在深度學習領域中,已經經過驗證的成熟算法,目前主要有深度卷積網絡(DNN)和遞歸網絡(RNN),在圖像識別,視頻識別,語音識別領域取得了巨大的成功,正是由于這些成功,能促成了當前深度學習的大熱。與此相對應的,在深度學習研究領域,最熱門的是AutoEncoder、RBM、DBN等產生式網絡架構,但是這些研究領域,雖然論文比較多,但是重量級應用還沒有出現,是否能取得成功還具有不確定性。但是有一些比較初步的跡象表明,這些研究領域還是非常值得期待的。比如AutoEncoder在圖像、視頻搜索領域的應用,RBM對非結構化數據的處理方面,DBN網絡在結合人工智能領域兩大流派連接主義和符號主義,都具有巨大的前景,有理由期待產生重量級成果。我們在后續會對這些網絡逐一進行介紹和實現,除了給出重構后的Theano實現代碼外,還會逐步補充這些算法在實際應用的中的實例,我們會主要將這些算法應用在創業公司數據中,從幾萬家創業公司及投融資數據中,希望能挖掘出哪些公司更可能獲得投資,特定公司更有可能獲得哪家投資機構的投資。
卷積神經網絡(CNN),這是深度學習算法應用最成功的領域之一,卷積神經網絡包括一維卷積神經網絡,二維卷積神經網絡以及三維卷積神經網絡。一維卷積神經網絡主要用于序列類的數據處理,二維卷積神經網絡常應用于圖像類文本的識別,三維卷積神經網絡主要應用于醫學圖像以及視頻類數據識別。
下面我的學習分為四部分,首先利用一個形象的例子說明電腦是如何識別圖像的,然后在說明什么是神經網絡,什么是卷積神經網絡,最后介紹常見的幾種卷積神經網絡。大體的結構就是這樣的。
一:如何幫助神經網絡識別圖像?
人類大腦是一非常強大的機器,每秒內能看(捕捉)多張圖,并在意識不到的情況下就完成了對這些圖的處理。但機器并非如此。機器處理圖像的第一步是理解,理解如何表達一張圖像,進而讀取圖片。
? 簡單來說,每個圖像都是一系列特定排序的圖點(像素)。如果你改變像素的順序或顏色,圖像也隨之改變。舉個例子,存儲并讀取一張上面寫著數字?4?的圖像。
? 基本上,機器會把圖像打碎成像素矩陣,存儲每個表示位置像素的顏色碼。在下圖的表示中,數值?1?是白色,256?是最深的綠色(為了簡化,我們示例限制到了一種顏色)。
一旦你以這種格式存儲完圖片信息,下一步就是讓神經網絡理解這種排序與模式。(表征像素的數值是以特定的方式排序的)
那么如何幫助神經網絡識別圖像?
假設我們嘗試使用全連接網絡識別圖像,應該如何做?
全連接網絡可以通過平化它,把圖像當作一個數組,并把像素值當作預測圖像中數值的特征。明確地說,讓網絡理解理解下面圖中發生了什么,非常的艱難。

即使人類也很難理解上圖中表達的含義是數字?4。我們完全丟失了像素的空間排列。
我們能做什么呢?可以嘗試從原圖中提取特征,從而保留空間排序。
案例一
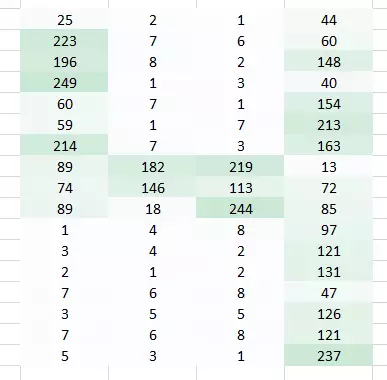
這里我們使用一個權重乘以初始像素值
現在裸眼識別出這是「4」就變得更簡單了。但把它交給全連接網絡之前,還需要平整化(flatten)?它,要讓我們能夠保留圖像的空間排列。

案例二
現在我們可以看到,把圖像平整化完全破壞了它的排列。我們需要想出一種方式在沒有平整化的情況下把圖片饋送給網絡,并且還要保留空間排列特征,也就是需要饋送像素值的?2D/3D?排列。
??????? 我們可以嘗試一次采用圖像的兩個像素值,而非一個。這能給網絡很好的洞見,觀察鄰近像素的特征。既然一次采用兩個像素,那也就需要一次采用兩個權重值了。
希望你能注意到圖像從之前的?4?列數值變成了?3?列。因為我們現在一次移用兩個像素(在每次移動中像素被共享),圖像變的更小了。雖然圖像變小了,我們仍能在很大程度上理解這是「4」。而且,要意識到的一個重點是,我們采用的是兩個連貫的水平像素,因此只會考慮水平的排列。
這是我們從圖像中提取特征的一種方式。我們可以看到左邊和中間部分,但右邊部分看起來不那么清楚。主要是因為兩個問題:
1.?圖片角落左邊和右邊是權重相乘一次得到的。
2.?左邊仍舊保留,因為權重值高;右邊因為略低的權重,有些丟失。
?
