torchvision 目標檢測微調
本教程將使用Penn-Fudan Database for Pedestrian Detection and Segmentation 微調 預訓練的Mask R-CNN 模型。 它包含 170 張圖片,345 個行人實例。
定義數據集
用于訓練目標檢測、實例分割和人物關鍵點檢測的參考腳本允許輕松支持添加新的自定義數據集。數據集應繼承自標準的 torch.utils.data.dataset 類,并實現 __len__ 和 __getitem__ 。
__getitem__ 需要返回:
image: PIL 圖像 (H, W)
target: 字典數據,需要包含字段
boxes (FloatTensor[N, 4]): N 個 Bounding box 的位置坐標 [x0, y0, x1, y1], 0~W, 0~H
labels (Int64Tensor[N]): 每個 Bounding box 的類別標簽,0 代表背景類。
image_id (Int64Tensor[1]): 圖像的標簽 id,在數據集中是唯一的。
area (Tensor[N]): Bounding box 的面積,在 COCO 度量里使用,可以分別對不同大小的目標進行度量。
iscrowd (UInt8Tensor[N]): 如果 iscrowd=True 在評估時忽略。
(optionally) masks (UInt8Tensor[N, H, W]): 可選的 分割掩碼
(optionally) keypoints (FloatTensor[N, K, 3]): 對于 N 個目標來說,包含 K 個關鍵點 [x, y, visibility], visibility=0 表示關鍵點不可見。
如果模型可以返回上述方法,可以在訓練、評估都能使用,可以用 pycocotools 里的腳本進行評估。
pip install pycocotools 安裝工具。
關于 labels 有個說明,模型默認 0 為背景。如果數據集沒有背景類別,不需要在標簽里添加 0 。 例如,假設有 cat 和 dog 兩類,定義了 1 表示 cat , 2 表示 dog , 如果一個圖像有兩個類別,類別的 tensor 為 [1, 2] 。
此外,如果希望在訓練時使用縱橫比分組,那么建議實現 get_height_and_width 方法,該方法將返回圖像的高度和寬度,如果未提供此方法,我們將通過 __getitem__ 查詢數據集的所有元素,這會將圖像加載到內存中,并且比提供自定義方法的速度慢。
為 PennFudan 寫自定義數據集
文件夾結構如下:
PennFudanPed/PedMasks/FudanPed00001_mask.pngFudanPed00002_mask.pngFudanPed00003_mask.pngFudanPed00004_mask.png...PNGImages/FudanPed00001.pngFudanPed00002.pngFudanPed00003.pngFudanPed00004.png
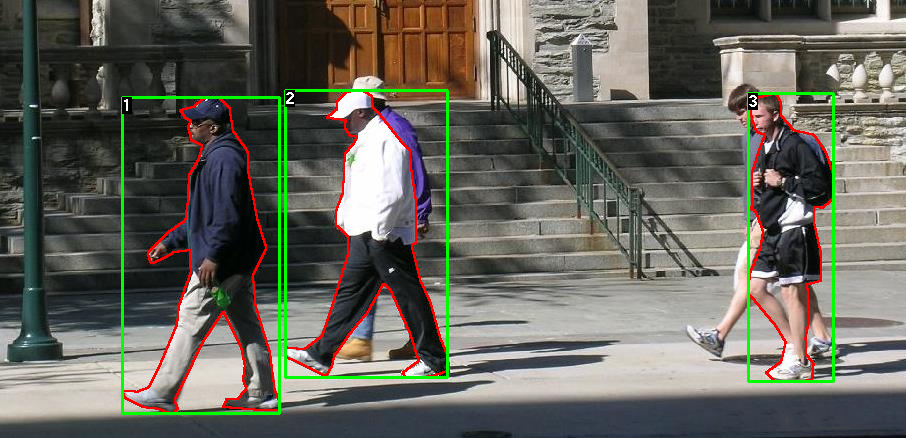
這是圖像的標注信息,包含了?mask?以及?bounding box?。每個圖像都有對應的分割掩碼,每個顏色代表不同的實例。

import os
import numpy as np
import torch
from PIL import Imageclass PennFudanDataset(torch.utils.data.Dataset):def __init__(self, root, transforms):self.root = rootself.transforms = transforms## 加載所有圖像,sort 保證他們能夠對應起來self.images = list(sorted(os.listdir(os.path.join(self.root, 'PNGImages'))))self.masks = list(sorted(os.listdir(os.path.join(self.root, 'PedMasks'))))def __getitem__(self, idx):img_path = os.path.join(self.root, 'PNGImages', self.images[idx])mask_path = os.path.join(self.root, 'PedMasks', self.masks[idx])image = Image.open(img_path).convert('RGB')## mask 圖像并沒有轉換為 RGB,里面存儲的是標簽,0表示的是背景mask = Image.open(mask_path)# 轉換為 numpymask = np.array(mask) # 實例解碼成不同的顏色obj_ids = np.unique(mask)# 移除背景obj_ids = obj_ids[1:]masks = mask == obj_ids[:, None, None]# get bounding box coordinates for each masknum_objs = len(obj_ids)boxes = []for i in range(num_objs):pos = np.where(masks[i])xmin = np.min(pos[1])xmax = np.max(pos[1])ymin = np.min(pos[0])ymax = np.max(pos[0])boxes.append([xmin, ymin, xmax, ymax])# 轉換為 tensorboxes = torch.as_tensor(boxes, dtype=torch.float32)labels = torch.ones((num_objs,), dtype=torch.int64)masks = torch.as_tensor(masks, dtype=torch.uint8)image_id = torch.tensor([idx])area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])iscrowd = torch.zeros((num_objs,), dtype=torch.int64)target = {}target["boxes"] = boxestarget["labels"] = labelstarget["masks"] = maskstarget["image_id"] = image_idtarget["area"] = areatarget["iscrowd"] = iscrowdif self.transforms is not None:image, target = self.transforms(image, target)return image, targetdef __len__(self):return len(self.images)
Lnton羚通專注于音視頻算法、算力、云平臺的高科技人工智能企業。 公司基于視頻分析技術、視頻智能傳輸技術、遠程監測技術以及智能語音融合技術等, 擁有多款可支持ONVIF、RTSP、GB/T28181等多協議、多路數的音視頻智能分析服務器/云平臺。






動態規劃設計:最長遞增子序列)
)


)
)



)




