一個阿里p7學長給的nosql面試知識庫,絕對真實,學會了去面呀。??
最近整理了一下超硬核系列的文章和面經系列的文章,可以持續關注下:
超硬核系列歷史文章:(我保證每篇文章都有值得學習的地方,并且對小白有特別大的提高,敢說敢負責。)
這個系列入門級別的有萬字,有些文章十萬字。真的建議每篇文章都收藏
《這是全網最硬核redis總結,誰贊成,誰反對?》六萬字大合集
超硬核!操作系統學霸筆記,考試復習面試全靠它
超硬核!學霸把操作系統經典算法給敲完了!要知行合一
超硬核!數據結構學霸筆記,考試面試吹牛就靠它
超硬核十萬字!全網最全 數據結構 代碼,隨便秒殺老師/面試官,我說的
超硬核!數據庫學霸筆記,考試/面試隨便秒殺
不騙你,全網首創的超硬核的萬字SQL題
超硬核!小白讀了這篇文章,就能在算法圈混了
當年,兔子學姐靠這個面試小抄拿了個22k
反射全解
synchronized使用和原理全解
堆和棧的精華大總結
Java的IO總結
老師給的硬核移動端測試面試題目,大家看看靠譜嗎
超硬核!躺進BAT以后我總結了出現最多的15道數組題
一個神奇的大學科目《軟件工程》,知識點總結+測試題,包你不掛科
超硬核!我統計了BAT筆試面試出現頻率最高的五道題,學會了總能碰到一道
當年,學姐把這份Java總結給我,讓我在22k的校招王者局亂殺
超硬核萬字!web前端學霸筆記
?
面試經驗系列歷史文章:
這個系列離結束差的還特別多,會更新涵蓋所有一線大廠的所有崗位,也可以關注一下。
最容易進的大廠工作,百度經典百題
超經典,百度最愛考的安卓Android百題
超經典,阿里巴巴歷年高頻面試題匯總:前端崗
阿里巴巴歷年經典面試題匯總:Java崗
學姐百度實習面經
學姐,來挑戰字節最牛部門
最強阿里巴巴歷年經典面試題匯總:C++研發崗
關于我的那些面經——百度后端(附答案)
《關于我的那些面經》滴滴Java崗(附答案)
朋友面神策數據庫,第五個問題不會,直接再見
美女學姐面了美團阿里京東,這些經驗實在太真實了
學姐騰訊產品面經
學姐總結奇安信18k常問面試題
騰訊面試Android必問11題
?
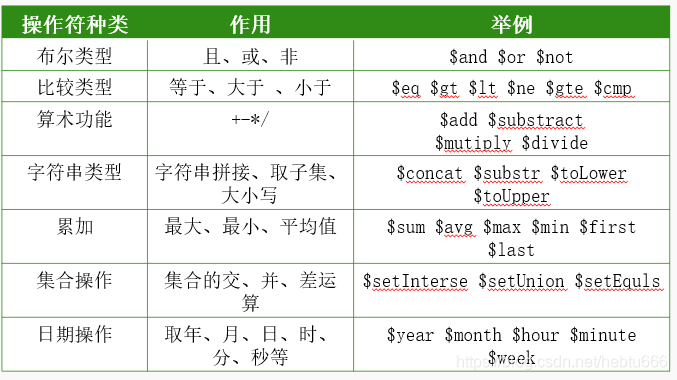
- NoSQL概述
- NoSQL數據庫的優勢:①支持超大規模的數據存儲②數據模型比較靈活
NoSQL數據庫的劣勢:①缺乏底層基礎理論做支撐②很多nosql數據庫都不支持事務的強一致性
-
- 關系數據庫的優勢:①具備非常完備的關系代數理論作為基礎②有非常嚴格的標準③支持事務一致性④可以借助索引機制實現非常高效的查詢
劣勢:①可擴展性非常差②不具備水平可擴展性,無法較好支持海量數據存儲③數據模型定義嚴格,無法較好的滿足新型web2.0應用需求
-
- 傳統的關系數據庫性能上的缺陷:①無法滿足海量數據的管理需求②無法滿足高并發需求
- NoSQL的四大類型:鍵值數據庫 ?列族數據庫 文檔數據庫 圖數據庫
- NoSQL數據庫的三大理論基石:①CAP ②BASE③最終一致性(會話一致性,單調寫一致性)
- Nosql數據庫具有的三個特點:①靈活的可擴展性②靈活的數據模型③和云計算的緊密結合
- Nosql興趣起的原因:①關系數據庫無法滿足web2.0的需求②數據模型的局限性
- Acid四性:A:原子性 C:一致性 I:隔離性 D:持久性
- MongoBD簡介
- 一個mongodb可以建立多個數據庫;mongdb將數據存儲為一個文檔,數據結構是鍵值對;多個文檔組成集合,多個集合組成數據庫
?
-
- 數據庫命名:
- 不能是空字符串("")②不能以$開頭③不能含有.和空字符串。
- 數據庫名字區分大小寫(建議數據庫名全部使用小寫)
- 數據庫名字長度最多64字節。⑥不要與系統保留的數據庫名字相同,這些數據庫包括:admin、local、 config等
- 文檔是MongoDB最核心的概念,本質是一種類JSON的BSON格式的數據。
- BSON是由一組組鍵值對組成,它具有輕量性、可遍歷性和高效性三個特征。可遍歷性是MongoDB將BSON作為數據存儲的主要原因。
- 適用場景:海量的數據存儲,json格式的數據,高伸縮性場景,弱事務型業務
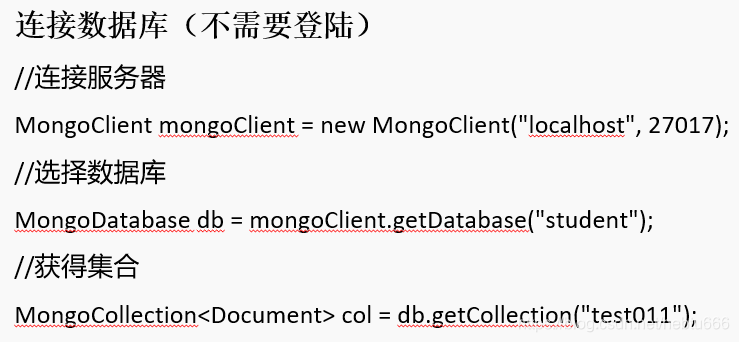
- 使用mongdb shell訪問mongdb:1)連接數據庫:mongo port 27017
2)連接遠程的mongdb服務器:mongo “mongodb://mongodb0.example.com:27017” ?3)查看所以數據庫:show dbs?? 4)創建數據庫:use DATABASE_NAME use database1? 5)創建集合:插入數據時候自動創建集合 6)插入文檔:db.cllection1.insert({name:”張三”,age:20})
7. 
- MongoBD數據模型
- MongoBD數據類型:
- 基本數據類型:
- Null 表示空值或者不存在的字段②布爾③數值類型④字符串⑤二進制數據可以保存由任意字節組成的字符串,例如:圖片、視頻等⑥正則表達式:{name:/foo/} name字段含有foo的文檔⑦JavaScript 代碼
- Date日期:new Date , 北京時間(CST) = UTC + 8個小時
- Timestamp(時間戳):只供mongdb數據庫內部使用,用于記錄操作的詳細時間,new Timestamp()
- ObjectId:總共12字節;