現在我們有兩個問題,需要兩個解決方案。
案例三
遇到這樣的問題是圖像左右兩角只被權重通過一次,我們需要做的是讓網絡像考慮其他像素一樣考慮角落。我們有一個簡單的方法解決這一問題:把零放在權重運動的兩邊。

你可以看到通過添加零,來自角落的信息被再訓練。圖像也變得更大。這可被用于我們不想要縮小圖像的情況下。
案例四
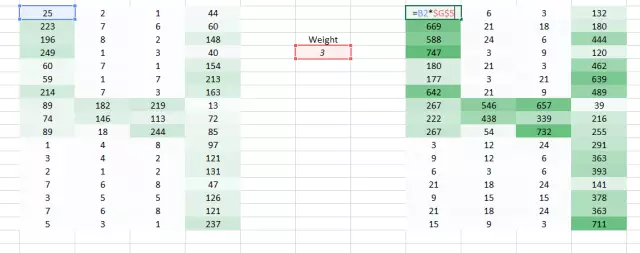
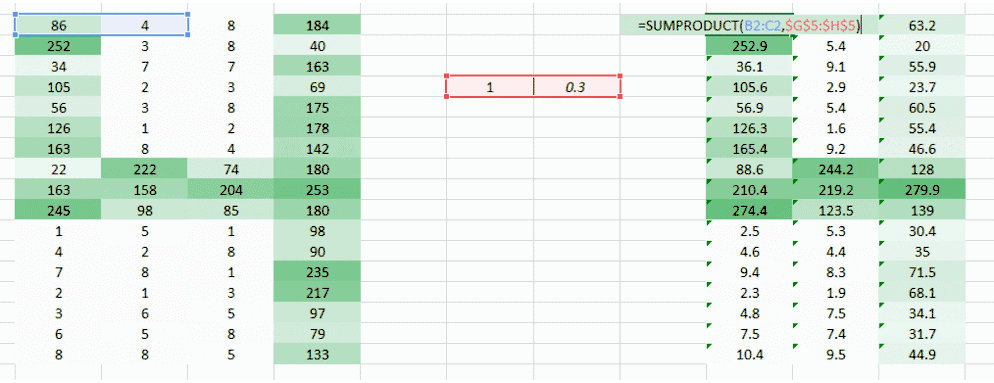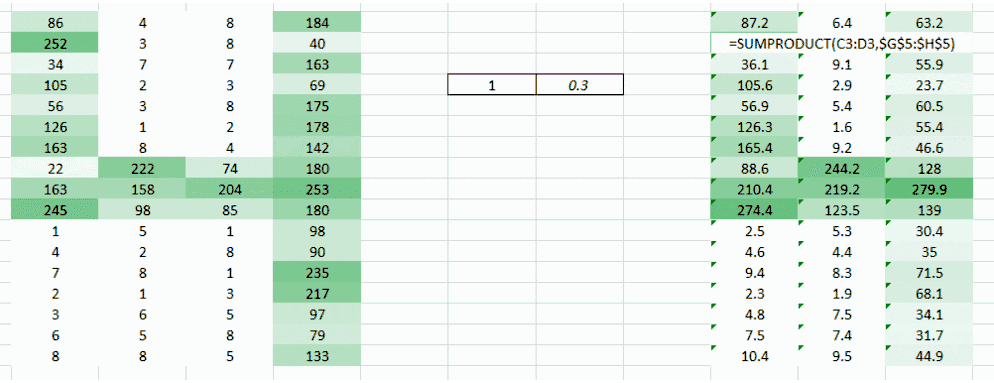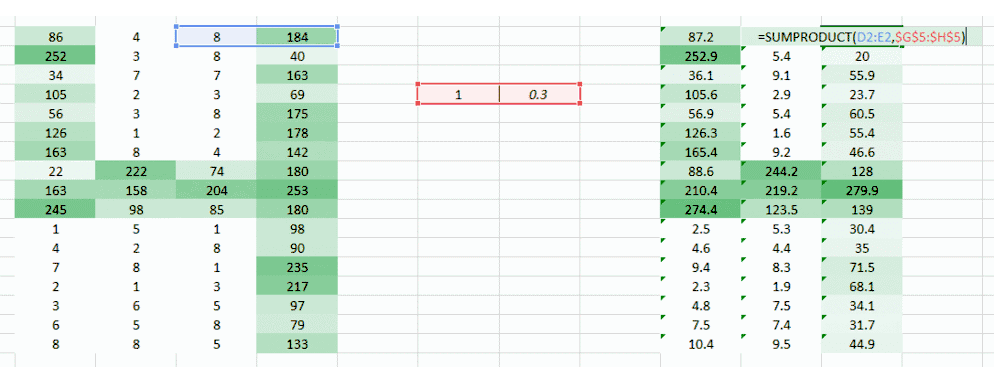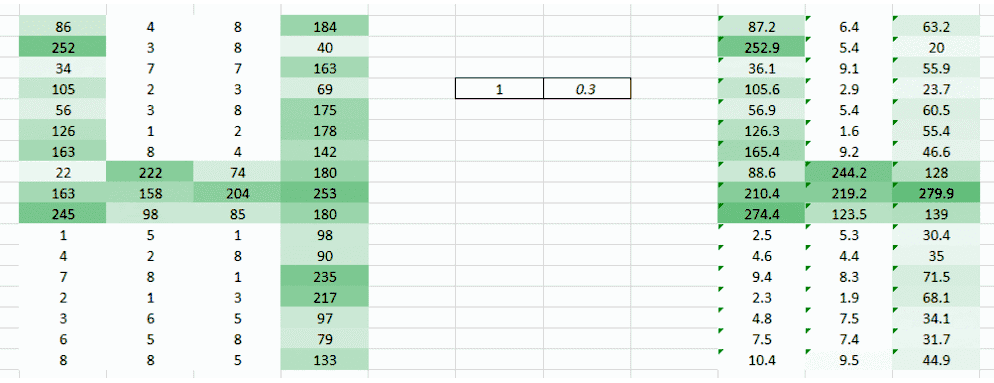
這里我們試圖解決的問題是右側角落更小的權重值正在降低像素值,因此使其難以被我們識別。我們所能做的是采取多個權重值并將其結合起來。
(1,0.3)?的權重值給了我們一個輸出表格
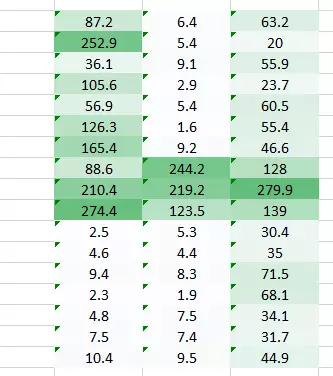
同時表格?(0.1,5)?的權重值也將給我們一個輸出表格。
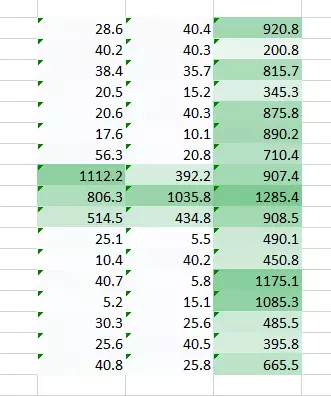
兩張圖像的結合版本將會給我們一個清晰的圖片。因此,我們所做的是簡單地使用多個權重而不是一個,從而再訓練圖像的更多信息。最終結果將是上述兩張圖像的一個結合版本。
案例五
我們到現在通過使用權重,試圖把水平像素(horizontal?pixel)結合起來。但是大多數情況下我們需要在水平和垂直方向上保持空間布局。我們采取?2D?矩陣權重,把像素在水平和垂直方向上結合起來。同樣,記住已經有了水平和垂直方向的權重運動,輸出會在水平和垂直方向上低一個像素。

所以我們做了什么?
