本系列用大白話,手把手帶你實現上百個BAT公司內部真實的常用中型系統。評論抽獎送書
與培訓班/營銷號/忽悠人的低水平作者,不同的是:
保證聽懂(小白也可以,這是我的一貫風格,字典式小白式的輸出,大家容易交流)
絕對真實(保證業內調查過、BAT級別公司實現過,有的作者異想天開的自嗨,能看到一堆漏洞)
歡迎討論(你進步我也進步,最好懟死我,讓我知道我是井底之蛙)
?什么?你問我為啥只寫中型系統不寫大型系統?第一,我自己還沒玩明白呢就不誤人子弟了。第二、大系統敏感信息很難完全清干凈,怕被告。第三、能真正看懂的人也少。
一、背景
引子是讓你明白本文可以作為供應商/合作方管理系統的實現,你也可以應用在其他系統中。
首先,讀者應該明白,現如今獨自一套系統就能服務于用戶的情況很少,大多都要請求本系統外的其它系統(這些系統可能是內部的或是外部的),大家互相交互才形成了可以服務于真正用戶的互聯網功能,我隨便舉幾個例子:
1)騰訊視頻做的,開通騰訊會員+任意合作方會員的組合,需要和多個合作方(酷狗、酷我、體育)的系統進行交互。
?2)騰訊自選股(或者任何買賣股票的app),他可能自己賣股票嗎?不可能的,內部對接了不知多少券商(業內一般稱為“上游”,即實際提供服務方)
?3)支付寶/微信充話費,是支付寶自己能操作你手機號里的錢嗎?不是,是支付寶對接了移動聯通電信三大運營商,包括全國總公司、省級分公司、市級供貨商等等
這也引出了一個問題:你內部系統的服務質量,基本依賴于你的對接方系統質量。
比如,我們內部系統做的特別好,0.01秒就為用戶做好了一切工作,有用嗎?并沒有,因為真正提供服務的是你的合作方(上文提到的炒股app對券商、支付寶充話費對中國移動,以下統稱為合作方),如果合作方的系統特別爛,買個股票永遠成交失敗,沖個話費三天才到賬,你的系統再好也沒有。
二、需求分析
基于上文提到的背景,大部分公司都會有這么一種訴求:健康度系統,它可以識別外部系統的健康度,并根據健康度控制流量。
說簡單點就是,你(合作方)系統老是辦理失敗,那我就不讓用戶從你的系統辦了,否則降低收入不說(因為成功率低),我的用戶還會罵我(還是成功率低/耗時高)。
三、目標明確
目標很明顯,只要我們知道某個合作方是不健康的,就生成一條記錄,代表他被打入冷宮,我們的系統查到記錄就不會讓用戶訪問它。
當然,完全自動識別健康度是不可靠的(畢竟是機器),我們必須有人工介入的手段,首先我們允許合作方主動通知我們系統不健康(比如在維護升級、在調整東西、服務出問題、不在交易時間內等等),我們得到這個消息就可以做相應的調整(不讓用戶看到他家產品)
目標一:正確接收到合作方系統不健康的消息
其次,也不能完全信合作方的操作,我們系統內部也要有人為干預的手段,方便我們管理。比如我們觀察到某個合作方質量很差,就手動給他標為不健康。如果我們和某個合作方掙錢很多,就算質量差,我們可能也會手動給他刪除不健康記錄。
目標二:系統內部可以操作不健康消息(增加/刪除/修改/查詢)
保證兩邊人工操作沒問題后,我們再做自動識別:
目標三:系統自動識別不健康合作方,并生成不健康記錄
有心人看到這里肯定會問了:你這不健康就永遠不合作了?永遠打入冷宮了?當然不是,我們識別到健康度達標(可能人家系統恢復了、優化了),要繼續讓用戶來這個合作方消費。