- 基本數據類型:
- MongoBD數據類型:
ObjectId()? 用于創建ObjectID;getTimestamp() 用于取得ObjectID的時間戳; valueOf()? 用于取得ObjectID的字符串表示
-
-
- 內嵌文檔
- 數組
- Mongdb客戶端的一基本命令:
-
- 連接/切換數據庫 – use test01;
- 數據插入 -- db.stu.insert(obj);
- 數據查詢 -- db.stu.find(query);
- 數據更新 -- db.stu.update(query,obj);
- 數據刪除 -- db.stu.remove(query);
- 實例(好好看看)
1、創建/切換數據庫:use db1
2、查看數據庫:show dbs
3、刪除當前數據庫:db.dropDatabase()
4、創建集合:db.createCollection("c1")
5、創建集合并添加數據
db.dept.insert({deptno:1,deptname:"技術部",location:"beijing"})
6、查看集合:show collections
7、刪除集合:db.collection_name.drop()
8、查看所有文檔數據:db.dept.find()
9、查看單獨的一個文檔:db.dept.findOne()
- 刪除指定文檔:db.dept.remove({deptno:1})
- 更新文檔:db.dept.update({deptno:2},{$set:{location:"shenzhen"}})
- 數據更新
- 數據更新三種:插入:insert;刪除:remove;修改:update
- Insert函數(只能作用于一個集合,集合不存在自動創建):db.集合名.insert(要插入的文檔,可選參數(設置安全級別))返回值:WriteResult({“nInserted”:1});??? db.collection.insertOne()
db.collection.insertMany()
-
- Remove函數:db.集合名.remove(查詢條件,可選參數(Boolean類型,只會刪除滿足條件的一個文檔)):db.student.remove({name:”tom”},true)
drop函數,不僅刪除文檔,還會刪除集合中的索引,db.test.drop()
deleteOne()和deleteMany()
-
- Bluk函數:(一共有兩種,順序和并行)
-
- db.集合名.initializeUnorderedBulkOp() 并行Bulk(以隨機的方式并行地執行添加到執行列表中的操作); ②db.集合名.initializeOrderedBulkOp()?? 順序Bulk(按照預先定義的操作順序);Bulk.insert()、Bulk.find.update()、Bulk.find.remove();Bulk.execute()
-
- Bluk函數:(一共有兩種,順序和并行)
var bulk=db.student.initializeOrderedBulkOp()?
var bulk=db.student.initializeUnorderedBulkOp();?
bulk.insert({name:"san",age:18})
bulk.insert({name:"si",age:18,})
bulk.find({name:"si"}).remove();
-
- Update函數:
db.集合名.update(查詢條件(相當于where);更改的內容(相當于set);查詢條件不存在時,選擇{ upsert:true}插入,false:不插入;查詢出多個文檔,選擇{multi:true}全部,false:第一條)
返回值:WriteResult({“nMatched”:1,“nUpserted”:0,”nModified”:1})
依次是:滿足的文檔個數 ;upsert:true時插入的個數;實際修改的文檔個數
更改操作符:

- db.update_test.update({_id:1},{$inc:{age:2}})
- db.update_test.update({_id:1},{$min:{age:3}})
③db.update_test.update(
?{name:"xiaoli"},
?{$set:{name:"xiaoli_update",age:28}},
?{multi:true})
-
- db.update_test.update({_id:1},{$rename:{age:"年齡"}})
- db.update_test.update({_id:1},{$unset:{年齡:""}})
⑥db.update_test.update({_id:1},{$unset:{年齡:1}})
內嵌文檔:①修改整個內嵌:{$set:{field1:新內嵌文檔}} ②修改內嵌的某個字段:{$某個更改操作符:{“field1.field2”:value}}
數組元素:

①db.array_test.insert([
{name:"joe",scores:[60,60,61,62]},
{name:"jack",scores:[]}
])
②db.array_test.update({name:"joe"},{$pop:{scores:-1}})
③db.array_test.update({name:"joe"},{$pull:{scores:{$gt:61}}})
MongoDB為$push和$addToSet提供了一組修改器(modifiers)。通過將操作符和修改器結合使用,可以實現更多復雜的功能

①db.array_test.update(
{name:"joe"},
{$push:{scores:{$each:[90,92,85]}}})
②db.array_test.update(
{name:"joe"},
{$push:{scores:{$each:[90,92,85]}}})
③db.array_test.update(
{name:"jack"},
{$push:
? {
?? scores:
??? {$each:[{course:"語文",成績:80},
??????????? {course:"數學",成績:95},
????? ????? {course:"外語",成績:70},
????? ?????? ],
????? ?$sort:{成績:-1},$slice:2} }})
-
- mongdb提供了四種寫入級別:①非確認式寫入②確認式寫入③日志寫入④復制集確認式寫入
- 數據查詢
- db.集合名.find(query,fields,limit,skip)
query:指明查詢條件 ?db.student.find({name:”joe”,age:{$lt:22}})
fields; 用于字段映射,指定是否返回該字段,0代表不返回,1代表返回,語法格式:{field:0}或{field:1}
limit:限制查詢結果集的文檔數量,指定查詢返回結果數量的上限
例如:db.student.find({name:”joe”},{“name”:1,”age”:1},2})
skip:跳過一定數據量的結果,設置第一條返回文檔的偏移量
例如:db.student.find({name:”joe”},{“name”:1,”age”:1},2,1})
-
- ①find函數一次只能查詢只能針對一個集合;②db.student.find()或db.student.find({})會返回所有文檔;③排序就是sort函數:db.student.find().sort({name:1,age:-1});④db.collection.findOne()只會返回第一條數據
- 比較查詢操作符