上面我們所做的事是試圖通過使用圖像的空間的安排從圖像中提取特征。為了理解圖像,理解像素如何安排對于一個網絡極其重要。上面我們所做的也恰恰是一個卷積網絡所做的。我們可以采用輸入圖像,定義權重矩陣,并且輸入被卷積以從圖像中提取特殊特征而無需損失其有關空間安排的信息。
? 這個方法的另一個重大好處是它可以減少圖像的參數數量。正如所見,卷積圖像相比于原始圖像有更少的像素。
2 :什么是神經網絡?
這里的神經網絡,也指人工神經網絡(Artificial Neural Networks,簡稱ANNs),是一種模仿生物神經網絡行為特征的算法數學模型,由神經元、節點與節點之間的連接(突觸)所構成,如下圖:
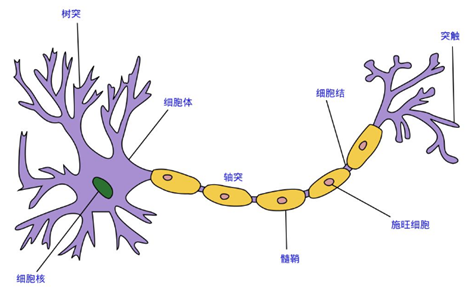
每個神經網絡單元抽象出來的數學模型如下,也叫感知器,它接收多個輸入(x1,x2,x3...),產生一個輸出,這就好比是神經末梢感受各種外部環境的變化(外部刺激),然后產生電信號,以便于轉導到神經細胞(又叫神經元)。

單個的感知器就構成了一個簡單的模型,但在現實世界中,實際的決策模型則要復雜得多,往往是由多個感知器組成的多層網絡,如下圖所示,這也是經典的神經網絡模型,由輸入層、隱含層、輸出層構成。

人工神經網絡可以映射任意復雜的非線性關系,具有很強的魯棒性、記憶能力、自學習等能力,在分類、預測、模式識別等方面有著廣泛的應用。
3 :什么是卷積神經網絡?
卷積神經網絡是近年發展起來的,并引起廣泛重視的一種高效識別方法,20世紀60年代,Hubel和Wiesel在研究貓腦皮層中用于局部敏感和方向選擇的神經元時發現其獨特的網絡結構可以有效地降低反饋神經網絡的復雜性,繼而提出了卷積神經網絡(Convolutional Neural Networks-簡稱CNN)。現在,CNN已經成為眾多科學領域的研究熱點之一,特別是在模式分類領域,由于該網絡避免了對圖像的復雜前期預處理,可以直接輸入原始圖像,因而得到了更為廣泛的應用。 K.Fukushima在1980年提出的新識別機是卷積神經網絡的第一個實現網絡。隨后,更多的科研工作者對該網絡進行了改進。其中,具有代表性的研究成果是Alexander和Taylor提出的“改進認知機”,該方法綜合了各種改進方法的優點并避免了耗時的誤差反向傳播。
這聽起來像是一個奇怪的生物學和數學的結合,但是這些網絡已經成為計算機視覺領域最具影響力的創新之一。2012年是神經網絡成長的第一年,Alex Krizhevsky用它們贏得了當年的ImageNet競賽(基本上是計算機視覺年度奧運會),把分類錯誤記錄從26%降到了15%,這個驚人的提高從那以后,許多公司一直在以服務為核心進行深度學習。Facebook使用自動標記算法的神經網絡,谷歌的照片搜索,亞馬遜的產品推薦,Pinterest的家庭飼料個性化和Instagram的搜索基礎設施。
一般的,CNN的基本結構包括兩層,其一為特征提取層,每個神經元的輸入與前一層的局部接受域相連,并提取該局部的特征。一旦該局部特征被提取后,它與其它特征間的位置關系也隨之確定下來;其二是特征映射層,網絡的每個計算層由多個特征映射組成,每個特征映射是一個平面,平面上所有神經元的權值相等。特征映射結構采用影響函數核小的sigmoid函數作為卷積網絡的激活函數,使得特征映射具有位移不變性。此外,由于一個映射面上的神經元共享權值,因而減少了網絡自由參數的個數。卷積神經網絡中的每一個卷積層都緊跟著一個用來求局部平均與二次提取的計算層,這種特有的兩次特征提取結構減小了特征分辨率。
