極簡模式
假設我的系統只有一種調度算法cfs
那么有個調度的隊列 cfs_rq
所有running的進程都會 進入這個隊列,不在running 或者其他情況會出隊列,ok。則假設隊列控制的算法有以下。
cfs_rq_enqueue
cfs_rq_dequeue
cfs_rq_pick
所操作的是進程描述符 task_struck.
那么很簡單可以理解上述過程
scehed_pick ---->cfs_rq_pick就行了。
多個調度算法
那么如果除了cfs還有rt算法
那么就有兩個調度隊列,cfs_rq和rt_rq。
一個進程task_struck 有可能屬于cfs和rt。
那么考慮 scehed_pick 是如何pick?
ok,Linux建立一個sched_class 的結構鏈表,sched_class_cfs和sched_class_rt或者還有其他的。順序的從這么多個調度算法中選擇一個合適的。
stop_sched_class -> -> rt_sched_class -> fair_sched_class -> idle_sched_class
如上。那么問題來了,如果前面的隊列一直滿足,后面的隊列就永遠得不到執行,這些sched_class之間沒有個合理的邏輯嗎?
目前看到的邏輯,任務dl 是最先滿足的,rt次之,cfs隨后,idle當然是最后的,這樣的邏輯,基本上能讓人有點信服。
能信服,不夠科學吧???還是有什么我沒有看到的優先級。???
再抽象一層sched_entity
一般情況 cfs和rt或者其他的什么的調度算法的接口 enqueue或者dequeue 都是對task_struck 進行操作的。
但是Linux 這里再抽象一個sched_entity,每個task_struck 對應一個sched_entity 。調度算法對sched_entity操作就行了。
這樣抽象我猜想有兩個目的,一個是統一比較好看,和task_struck隔離。第二個是,為了下面的組調度做準備。
加入組調度
組調度的數據結構,和組織架構大概是如下這個樣子
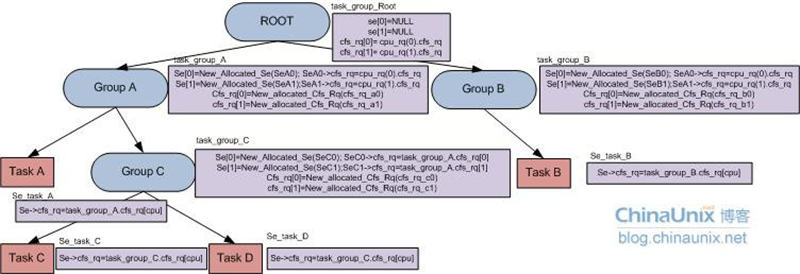

OK,如果Linux進行組調度,就不會說使用全局的cfs_rq隊列,或者rt_rq隊列。而是將這些隊列分配到task_group中。大概流程是這樣子的。
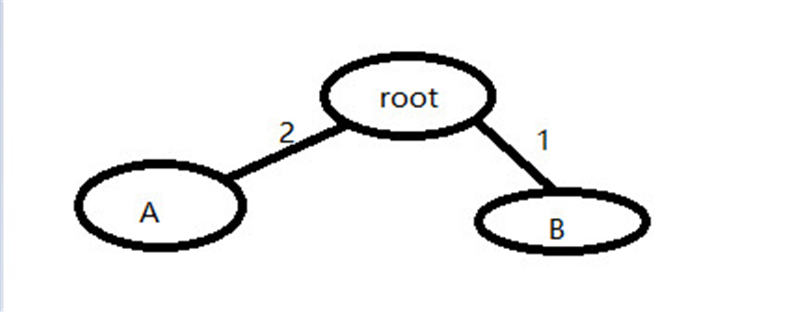
我們假設我們有兩個組 GroupA 和GroupB A占2 B占1 就是有三次調用的情況下 A組會被調用兩次,B組只有1次。
這個時候有一個進程啟動了 task_struck task1
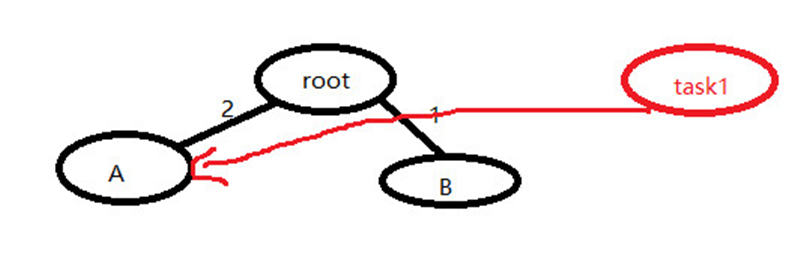
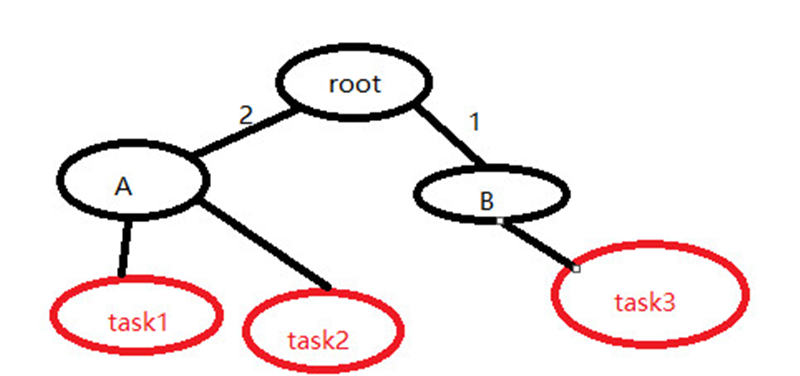
他選擇A組,同理task2 可能也選擇A task3可能選擇B 如下
而A 和 B 不會記錄 task的接口體,他記錄task 的sched_entity 并用一個se[] 數組表示。
那么還有,task1 task2 有可能是cfs調度也有可能是rt,那么gruop結構體就用 cfs_se[] cfs_rq 和 rt_se[] rt_rq記錄。
那么問題來了
task1 task2 屬于cfs還是屬于rt 是什么時候設置的?
在Android和linux里面沒有看到,目前看到的是 0 也就是cfs,
那么有以下可能就是說,如果你不設置,就默認是0,或者繼承父親的等等這種默認策略。
scehed_pick 時候怎么pick?
按照pick三次 兩次是A,ok。到了A,再使用這個策略
stop_sched_class -> dl_sched_class -> rt_sched_class -> fair_sched_class -> idle_sched_class
這個是說的通的。
但是要根據代碼來。
接下來分析調度過程。



