目標四:系統自動識別健康度再次達標的合作方,并刪除不健康記錄
至此,我們的功能就算是說完了,接下來分析一下我們的系統需要注意的問題
四、系統設計重點
大部分系統的重點一般在:性能、可用性、安全三方面來說。
4.1 性能
因為考慮到每個用戶請求進來,都要獲取各個合作方的健康度信息(為了動態推薦商品之類的),為了速度考慮,最好所有信息都在某塊內存(redis),可以直接查到。
所以我們最好將所有的數據生成工作提前做好,這里包括但不限于:
1)獲取合作方提供的健康度信息(不可能每個用戶請求都去請求合作方系統)
2)判斷健康度需要的數據的獲取(包括是否連通、成功率、平均耗時、配置等)
3)健康狀態的判斷和灰度邏輯(不可能每個用戶請求來現場算是否健康)
4)健康狀態信息緩存(存redis加快讀取速度)
4.2 可用性
需要明白的是,我們的系統始終是一個可旁路系統,首先要考慮我們的系統掛了或者經常超時怎么辦?絕對不能影響主系統主流程的運行。
為了達到這個目的,我們可能的策略包括但不限于:
1)某些降級策略,如健康度功能不可用時,根據配置的默認順序來推薦合作方。
2)可配置超時時間,按時沒運行完也要返回
其次,我們要保證誤判盡量的少,保證最大的正確性,為此,我們可能的策略是:
1)合理的判定不健康算法、平滑的過渡方式
2)判斷健康的所有指標都可配置,實現精細化運行,根據具體合作方的實際情況配置。
4.3 安全
保證和外部交互健康度數據、內部存儲健康度數據都是安全的。
和外部交互時:簽名+加密
內部存儲時:簽名
這里普及一些基本知識,后續文章不會再提:大家提到安全老是說簽名和加密,他們的作用是不同的。
簽名主要功能是防篡改,是無限集合(真實內容)向有限集合(簽名)的映射,根據簽名是無法還原內容的,接收方收到內容后,按約定的算法和密鑰算出簽名,和收到的簽名一樣就是沒被篡改。
加密主要功能是防泄漏,是無線集合向無限集合的映射,因為陌生人即使拿到了整個消息,依舊看不懂寫的什么,而接收方解密拿到明文可以進行處理。
至于簽名和加密的算法的種類本系列也不會再科普,可以自己上網搜一下。
五、方案設計概述
由于功能較多,我們大概分兩階段實現:
第一步先把合作方和本系統內部的人為干預手段做好,并且搭起基本架構,開始對外提供服務(即,其他服務可查詢合作方是否健康了)
第二步我們再把自動判定健康的數據獲取、判定健康、根據健康度控制流量等功能補齊。
為了方便,我們把代表某合作方不健康的一條記錄,稱為“公告”,
意思是我(合作方)發公告告訴所有關心的模塊:我不健康了
六、手動設計
為了方便理解方案,一種可能的基本存儲結構是這樣的:
6.1 db存儲結構
create table xxtable
(Fid?????????????? bigint not null auto_increment,F***_id??????? varchar(64) not null default '' comment '供應商id',F***_id?????? varchar(64) not null default '' comment '公告id',Fcreatetime?????? DATETIME not null