? CNN主要用來識別位移、縮放及其他形式扭曲不變性的二維圖形,該部分功能主要由池化層實現。由于CNN的特征檢測層通過訓練數據進行學習,所以在使用CNN時,避免了顯式的特征抽取,而隱式地從訓練數據中進行學習;再者由于同一特征映射面上的神經元權值相同,所以網絡可以并行學習,這也是卷積網絡相對于神經元彼此相連網絡的一大優勢。卷積神經網絡以其局部權值共享的特殊結構在語音識別和圖像處理方面有著獨特的優越性,其布局更接近于實際的生物神經網絡,權值共享降低了網絡的復雜性,特別是多維輸入向量的圖像可以直接輸入網絡這一特點避免了特征提取和分類過程中數據重建的復雜度。
? 說了這么多,接下來將以圖像識別為例子,來介紹卷積神經網絡的原理。
3.1 案例
假設給定一張圖(可能是字母X或者字母O),通過CNN即可識別出是X還是O,如下圖所示,那怎么做到的呢
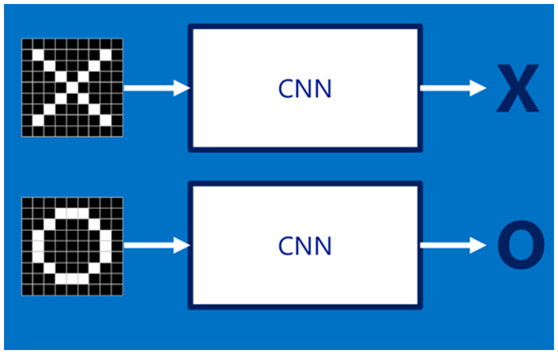
3.2 圖像輸入
如果采用經典的神經網絡模型,則需要讀取整幅圖像作為神經網絡模型的輸入(即全連接的方式),當圖像的尺寸越大時,其連接的參數將變得很多,從而導致計算量非常大。
而我們人類對外界的認知一般是從局部到全局,先對局部有感知的認識,再逐步對全體有認知,這是人類的認識模式。在圖像中的空間聯系也是類似,局部范圍內的像素之間聯系較為緊密,而距離較遠的像素則相關性較弱。因而,每個神經元其實沒有必要對全局圖像進行感知,只需要對局部進行感知,然后在更高層將局部的信息綜合起來就得到了全局的信息。這種模式就是卷積神經網絡中降低參數數目的重要神器:局部感受野。
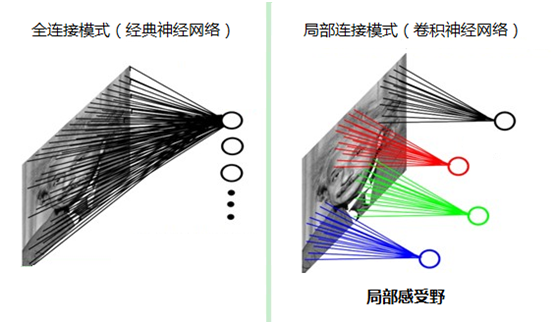
3.3 提取特征
如果字母X、字母O是固定不變的,那么最簡單的方式就是圖像之間的像素一一比對就行,但在現實生活中,字體都有著各個形態上的變化(例如手寫文字識別),例如平移、縮放、旋轉、微變形等等,如下圖所示:
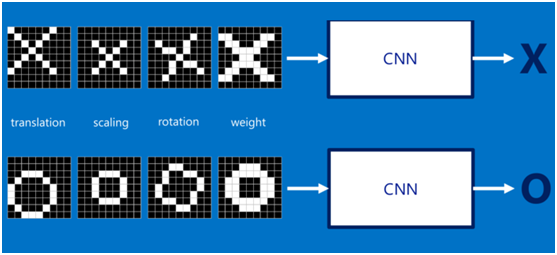
我們的目標是對于各種形態變化的X和O,都能通過CNN準確地識別出來,這就涉及到應該如何有效地提取特征,作為識別的關鍵因子。
回想前面講到的“局部感受野”模式,對于CNN來說,它是一小塊一小塊地來進行比對,在兩幅圖像中大致相同的位置找到一些粗糙的特征(小塊圖像)進行匹配,相比起傳統的整幅圖逐一比對的方式,CNN的這種小塊匹配方式能夠更好的比較兩幅圖像之間的相似性。如下圖:
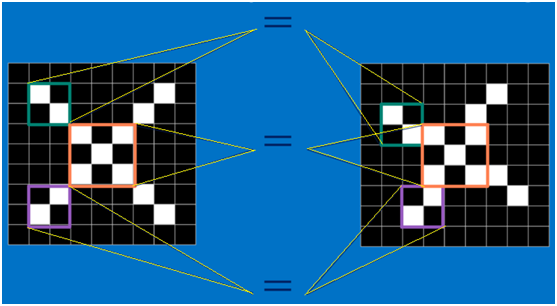
以字母X為例,可以提取出三個重要特征(兩個交叉線、一個對角線),如下圖所示:
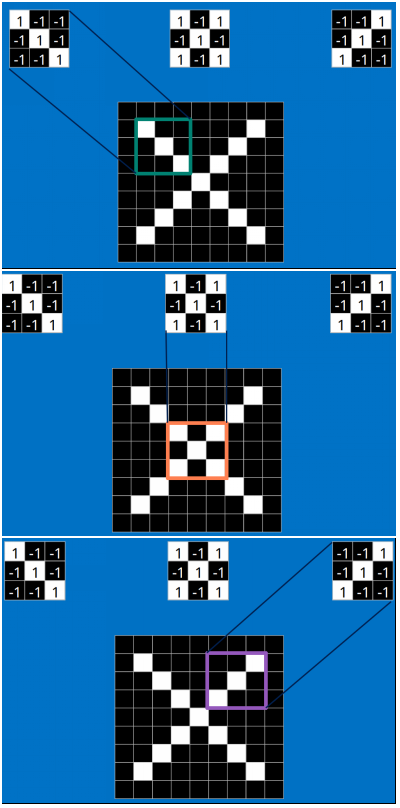
假如以像素值"1"代表白色,像素值"-1"代表黑色,則字母X的三個重要特征如下:

那么這些特征又是怎么進行匹配計算呢?
3.4 卷積(convolution)
這時就要請出今天的重要嘉賓:卷積。那什么是卷積呢,不急,下面慢慢道來。
當給定一張新圖時,CNN并不能準確地知道這些特征到底要匹配原圖的哪些部分,所以它會在原圖中把每一個可能的位置都進行嘗試,相當于把這個feature(特征)變成了一個過濾器。這個用來匹配的過程就被稱為卷積操作,這也是卷積神經網絡名字的由來。
卷積的操作如下圖所示:
是不是很像把毛巾沿著對角卷起來,下圖形象地說明了為什么叫「卷」積

?