-
- 邏輯查詢操作符

?
-
- 元素查詢操作符
-
- 數據查詢操作符
- 內嵌文檔查詢:①查詢整個內嵌文檔:當內嵌文檔鍵值對的數量以及鍵值對的順序都相同時,才會匹配②查詢文檔的某個字段 ?需要.
db.student.find({“address.city”:”Beijing”})
-
- 數組操作符

與位置無關:db.student.find({“score.成績”: 80})
與位置有關:db.student.find({“scores.2.成績”: 95})
-
- 游標
-
- 提供的函數

- 游標的生命周期:游標的創建,使用以及銷毀三個階段
- 創建:var cursor = db.student.find().sort({age:1}).limit(2).skip(10);
- db.serverStatus().metrics.cursor? 查看當前系統的游標狀態
- 提供的函數
-
- 模糊查詢:使用$regex或者正則表達式
- 游標

{<field>:{$regex:/pattern/,$options:’<options>’}};
{<field>: /pattern/<options>}
在$In中只能用正則;在隱式的$and只能用$regex; option包含x或s時,只能用$regex
-
- FindAndModIfy函數:

- 索引
- mongdb索引的類型:
-
- mongdb索引的屬性:唯一性,稀疏性,TTL屬性
-
- 唯一索引(Unique Index):創建db.collection.createIndex( <key and index type specification>, { unique: true } )
-
- mongdb索引的屬性:唯一性,稀疏性,TTL屬性
為復合索引設置唯一屬性時,只能保證組合索引字段的唯一性,不能確保單個或索引字段自己的唯一性;id唯一索引是自動創建的不能被刪除
-
-
-
- 稀疏索引(spare index):db.student.createIndex({name:1}, {sparse:true})
-
-
指的是只為索引字段存在的文檔建立索引,即使索引字段的值為null,但不會為索引字段不存在的文檔建立索引。
-
-
-
- TTL索引(time-to-live index):為文檔設置一個超時時間,當達到預設值的時間后,該文檔會被數據庫自動刪除。對于緩存非常有用db.eventlog.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 3600 } )
-
-
復合鍵索引不具備生存時間特性
-
- Mongdb索引的管理:
-
- 索引的創建(一旦創建就不能修改,除非刪除重建,不能重復創建一個索引)db.collection.createIndex( <key and index type specification>, <options> )
-
- Mongdb索引的管理:
- Keys 用來指明創建索引的字段以及排序方向:
db.student.createIndex({name:1,age:-1})
- Options:用來設置索引的屬性以及其它輔助選項
db.student.createIndex({name:1,age:1},{name:’name_age’})

-
-
-
- 索引的查看
-
-
查看集合擁有的索引db.collection.getIndexes()

查詢建立索引的鍵名 db.collection.getIndexKeys()
-
-
-
- 索引的重建
-
-
重建當前集合的所有索引 db.collection.reIndex()先刪除在重建
查詢索引的大小 db.a1.totalIndexSize()?
-
-
-
- 索引的刪除
-
-
db.collection.dropIndex(index)
index:可以是索引的名字,也可以是創建索引時的keys文檔參數 ?db.student.dropIndex(‘name_age’)?? //索引名
db.student.dropIndex({name:1,age-1})??????? //keys參數
刪除集合中所有的索引 db.collection.dropIndexes()?
-
-
-
- 索引的查詢解釋器
-
-
db.collection.find().explain()
db.stu.find({age:22}).explain()??? ?db.stu.find({age:22}).explain(false)
db.stu.find({age:22}).explain(“queryPlanner”) queryPlanner:查詢計劃的選擇器,首先進行查詢分析,最終選擇一個winningPlan是explain返回的默認層面。
?
hint函數:db.集合.find().hint(index) index參數可以是索引的名字(字符串)或者創建索引時使用的keys參數。
??? Mongdb限制每個集合上最多只能創建64個索引
- 特殊索引
- 2dsphere 球面索引-創建

