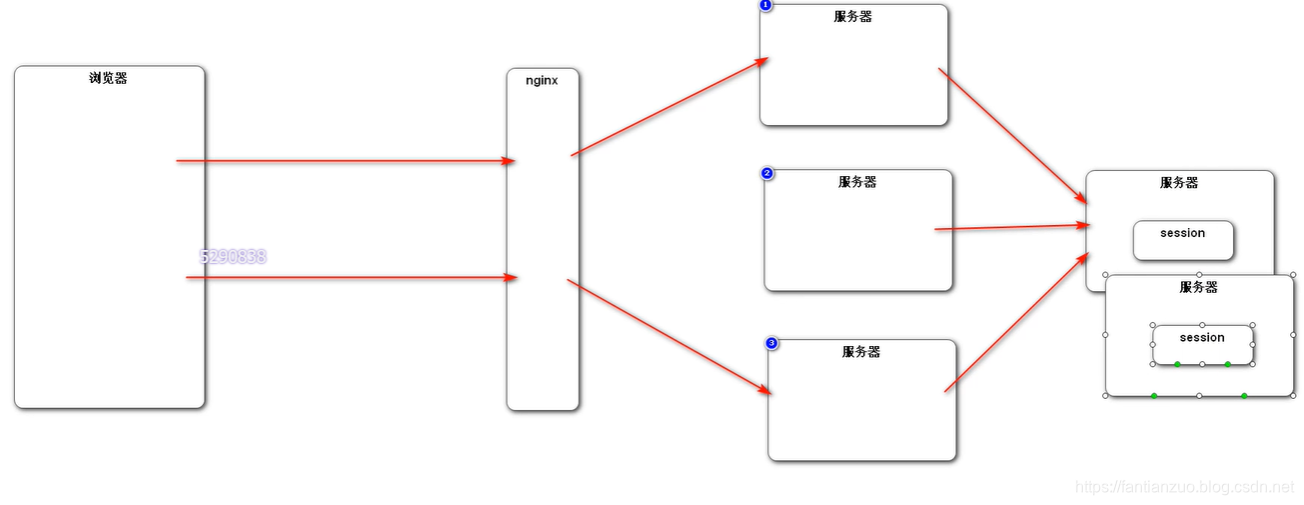
更不行,想想就知道,本來就是為了解決分布式部署的問題,你把單獨解決session的服務器又搞集群,和之前有什么區別呢?還不如一個服務器存一份簡單呢。
(存數據庫)
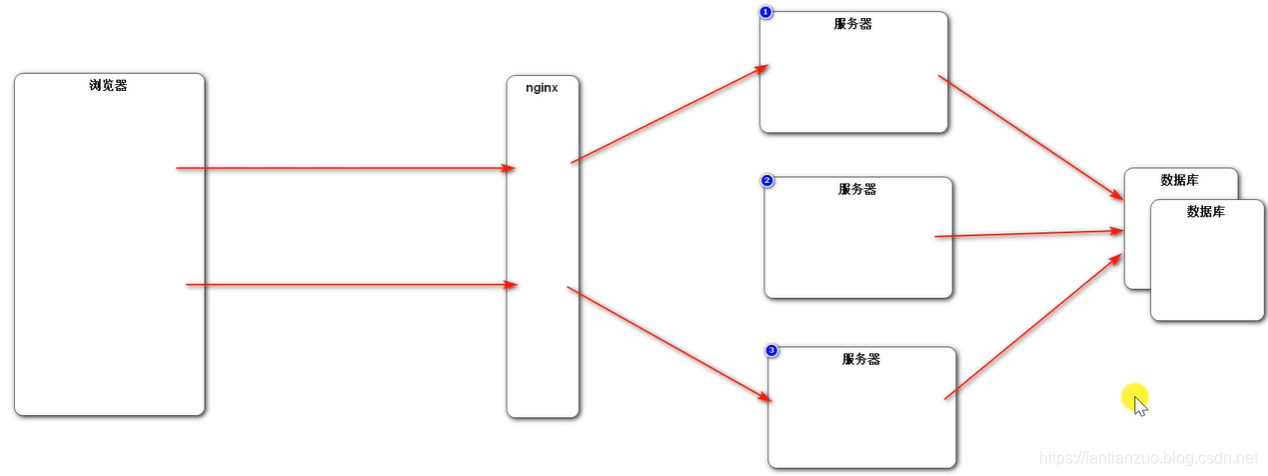
可以,但是傳統的關系數據庫是存到硬盤里,速度太慢。
(nosql)
最終,我們的主流辦法使用nosql數據庫,比如redis,來解決這個問題的。
-深度推薦模型-AutoRec、DeepCrossing、NeuralCF、PNN、WideDeep、FNN、DeepFM、NFM)
)

)
-)

-注意力機制+深度推薦模型、強化學習推薦系統)


)

 Variable(變量))
-)
 神經網絡)

)
-Git配置文件、底層操作命令)