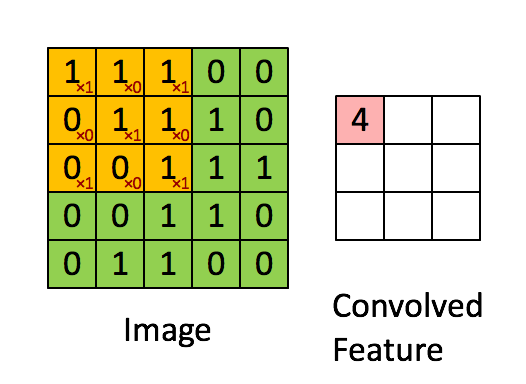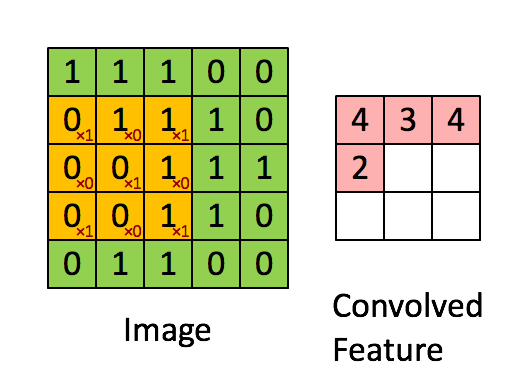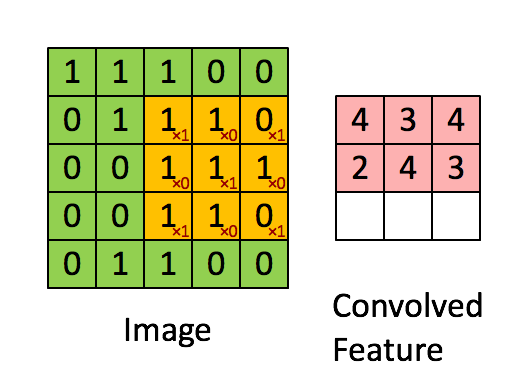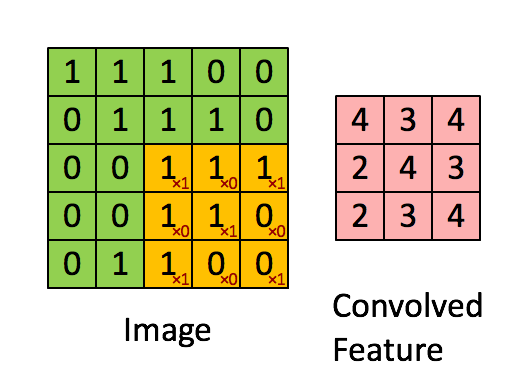
在本案例中,要計算一個feature(特征)和其在原圖上對應的某一小塊的結果,只需將兩個小塊內對應位置的像素值進行乘法運算,然后將整個小塊內乘法運算的結果累加起來,最后再除以小塊內像素點總個數即可(注:也可不除以總個數的)。
如果兩個像素點都是白色(值均為1),那么1*1 = 1,如果均為黑色,那么(-1)*(-1) = 1,也就是說,每一對能夠匹配上的像素,其相乘結果為1。類似地,任何不匹配的像素相乘結果為-1。具體過程如下(第一個、第二個……、最后一個像素的匹配結果):
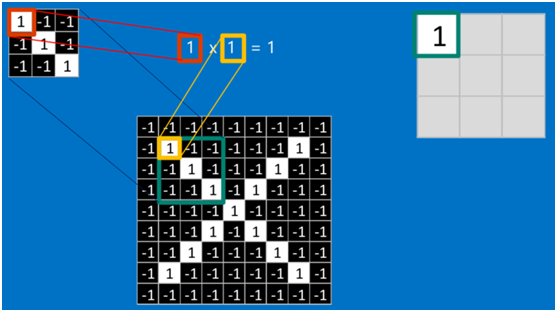
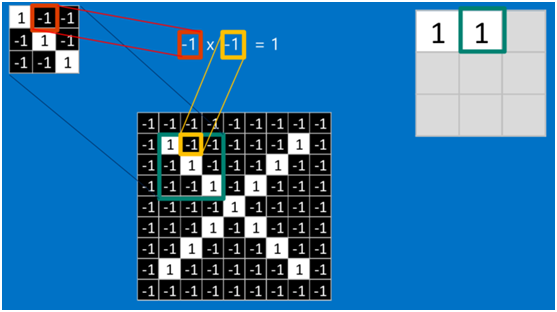

根據卷積的計算方式,第一塊特征匹配后的卷積計算如下,結果為1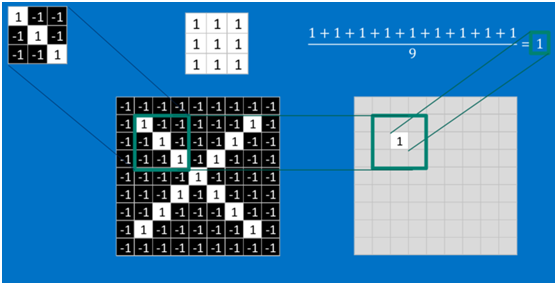 ?
?
對于其它位置的匹配,也是類似(例如中間部分的匹配)
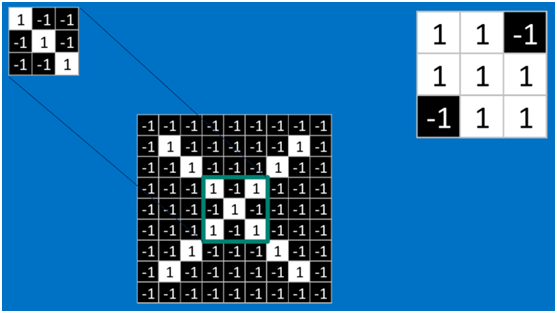
計算之后的卷積如下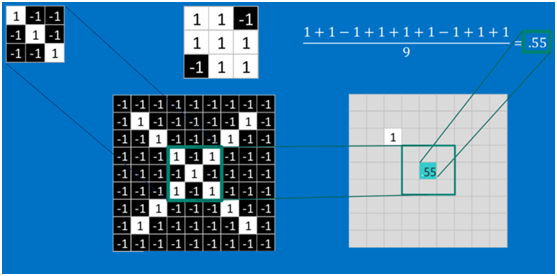 ?
?
以此類推,對三個特征圖像不斷地重復著上述過程,通過每一個feature(特征)的卷積操作,會得到一個新的二維數組,稱之為feature map。其中的值,越接近1表示對應位置和feature的匹配越完整,越是接近-1,表示對應位置和feature的反面匹配越完整,而值接近0的表示對應位置沒有任何匹配或者說沒有什么關聯。如下圖所示: ?
