HBase 簡介和安裝
請參考文章:HBase 一文讀懂
Python3 HBase API
HBase 前期準備
1 安裝happybase庫操作hbase
安裝該庫 pip install happybase2 確保 Hadoop 和 Zookeeper 可用并開啟
確保Hadoop 正常運行
確保Zookeeper 正常運行3 開啟HBase thrift服務
使用命令開啟
$HBASE_HOME/bin/hbase-daemon.sh start thrift4、使用jps 命令查看thrift 服務 是否正常啟動
[root@Hadoop3-master bin]# jps
69760 Worker
120160 ResourceManager
81811 QuorumPeerMain
119541 DataNode
93143 Jps
56695 Worker
119387 NameNode
119802 SecondaryNameNode
92890 ThriftServer
69549 Master
69759 Worker
[root@Hadoop3-master bin]#HappyBase 簡介
Happybase是Python通過Thrift訪問HBase的庫,實現起來方便、快捷。
HappyBase 核心類

Centos 操作指令?
[root@Hadoop3-master bin]# ./zkServer.sh start #啟動 ZooKeeper
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@Hadoop3-master bin]# hbase-daemon.sh start thrift #開啟守護hbase 線程并開啟thrift 服務
running thrift, logging to /usr/local/hbase/logs/hbase-root-thrift-Hadoop3-master.out
[root@Hadoop3-master bin]# jps #hadoop 3 服務/Hbase 服務
69760 Worker
120160 ResourceManager
81811 QuorumPeerMain
119541 DataNode
93143 Jps
56695 Worker
119387 NameNode
119802 SecondaryNameNode
92890 ThriftServer
69549 Master
69759 Worker
[root@Hadoop3-master bin]# ?HBase 偽集群/單機版本遇到問題總結
?ERROR: KeeperErrorCode = NoNode for /hbase/master
造成此類問題的原因是:使用HBase 自帶ZooKeeper 分布式調度框架造成,由于我的環境是單機版本,我的大致設置是使用獨立ZooKeeper 服務。如下是我hbase-site.xml 和hbase-env.sh 相關配置
hbase-env.sh:
export HBASE_MANAGES_ZK=false # 推薦不使用HBash 自帶zookeeper
hbase-site.xml:配置Hadoop 3 存儲地址、ZooKeeper 服務地址和端口
<property><name>hbase.rootdir</name><value>hdfs://Hadoop3-master:9000/hbase</value></property><!--必須設置為True,否則無法連接ZooKeeper--><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- zk 端口 --><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value></property><!-- hbase 依賴 zk的地址 --><property><name>hbase.zookeeper.quorum</name><value>Hadoop3-master</value></property>
Zookeeper:Unable to read additional data from client sessionid 0x00, likely client has closed socket
報錯信息:
EndOfStreamException: Unable to read additional data from client sessionid?0x6362257b44e5068d, likely client has closed socket
具體原因:客戶端連接Zookeeper時,配置的超時時長過短。
解決辦法:調整zoo.cfg 超時參數值
[root@Hadoop3-master conf]# vi /usr/local/zookeeper/conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=10000
?將超時時間由原來的2 秒修改為10 秒
HRegionServer: Failed construction RegionServer
2023-08-16 11:47:22,026 ERROR [main] regionserver.HRegionServer: Failed construction RegionServer
java.lang.StackOverflowErrorat org.apache.zookeeper.ZooKeeper.exists(ZooKeeper.java:2000)
原因:ZooKeeper 存儲HBase 信息異常
解決辦法:使用zkCli.sh 刪除/hbase 節點數據
[root@Hadoop3-master bin]# ./zkCli.sh
Connecting to localhost:2181
******
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[hbase, zookeeper]
[zk: localhost:2181(CONNECTED) 5] deleteall /hbase
[zk: localhost:2181(CONNECTED) 6] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 7] quitWATCHER::WatchedEvent state:Closed type:None path:null
2023-08-16 14:18:58,892 [myid:] - INFO [main:ZooKeeper@1288] - Session: 0x10002e674ad0027 closed
2023-08-16 14:18:58,893 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@568] - EventThread shut down for session: 0x10002e674ad0027
2023-08-16 14:18:58,895 [myid:] - INFO [main:ServiceUtils@45] - Exiting JVM with code 0
Thriftpy2.transport.base.TTransportException: TTransportException(type=1, message="Could not connect to ('*.*.*.*', 9090)")
原因:HBase 沒有啟動thrift 守護進程服務。
解決辦法:開啟HBase thrift 守護進程服務。
[root@Hadoop3-master bin]# ./hbase-daemon.sh start thrift
running thrift, logging to /usr/local/hbase/logs/hbase-root-thrift-Hadoop3-master.out
[root@Hadoop3-master bin]# jps
69760 Worker
128612 QuorumPeerMain
70406 SecondaryNameNode
59081 HRegionServer
69549 Master
70190 DataNode
76078 ThriftServer
56695 Worker
70040 NameNode
70744 ResourceManager
58845 HMaster
69759 Worker
76286 Jps
[root@Hadoop3-master bin]#
通過jsp 指令查看是否包含ThriftServer 標識符?。
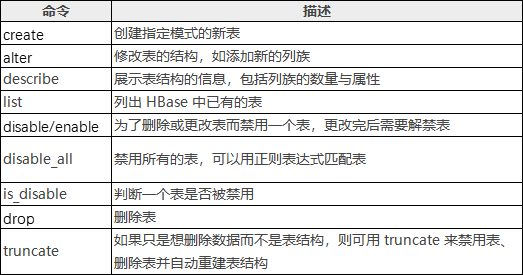
HBase Shell 及其常用命令
?hbase shell是一個命令行工具。在linux上,輸入命令:?. /hbase?shell??