- 2dsphere 球面索引-創建

-
- 2d平面索引

-
- 全文索引

- 權限認證
- 創建管理員賬號
db.createUser({ user: “zhangsan”,pwd: “zhangsan123”,roles:[{ role:
“userAdmin AnyDatabase ", db: "admin" }] })
-
- 密碼認證:db.auth(“zhangsan”,”zhangsan123”)
- 授權:db.grantRolesToUser("accountUser01",[{role:"read", db:"stock" } ], { w: "majority" , wtimeout: 4000 } )
- 修改用戶密碼:
db.changeUserPassword("accountUser", "SOh3TbYhx8ypJPxmt1oOfL")
刪除用戶(只刪除當前數據中的football用戶)
-
- 刪除賬號:db.dropUser("football");
- 關閉mongdb服務:db.shutdownServer();
- 聚合
- 聚合管道的概述
-
- 聚合管道由階段組成,文檔在一個階段處理完畢后,聚合管道會將結果傳遞給下一個階段
- 針對聚合功能提供三種方式:聚合管道,單目的聚合操作,MapReduce編程模式
- MongoDB Shell使用db.collection.aggregate([{<stage>},…])來構建和使用聚合管道。
- 聚合管道的作用:對文檔進行過濾篩選符合條件的文檔;對文檔進行變換,改變文檔輸出格式
-
- 聚合管道操作符
-
- $project
-
- 聚合管道的概述
-
-
-
- $match
-
-

-
-
-
- $limit:{ $limit: <positive integer> }限制返回的文檔數量
-
-
db.article.aggregate([ { $limit : 5 } ]);
-
-
-
- $skip:{ $skip: <positive integer> }跳過指定數量的文檔
-
-
db.article.aggregate( { $skip : 5 } );
-
-
-
- $group:例如:db.books.aggregate( [ { $group : { _id : "$author", books: { $push: "$title" } } } ] )
- $sort:{ $sort: { <field1>: <sort order>, <field2>: <sort order> ... } }
-
-
排序db.users.aggregate( [ { $sort : { age : -1, posts: 1 } } ] )
-
-
-
- Out:{ $out: "<output-collection>" }
-
-
db.books.aggregate( [ { $group : { _id : "$author", books: { $push: "$title" } } }, { $out : "authors" } ] )
-
-
-
- $unwind:{ $unwind: <field path> },參數是數組類型將文檔按照數組字段拆分成多條文檔,每條文檔包含數組中的一個元素
- $lookup:
-
-

-
-
-
- 聚合管道表達式
-
-
-
- 單目的聚合操作
常用的主要有兩個:count和distinct
- 與Java
看雪梨TXT的第三題
 ?
?
- GridFS文件系統
- GridFS是mongdb提供的二進制數據的存儲解決方案,是專門為大數據文件存儲提供的存儲方案
- GridFS用兩個集合來存儲一個文件:fs.files 與 fs.chunks
- Mongofiles的使用:
-
- 上傳文件mongofiles? -d gfs put? d:/demo/baidu.jpg
- 顯示文件列表:mongofiles? -d gfs list
- 下載文件:mongofiles? -d gfs get
- 刪除 delete? 搜索search
-
- 復制集
- MongoDB的復制至少需要兩個節點。其中一個是主節點,負責處理客戶端請求,其余的都是從節點,負責復制主節點上的數據。
- 各個節點的屬性

-
- 復制集的搭建:①啟動多個mongdb實例②連接任意一臺mongdb實例(主節點)mongo –port27017 ③(主節點)初始化復制集 rs.initiate()④(主節點)查看復制集的狀態 rs.status()⑤(主節點)另外兩個從節點加入復制集rs.add(“127.0.0.1:27018”)
- 添加沖裁節點:①啟動仲裁節點所需的mongdb實例②連接上主節點③添加仲裁節點到副本集中rs.addArb(“127.0.0.1:27020”)④查看復制集狀態
- 將從節點變為仲裁者
1、確認該節點與所有客戶端都斷開連接2、關閉該從節點3、(主節點)將從節點從REPL的配置信息中刪除rs.remove(“127.0.0.1:27019”)
4、(主節點)確認復制集已經沒有該節點rs.conf()
5、將從節點的數據目錄刪除或者重命名6、創建新的目錄供仲裁節點使用
7、啟動仲裁節點所需的mongodb實例8、連接上主節點mongo --port 27018 ?9、添加仲裁節點到副本集中 10、查看復制集的狀態
-
 ?
?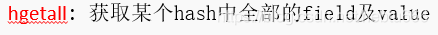
- 分片
- 分片的優勢:使用分片來支持具有非常大的數據集和高吞吐量的操作的部署。
- 三種服務器:路由服務器,分片服務器,配置服務器
- 為了將一個集合的所有文檔進行分片,mongdb通過shard key進行數據集的分割
- Mongdb將分片后的數據存在chunk中
- 兩種分片策略:哈希分片,范圍分片
- Redis簡介
- redis的特性:①開源免費②支持持久化③存儲類型豐富④支持數據備份
- redis的適用場合:①實時消息系統②排行榜③精準設定過期時間④計數器⑤最新N的數據操作
- redis相比memcached有哪些優勢:①memcached所有的值均是簡答的字符串,redis作為替代者,支持更為豐富的數據類型②redis的速度比memcached快很多③redis可以持久化其數據
- redis簡介:本質上是一個key-value類型的內存數據庫,很像memcached,整個數據庫統統加載在內存當中進行操作,定期通過異步操作把數據庫數據flush到硬盤上進行保存
?
- Redis的數據類型及操作
- String