?
可以看出,當圖像尺寸增大時,其內部的加法、乘法和除法操作的次數會增加得很快,每一個filter的大小和filter的數目呈線性增長。由于有這么多因素的影響,很容易使得計算量變得相當龐大。
3.5 池化(Pooling)
為了有效地減少計算量,CNN使用的另一個有效的工具被稱為“池化(Pooling)”。池化就是將輸入圖像進行縮小,減少像素信息,只保留重要信息。
池化的操作也很簡單,通常情況下,池化區域是2*2大小,然后按一定規則轉換成相應的值,例如取這個池化區域內的最大值(max-pooling)、平均值(mean-pooling)等,以這個值作為結果的像素值。
下圖顯示了左上角2*2池化區域的max-pooling結果,取該區域的最大值max(0.77,-0.11,-0.11,1.00),作為池化后的結果,如下圖: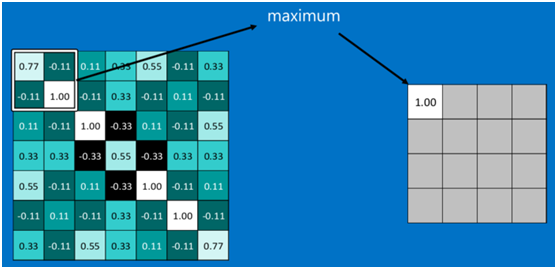 ?
?
池化區域往左,第二小塊取大值max(0.11,0.33,-0.11,0.33),作為池化后的結果,如下圖: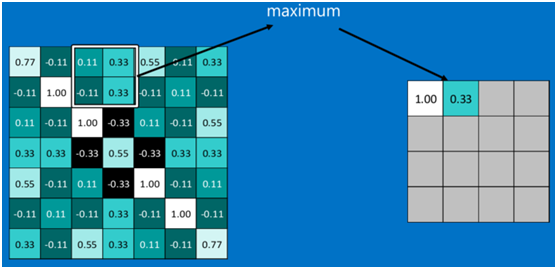 ?
?
其它區域也是類似,取區域內的最大值作為池化后的結果,最后經過池化后,結果如下: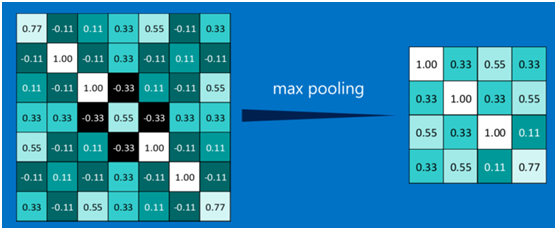 ?
?
對所有的feature map執行同樣的操作,結果如下: ?
?
最大池化(max-pooling)保留了每一小塊內的最大值,也就是相當于保留了這一塊最佳的匹配結果(因為值越接近1表示匹配越好)。也就是說,它不會具體關注窗口內到底是哪一個地方匹配了,而只關注是不是有某個地方匹配上了。
通過加入池化層,圖像縮小了,能很大程度上減少計算量,降低機器負載。
3.6 激活函數RelU?(Rectified Linear Units)
常用的激活函數有sigmoid、tanh、relu等等,前兩者sigmoid/tanh比較常見于全連接層,后者ReLU常見于卷積層。
回顧一下前面講的感知機,感知機在接收到各個輸入,然后進行求和,再經過激活函數后輸出。激活函數的作用是用來加入非線性因素,把卷積層輸出結果做非線性映射。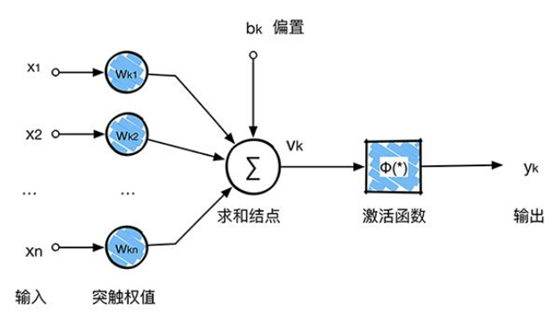 ?
?
在卷積神經網絡中,激活函數一般使用ReLU(The Rectified Linear Unit,修正線性單元),它的特點是收斂快,求梯度簡單。計算公式也很簡單,max(0,T),即對于輸入的負值,輸出全為0,對于正值,則原樣輸出。
下面看一下本案例的ReLU激活函數操作過程:
第一個值,取max(0,0.77),結果為0.77,如下圖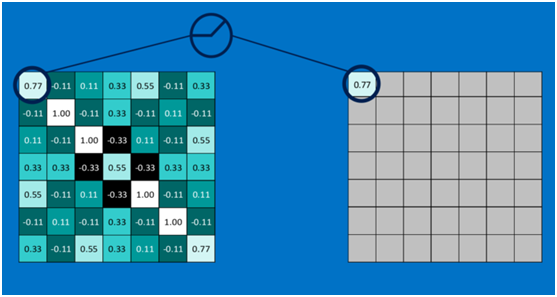 ?
?
第二個值,取max(0,-0.11),結果為0,如下圖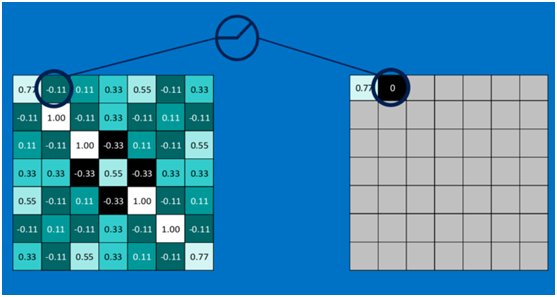 ?
?
以此類推,經過ReLU激活函數后,結果如下: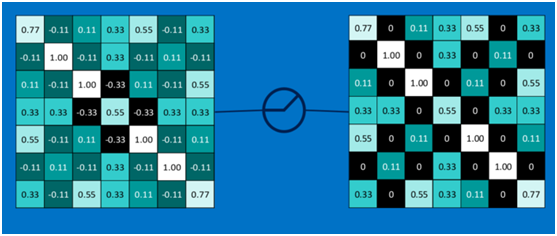 ?