comment '公告創建時間',Fupdatetime????? DATETIME not null comment '公告更新時間',Fuserid?????? ????varchar(64) not null default '' comment '操作用戶id',Fbegintime?????? DATETIME not null comment '公告開始時間',Fendtime???????? DATETIME not null comment '公告結束時間',Fty?????????? int unsigned not null default 0 comment '類型0:運營商1:后臺2:自動’,Fstatu??? ?????? int unsigned not null default 0 comment '狀態 0:無效? 1:生效中',Fchanged_count
);當然,這是基本字段,有需要你再加。
ckv的區別是增加一個合作方公告開關
6.2 Ckv存儲結構
//不健康信息
//供應商公告keykey:?{"ID":"xxservice_gddianxin"}//前綴+供應商id?//Boss后臺配置的公告keykey:?{"ID":" xxservice_gddianxin_boss"}//前綴+供應商id+后綴value:?[???{???"":"gddianxin", //供應商id?"ID":"123123123",? //記錄序列id?"begin":"2020-7-2 00:00:00",? //開始時間?"end":"2020-7-3 00:00:00",? //結束時間?"eff":true?? //是否生效,部分供應商可能存在取消的情況?}]??//公告開關key:?//前綴+供應商id+后綴{"ID":"xxservice_gddianxin_flag "}?value:1(2)//1:打開,2:關閉6.3 協議設計
和合作方交互的接口可能長這個樣子:
我方請求合作方:
1. <?xml version="1.0" encoding="UTF-8"?>
2. <req>
3. <timestamp>1514736000</timestamp>
4. <signmsg>XXX</signmsg>
5. <channel>zhifubao</channel>
6. </req>
合作方的返回(解密后):
1. <?xml version="1.0" encoding="UTF-8"?>
2. <rtn>
3. <code>0</code>
4. <msg>同步成功</msg>
5. <channel>0</channel>
6. <upgradeInfo>
7. <item>
8. <upgradeID> UC-051-20200702-96038</upgradeID>
9. <upgradeContent>系統故障</upgradeContent >
10. <beginTime>2020-7-2 00:00:00</beginTime>
11. <endTime >2020-7-3 00:00:00</endTime>