-
- List


-
- Hash?


![]()
-
- Set





-
- Zset


-
- HyperLogLog

- Redis常用命令
- 鍵值相關命令:

?
-
- 服務器相關命令:

- Redis高級特性
- 持久化
-
- 快照是默認的持久化方式。這種方式是將內存中的數據以快照的方式寫入到二進制文件中,默認的文件名為dump.rdb。
- Redis 是一個持久化的內存數據庫
- Redis 提供了不同級別的持久化方式(內存的數據保存到磁盤上):
- RDB(Redis DataBase)持久化方式能夠在指定的時間間隔能對你的數據進行快照(SnapShot )存儲。
- AOF(Append Only File)持久化方式記錄每次對服務器寫的操作,當服務器重啟的時候會重新執行這些命令來恢復原始的數據,AOF命令以redis協議追加保存每次寫的操作到文件末尾,Redis還能對AOF文件進行后臺重寫,使得AOF文件的體積不至于過大。
-
- 持久化
?
-
- Rdb的優點與缺點
優點:①RDB是一個非常緊湊的文件②RDB在保存RDB文件時父進程唯一需要做的就是fork出一個子進程,接下來的工作全部由子進程來做,父進程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.③與AOF相比,在恢復大的數據集的時候,RDB方式會更快一些
缺點:①數據丟失風險大 ②RDB需要經常fork子進程來保存數據集到硬盤上,當數據集比較大的時候,fork的過程是非常耗時的,可能會導致Redis在一些毫秒級內不能響應客戶端的請求
-
- Aof的優點與缺點
優點:①AOF文件是一個只進行追加的日志文件 ②使用AOF 會讓你的Redis更加靈活: 你可以使用不同的fsync策略 ③redis可以在 AOF 文件體積變得過大時,自動地在后臺對 AOF 進行重寫 ④AOF文件有序地保存了對數據庫執行的所有寫入操作, 這些寫入操作以 Redis 協議的格式保存, 因此 AOF 文件的內容非常容易被人讀懂, 對文件進行分析也很輕松
缺點:①對于相同的數據集來說,AOF 文件的體積通常要大于 RDB 文件的體積 ②根據所使用的 fsync 策略,AOF 的速度可能會慢于 RDB
-
- Redis事務的相關命令有哪幾個 ①MULTI②EXEC③DISCARD④WATCH
- 主從復制
- 主從復制原理
通過主從復制可以允許多個slave server擁有和master server相同的數據庫副本。 ????主從復制特點:
-
-
-
- master可以擁有多個slave
- 多個slave可以連接同一個master外,還可以互相連接
- 主從復制不會阻塞master,在同步數據時,master可以繼續處理client請求?? ④提高系統的伸縮性
- 主從復制過程
- slave與master建立連接,發送sync同步命令 ②master會啟動一個后臺進程,將數據庫快照保存到文件中,同時master主進程會開始收集新的寫命令并緩存。③后臺完成保存后,就將此文件發送給slave ④slave將此文件保存到硬盤上
-
- Redis發布/訂閱(RUB/SUB)
-

-
- 安全性:設置客戶端連接后進行任何命令前需要使用的密碼
- Redis-Sentinel機制 ???故障切換的原理:

















健康度系統)

定時系統(延時隊列))