?
對所有的feature map執行ReLU激活函數操作,結果如下:
?
3.7 深度神經網絡
通過將上面所提到的卷積、激活函數、池化組合在一起,就變成下圖: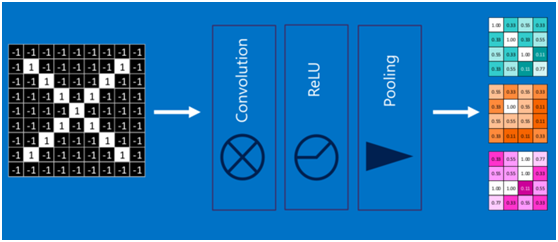 ?
?
通過加大網絡的深度,增加更多的層,就得到了深度神經網絡,如下圖: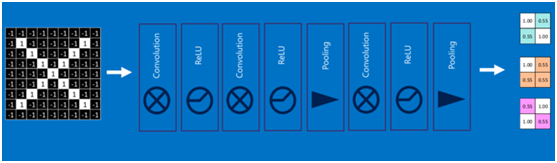
3.8 全連接層(Fully connected layers)
全連接層在整個卷積神經網絡中起到“分類器”的作用,即通過卷積、激活函數、池化等深度網絡后,再經過全連接層對結果進行識別分類。
首先將經過卷積、激活函數、池化的深度網絡后的結果串起來,如下圖所示: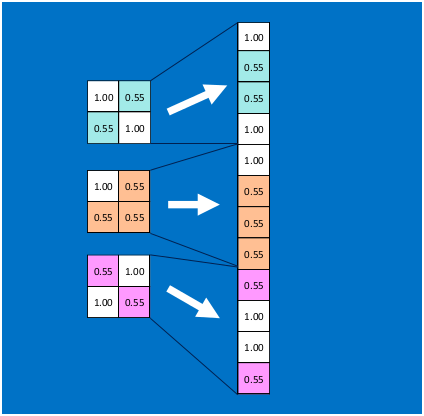 ?
?
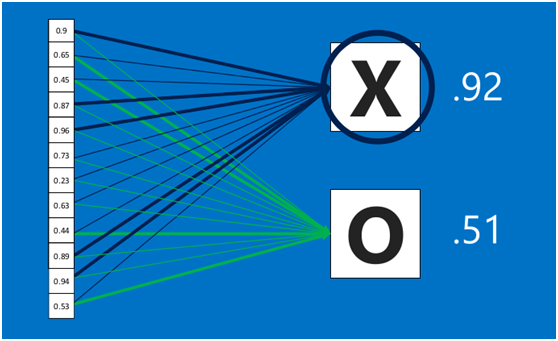
由于神經網絡是屬于監督學習,在模型訓練時,根據訓練樣本對模型進行訓練,從而得到全連接層的權重(如預測字母X的所有連接的權重)
?
在利用該模型進行結果識別時,根據剛才提到的模型訓練得出來的權重,以及經過前面的卷積、激活函數、池化等深度網絡計算出來的結果,進行加權求和,得到各個結果的預測值,然后取值最大的作為識別的結果(如下圖,最后計算出來字母X的識別值為0.92,字母O的識別值為0.51,則結果判定為X)
?
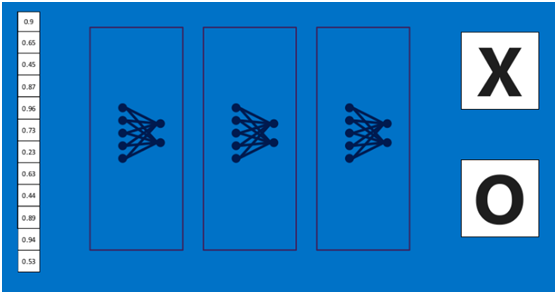
上述這個過程定義的操作為”全連接層“(Fully connected layers),全連接層也可以有多個,如下圖:
?
?
3.9 卷積神經網絡(Convolutional Neural Networks)
將以上所有結果串起來后,就形成了一個“卷積神經網絡”(CNN)結構,如下圖所示:
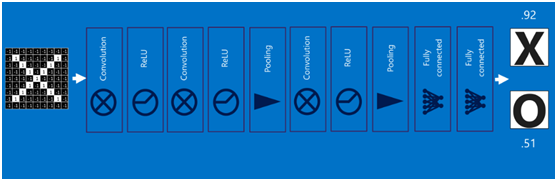
最后,再回顧總結一下,卷積神經網絡主要由兩部分組成,一部分是特征提取(卷積、激活函數、池化),另一部分是分類識別(全連接層),下圖便是著名的手寫文字識別卷積神經網絡結構圖: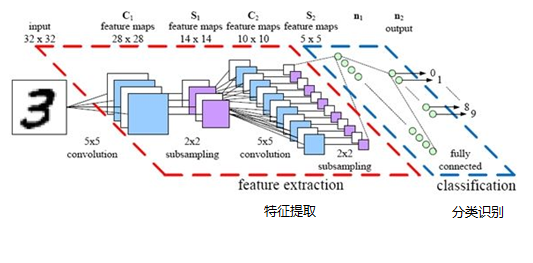
3.10 對卷積神經網絡的總結