12. <effective>true</effective>
13. </item>
14. <item>
15. <upgradeID> UC-051-20200703-96000</upgradeID>
16. <upgradeContent>系統升級</upgradeContent >
17. <beginTime>2020-7-3 00:00:00</beginTime>
18. <endTime >2020-7-4 00:00:00</endTime>
19. <effective>true</effective>
20. </item>
21. </upgradeInfo>
22. </rtn>
Code是返回碼,upgradeInfo是公告列表,含有多個公告主體。公告主體含有升級序列id、升級內容、開始時間、結束時間、生效標志等字段。注意:如某公告被取消,不應在運營商返回的報文中直接消失,而是應將effective置為false;
科普一種可能用到的通信時加密簽名算法-
sha256_HMAC作為簽名的算法,案例如下:
第一步,假若傳入如下參數:bank_type=WX;fee_type=1,body=XXX;
第二步,按照參數key值進行字典排序(按照字段名的ASCII 碼從小到大排序),并且使用”&”作為分隔符,把參數串成字符串。bank_type=WX&body=XXX&fee_type=1;
第三步,用雙方約好的密鑰secret_key,對組裝的字符串進行加密signmsg=sha256_HMAC_func(secret_key ,? bank_type=WX&body=XXX&fee_type=1)。
其它協議如:我方服務的查詢接口、定時任務接口、合作方主動推送接口,請自行設計,字段都非常簡單,不再說了。
定完協議我們可以看基本架構是什么樣子
6.4 架構設計
在設計前,我們再次明確之前提到的設計重點:性能、可用性、安全,忘了的同學翻上去看。
基于性能考慮,我們需要讀寫分離,讀操作直接讀redis,節省時間。
基于可用性考慮,我們的定時任務鏈路和查詢都需要層層注意。
基于安全考慮(信息的安全和服務本身的安全),我們的外部交互協議和運營后臺很重要。
基于這些考慮,設計是這樣的:

介紹一下模塊:
定時任務負責定時觸發查詢
運營商接入服務負責調取運營商接口,向上屏蔽運營商接口的不一致性,對內提供標準接口。同時方便做一些安全的校驗。
公告服務提供核心的查詢和寫入功能。
了解模塊后,詳細解釋一下三條鏈路的策略:
(性能讀redis很快就不說了,主要是挑戰1:可用,挑戰2:安全)
首先看定時任務鏈路(左方藍線):
1)定時任務請求獲取公告接口。它應部署在多臺腳本機,如果其中一臺出現問題,其它機器依然正常工作。萬一真的都掛了,就要觸發監控和報警,通過微信或電話直接提示負責人,盡快解決問題。
2)鏈路往下走,獲取公告接口,負責調用運營商接入服務獲取信息,并寫入redis。
3)而運營商接入服務,負責調取運營商接口,向上按標準參數返回。由于查詢的無狀態,可以多機部署,某臺機器掛了可以自動切量。
??? 總體看一下這條鏈路,各模塊有自己的機制保證可用性,如果確實整條鏈路失效了,公告信息就會暫停更新,不會造成更壞的影響。
