如果您有興趣了解有關如何對AI大型語言模型或LLM進行基準測試的更多信息,那么一種新的基準測試工具Agent Bench已成為游戲規則的改變者。這個創新工具經過精心設計,將大型語言模型列為代理,對其性能進行全面評估。該工具的首次亮相已經在AI社區掀起了波瀾,揭示了ChatGPT-4目前作為性能最佳的大型語言模型而位居榜首。
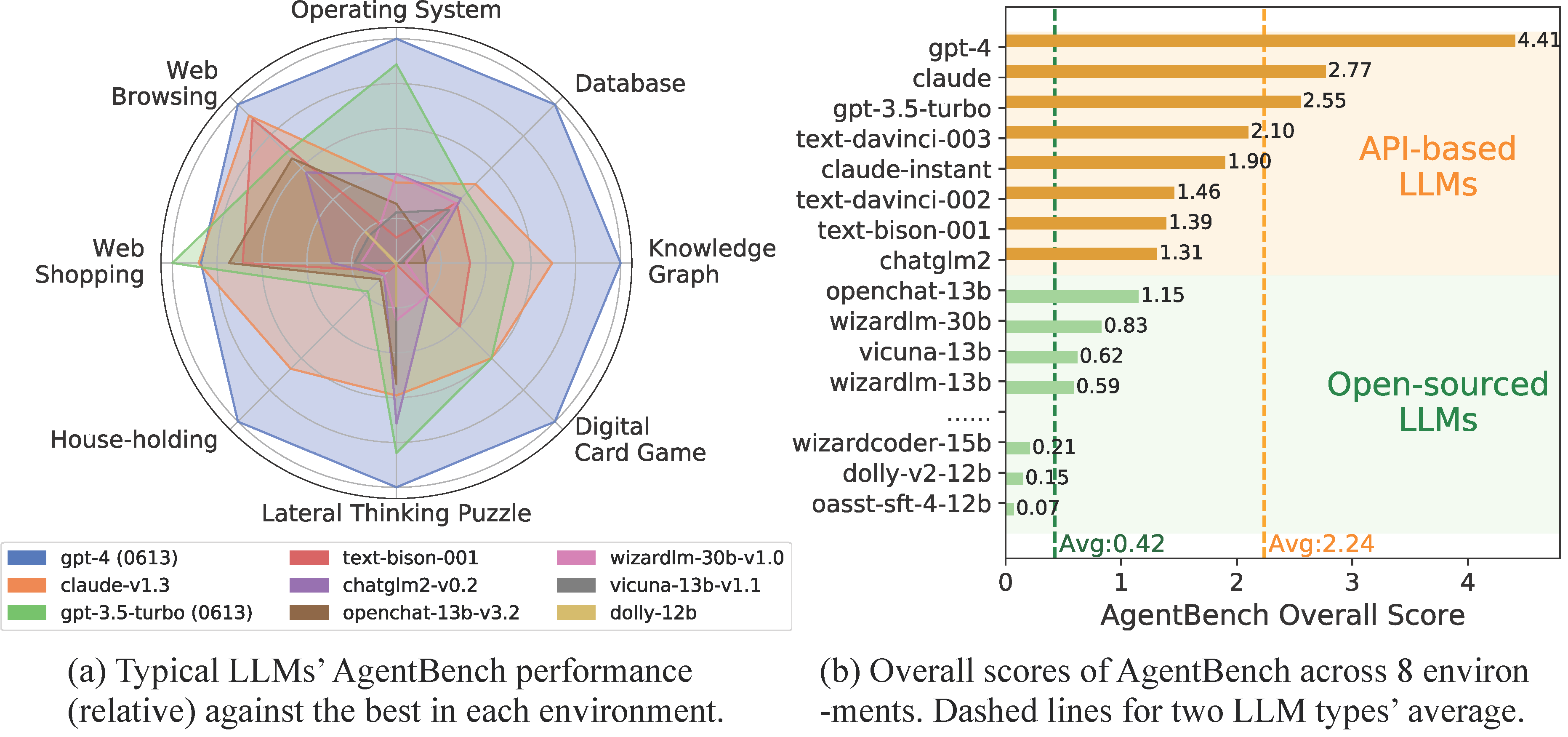
Agent Bench不僅僅是一種工具,而是AI行業的一場革命。它是一個開源平臺,可以在桌面上輕松下載和使用,使廣泛的用戶可以訪問它。該工具的多功能性體現在它能夠在八個不同的環境中評估語言模型。這些包括操作系統、數據庫、知識圖譜、數字紙牌游戲、橫向思維拼圖、家務、網上購物和網頁瀏覽。
AgentBench 基準測試工具演示
AgentBench是一個非凡的新基準測試工具,專門用于評估語言學習模型(LLM)的性能和準確性。這種以人工智能為重點的工具為技術行業帶來了

part09)

