卷積網絡在本質上是一種輸入到輸出的映射,它能夠學習大量的輸入與輸出之間的映射關系,而不需要任何輸入和輸出之間的精確的數學表達式,只要用已知的模式對卷積網絡加以訓練,網絡就具有輸入輸出對之間的映射能力。
CNN一個非常重要的特點就是頭重腳輕(越往輸入權值越小,越往輸出權值越多),呈現出一個倒三角的形態,這就很好地避免了BP神經網絡中反向傳播的時候梯度損失得太快。
卷積神經網絡CNN主要用來識別位移、縮放及其他形式扭曲不變性的二維圖形。由于CNN的特征檢測層通過訓練數據進行學習,所以在使用CNN時,避免了顯式的特征抽取,而隱式地從訓練數據中進行學習;再者由于同一特征映射面上的神經元權值相同,所以網絡可以并行學習,這也是卷積網絡相對于神經元彼此相連網絡的一大優勢。卷積神經網絡以其局部權值共享的特殊結構在語音識別和圖像處理方面有著獨特的優越性,其布局更接近于實際的生物神經網絡,權值共享降低了網絡的復雜性,特別是多維輸入向量的圖像可以直接輸入網絡這一特點避免了特征提取和分類過程中數據重建的復雜度。
四:常見的幾種卷積神經網絡介紹
目前圖像分類中的ResNet, 目標檢測領域占統治地位的Faster R-CNN,分割中最牛的Mask-RCNN, UNet和經典的FCN都是以下面幾種常見網絡為基礎。
?一:LeNet
1.1? 網絡背景
LeNet誕生于1994年,由深度學習三巨頭之一的Yan LeCun提出,他也被稱為卷積神經網絡之父。LeNet主要用來進行手寫字符的識別與分類,準確率達到了98%,并在美國的銀行中投入了使用,被用于讀取北美約10%的支票。LeNet奠定了現代卷積神經網絡的基礎。
1.2? 網絡結構
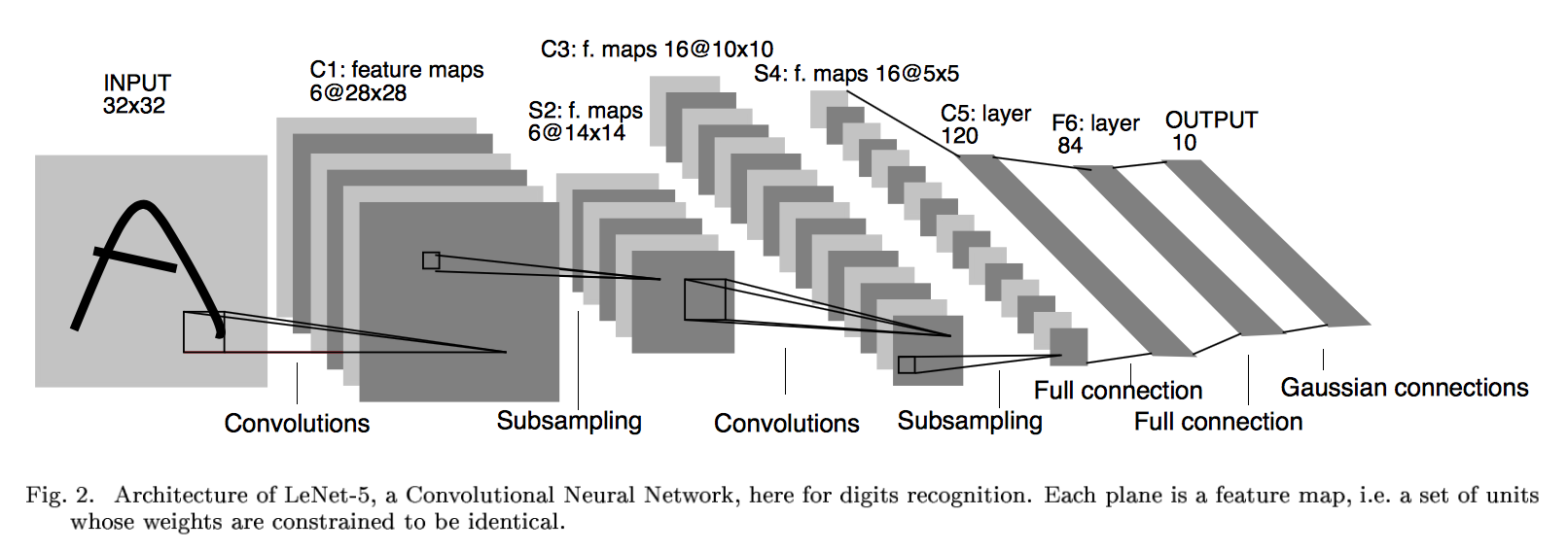
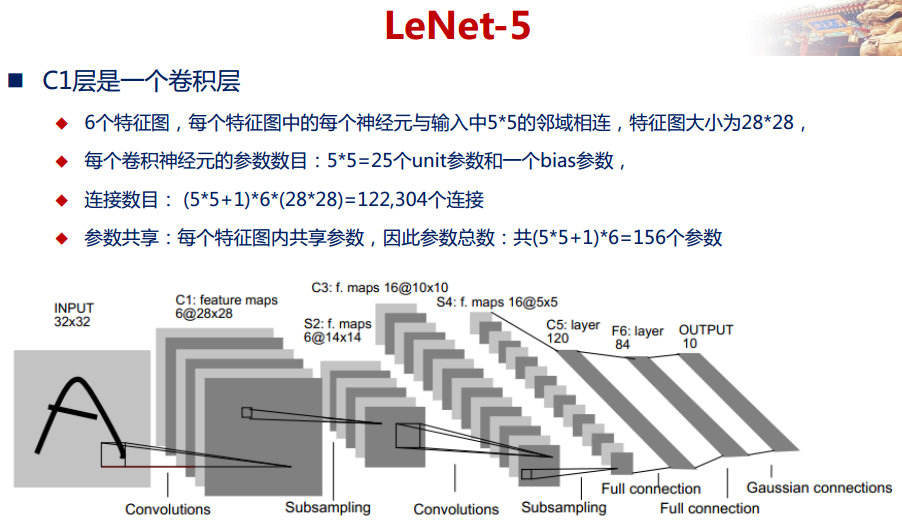
上圖為LeNet結構圖,是一個6層網絡結構:三個卷積層,兩個下采樣層和一個全連接層(圖中C代表卷積層,S代表下采樣層,F代表全連接層)。其中,C5層也可以看成是一個全連接層,因為C5層的卷積核大小和輸入圖像的大小一致,都是5*5(可參考LeNet詳細介紹)。
1.3 網絡特點
- 每個卷積層包括三部分:卷積、池化和非線性激活函數(sigmoid激活函數)
- 使用卷積提取空間特征
- 降采樣層采用平均池化



)

)
)







)
)

)
)
拼接)