??? 然后看查詢主鏈路(中間紅線):
1)和其他服務交互部分,請求查詢公告接口。如果請求異常,會有降級策略:返回系統未維護。另外由于查詢是無狀態的,多機部署(采用類cl5的策略)保證可用性。
2)鏈路往下走,查詢公告接口,它會查詢公告信息redis,然后返回結果。這里對查詢結果的各種情況的處理就非常關鍵。
對于明確成功的結果,就正常返回。對于超時、明確失敗、未知情況,都會有降級策略,返回運營商未維護。其中,對于超時情況,筆者設置了超時時間為50ms,保證主鏈路不會耗時過長。
筆者解決了第一個挑戰,再看第二個挑戰 是由運營后臺鏈路(右方黑線)加入了人工干預手段,保證了系統故障時有人為干涉的兜底策略。
總體看筆者的系統:除了redis其他地方都是無狀態的,所以可以多機部署,任何機器出現問題,都會有其他機器保證可用。而對于redis,筆者有查詢降級策略和設置超時時間,即使掛了也不影響主鏈路。所以總體來說,筆者解決了上面提到的兩個挑戰。
七、自動設計
剛才我們實現了人工干預手段和公告服務的基本框架,接下來我們完善自動健康度的功能。
那么一個健康度系統的第一步,就是如何判定不健康。
7.1 準備需要的信息
我們需要讀到成功率、耗時、探測等數據,考慮到不能因為新系統需要的操作就影響老流程,我們必須做成異步寫的,下面我列舉幾種可能的方法:
7.1.1 其他服務寫redis
數據是由redis存儲的,記錄分鐘內請求成功失敗數量,最后一次請求是否成功,下面是某示例:
Key 供應商_id + 接口 + 時間 + req_num
key:??Gmccactive_order_202010101500_req_num
value: 22
key:??Gmccactive_order_202010101500_succ_num
value: 50
key:Gmccactive_last_req
value: 1當然,寫操作可以自己決定一下是否異步。
可以自己實現異步,也可以同步(畢竟寫redis操作還是挺快的)
7.1.2 其他服務生產消息
讓其他服務放一個消息在消息隊列里(rabbitmq、kafka等),里面有本次請求成功失敗和耗時,公告服務來消費即可。
7.1.3 公告服務讀DB
一般情況下,其它系統都會有訂單DB、請求流水DB、日志DB等等,如果評估可以使用,就不需要別的服務上報,配置腳本去撈DB信息即可。
7.1.4 建議
一般情況下我建議你方法1和方法2中選擇方法1(畢竟一個redis物盡其用,沒必要引入消息隊列)
剩下這兩種方案各有利弊,實時上報單次計算成功率的耗時更少,但是需要暫存下單數據,會影響下單流程。而拉流水不用暫存數據也不會影響下單流程,但是單次計算成功率耗時會多一些,包括了拉取流水和計算。
7.2 判定不健康

掛起公告實例圖
(1)探測、多維度檢測實時成功率、耗時進行判斷。
(2)大概的代碼邏輯應該是這樣:
if 探測失敗次數高于閾值:掛起公告
if 請求量大于閾值 and (成功率低于某閾值 or 耗時高于某閾值):掛起公告。?這兩方面分別保證的系統正常(ping通就可以)和業務正常(具體成功率耗時達標)。
7.3 如何探測
7.3.1 類CL5健康度方案:

類CL5健康度方案圖
