范式(避免數據冗余和操作異常)
函數依賴
A->B ?A和B是兩個屬性集,來自同一關系模式,對于同樣的A屬性值,B屬性值也相同
平凡的函數依賴
X->Y,如果Y是X的子集
非平凡的函數依賴
X->Y,如果Y不是X的子集
部分函數依賴
X->Y,如果存在W->Y,且W?X
傳遞函數依賴
在R(U)中,如果X→Y(非平凡函數依賴,完全函數依賴),Y→Z, 則稱Z對X傳遞函數依賴。
??? 記為:X![]() Z
Z
super key&candidate key&primary key&主屬性&非主屬性
super key:在關系中能唯一標識元素的屬性集
candidate key或key:不含有多余屬性的super key
primary key:在candidate key 中任選一個
candidate key中X決定所有屬性的函數依賴是完全函數依賴
包含在任何一個candidate key中的屬性 ,稱為主屬性
不包含在candidate key中的屬性稱為非主屬性
1NF 列不可分
列不可分
2NF 消除了非主屬性對鍵的部分函數依賴
在關系T上有函數依賴集F,F+是F的閉包。
F滿足2NF,當且僅當 每個非平凡的函數依賴X->A(F+),A是單個非主屬性,要求X不是任何key的真子集(有可能是super key,也有可能是非key)。
3NF 消除了非主屬性對鍵的傳遞函數依賴
F滿足3NF,當且僅當 每個非平凡的函數依賴X->A(F+),A是單個非主屬性,要求X是T的super key。
BCNF 消除了主屬性對鍵的部分函數依賴和傳遞函數依賴
F滿足BCNF,當且僅當 每個非平凡的函數依賴X->A(F+),A是單個屬性,要求X是T的super key。
對于F+中 的任意一個X->A,如果A是單個屬性,且A不在X中,那么X一定是T的super key。
?
反范式(減少連接,提高查詢效率)
沒有冗余的數據庫未必是最好的數據庫,有時為了提高運行效率,就必須降低范式標準,適當保留冗余數據。具體做法是: 在概念數據模型設計時遵守第三范式,降低范式標準的工作放到物理數據模型設計時考慮。降低范式就是增加字段,減少了查詢時的關聯,提高查詢效率,因為在數據庫的操作中查詢的比例要遠遠大于DML的比例。但是反范式化一定要適度,并且在原本已滿足三范式的基礎上再做調整的。
Pattern1:合并1對1關系
| car_id | car_name |
| 1 | c1 |
| 2 | c2 |
| 3 | c3 |
teacher
| teacher_id | teacher_name |
| 1 | t1 |
| 2 | t2 |
| 3 | t3 |
| 4 | t4 |
合并后
car_and_teacher
| car_id | car_name | teacher_id | teacher_name |
| 1 | c1 | 1 | t1 |
| 2 | c2 | 2 | t2 |
| 3 | c3 | 3 | t3 |
| NULL | NULL | 4 | t4 |
問題:會產生大量空值,若兩邊都部分參與則不能合并;
部分參與為大部分參與時比較適合Pattern1
Pattern2:1對N關系中復制非鍵屬性以減少連接
兩表連接時復制非鍵屬性以減少連接
例:查詢學生以及所在學院名,可以在學生表中不僅存儲學院id,并且存儲學院名
faculty
| fid | fname |
| 1 | f1 |
student
| sid | sname | fid | fname |
| 1 | s1 | 1 | f1 |
維護時:
1)如果在UI中,只允許用戶進行選擇,不能自行輸入,保證輸入一致性
2)如果是程序員,對于類似學院名這種一般不變的代碼表,在修改時直接對兩張表都進行修改;如果經常變化,則可以加一個觸發器。
Pattern3:1對N關系中復制外鍵以減少連接
把另一張表的主鍵復制變成外鍵

應用后:
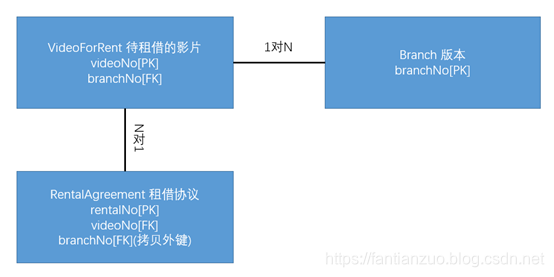
Pattern4:N對N關系中復制屬性,把兩張表中經常需要的內容復制到中間關系表中以減少連接

Pattern5:引入重復值
通常對于一個多值屬性,值不太多,且不會經常變,可以在表中建立多個有關此屬性的列
address1 | address2 | address3 | address4
Pattern6:建立提取表
為了解決查詢和更新之間不可調和的矛盾,可以將更新和查詢放在兩張表中,從工作表中提取查詢表,專門用于查詢。只適用于查詢實時性不高的情況。
Pattern7:分表
水平拆分
垂直拆分
 Variable(變量))
-)
 神經網絡)

)
-Git配置文件、底層操作命令)




-Git commit)




-分支)
)

-diff)
:柱面投影+模板匹配+漸入漸出融合)