每隔1個周期ping探測運營商接口聯通性,如果ping成功,則開始放量真實量,統計周期內失敗數量與失敗率,如果高于閾值時按照一定比例開始恢復。
單機方案在此場景不可用,因為Ping 探測接口連通性,不能解決業務錯誤問題。
7.3.2 全局灰度方案:
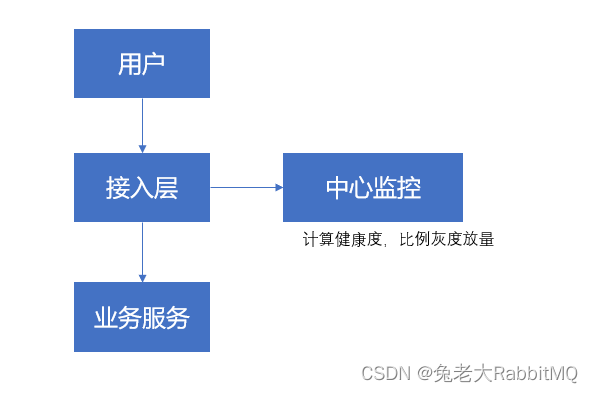
全局灰度方案圖
由健康度服務進行選擇灰度放量,進行真實量探測。當成功量上升時,灰度比例增大到直接放開;當成功率下降時,灰度比例下降,延長時間。
經評估缺點如下:損失業務真實量、開發成本較高、量級波動大時,成功率變化時,會出現反復較少放大比例的問題。
7.3.3 重放線上真實量
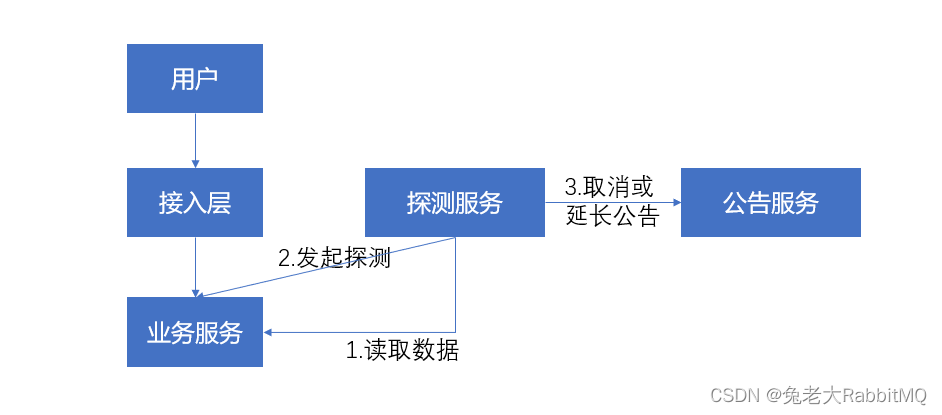
圖3-8 重放線上真實量圖
獲取線上真實請求,周期內進行n次重試,計算成功率,連續m個周期內,成功率達標后,放開公告。優點是用戶無感知,實時性高,但是如果用戶未黑名單用戶,可能會誤以為系統異常。
對于重放的接口有多種選擇,重放辦理接口和重放查詢接口的選擇:只能是重放查詢接口,因為部分運營商不支持冪等,重復辦理風險。(就是存在一人重復辦理多筆單的風險,但只是查詢商品就無所謂)。
既然恢復可以用重放探測,筆者提出一個假設:一直重放,僅按照重放的量來計算如何掛公告。因為部分運營商在辦理成功后,下次查詢就會失敗。而且對于量小的運營商,重放量可能大于正常量。因此,不適合只用重放量來計算健康度。
提示:因為考慮法律問題,我們沒有權利替用戶發起任何請求請求,包括查詢商品請求,所以方案三一般不考慮。
7.3.4 總結
如果不考慮方案三的話,可能比較優秀的做法就是方案1+方案2結合起來看,稍作修改即可。
方案2的缺點正好可以被方案1彌補,我們先做探測,如果達標再進行方案2的灰度。
大概的流程粗略看可能是這樣:

7.4 完成設計
有了大概思路,我們應該把所有的想法用公式和圖表示出來:


?關于更具體的代碼,我希望你能自己寫出來,我在這里提供一種簡單的方法,你可以把心里的詳細狀態扭轉全部畫出來,然后轉化成表格形式,我們剩下的工作就這是看著表格寫代碼而已,非常方便。(只是自動機的一點用法,acm大佬可忽略)


小提示:如果對這種思想比較感興趣,我想你一定做過leetcode第八題,字符串轉換整數 (atoi),可以看看這個題解來入門這種思想:題解
八、總結和QA
8.1 全局架構圖
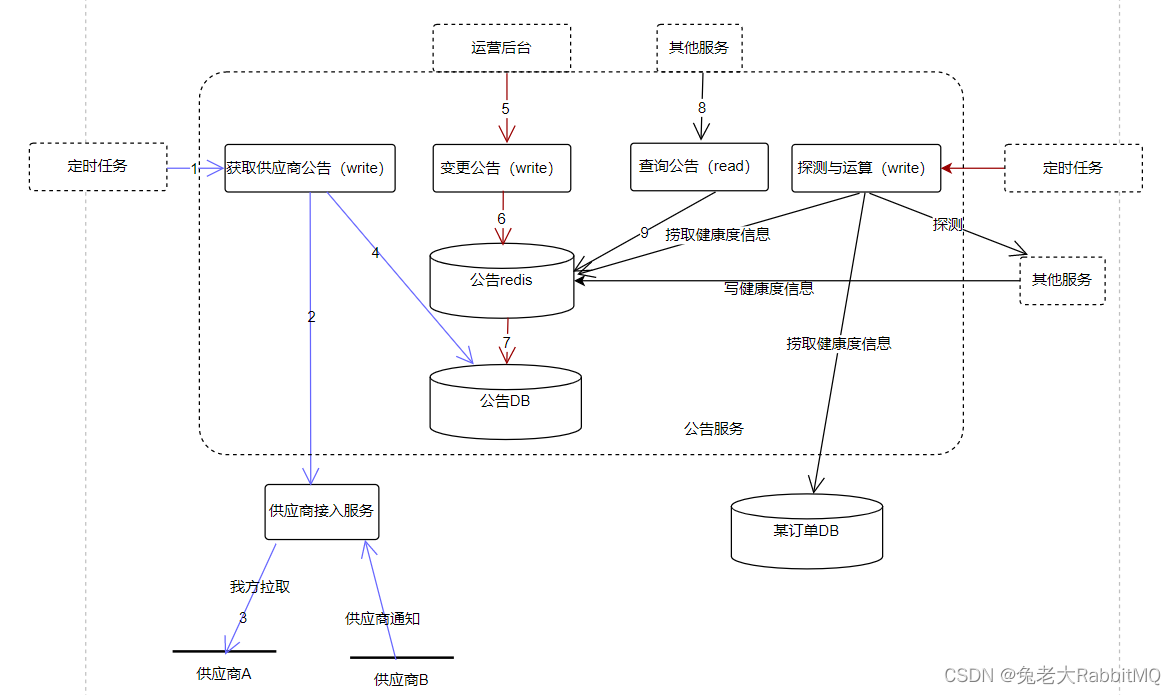
8.2 為何讓其他服務直接操作redis?
剛說了不使用消息隊列是因為嫌麻煩。
同時,其他服務也不是直接操作redis,它們也并不知道怎么操作。肯定是公告服務提供的接口呀。(圖中沒畫了)
?8.3 說為了安全要加密外部交互信息,但文中協議沒有
是為了讓讀者理解,協議是解密之后的明文。
8.4 看完還是一臉懵,不會寫
實在有需要可以找我,我可能會給你時序圖之類的資料,但是代碼不可以。
8.5 為何必須有redis緩存?我想結構簡單一點
如果你想服務內本地緩存,也可以,只是緩存命中率會比較低,因為真實環境動輒幾十上百個進程。

定時系統(延時隊列))

)






【上】)

【下】)