HBase Shell
- version:顯示當前hbase的版本號
- status:顯示各主節點的狀態,之后可以加入參數
- whoami:顯示當前用戶名
- 退出shell模式:exit或quit.
[test@cs010 bin]$ ./hbase shell
//version顯示當前hbase版本號
hbase(main):001:0> version
1.4.12, r6ae4a77408ad35d6a7a4e5cebfd401fc4b72b5ec, Sun Nov 24 13:25:41 CST 2019
//status顯示各主節點的狀態
hbase(main):002:0> status
1 active master, 0 backup masters, 1 servers, 1 dead, 7.0000 average load
//whoami顯示當前用戶名
hbase(main):003:0> whoami
test(auth:SIMPLE)groups: test表和列族操作?
Hbase的表結構(schema)只有表名和列族兩項內容.但列族的屬性很多,在修改和建立表結構時,可以對列族的數量和屬性進行設定.
HBase Shell操作表命令:?
創建表?
//創建表,必須指明兩個參數:表名和列族的名字
1. create 'table1','basic' //建立表名為table1,含有一個列族basic
2. create 'table1','basic','advanced' //建立表名為table1,建立了2個列族basic,advanced.
3. create 'table2','basic',MAX_FILESIZE=>'134217728' //對表中所有列族設定,所有分區單次持久化的最大值為128MB
4. create 'TABLE1','basic' //hbase區分大小寫,與第一個table1是2張不同的表
5. create 'table1',{NAME => 'basic',VERSION => 5,BLOCKCACHE => true}
//大括號內是對列族basic進行描述,定義了VERSION=>5,表示對于同一個cell,保留最近的5個歷史版本,BLOCKCACHE賦值為true,允許讀取數據時進行緩存.其他未指定的參數,采用默認值
//大括號中的語法,NAME和VERSION為參數名,不需要用括號引用.//創建命名空間
create_namespace 'bigdata'//命名空間下創建表
create 'bigdata:student','info'//命名空間下刪除表,如果有表,需要先刪除表drop_namespace 'bigdata'查看表名列表?
//list命令查看當前所有表名
list//list命令查看當前命名空間
list_space//exists 命令查看此表是否存在
exists 'table_test1'eg:
hbase(main):010:0> list
TABLE
table_test1
1 row(s) in 0.0060 secondshbase(main):043:0> list_namespace
NAMESPACE
default
1 row(s) in 0.0190 secondshbase(main):011:0> exists 'table_test1'
Table table_test1 does exist
0 row(s) in 0.0070 seconds描述表結構?
//描述表結構 describe命令查看指定表的列族信息,包括有多少個列族、每個列族的參數信息
describe 'table_test1'//描述命名空間下的表結構describe 'bigdata:table_test1'
eg:
hbase(main):013:0> describe 'table_test1'
Table table_test1 is ENABLED
table_test1
COLUMN FAMILIES DESCRIPTION
{NAME => 'test001', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE =>'65536', REPLICATION_SCOPE => '0'}
{NAME => 'test002', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE =>'65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.0250 seconds修改表結構?
//修改表結構,alter命令,比如增加列族或修改列族參數.
//eg:表table_test1中新增列族test002
1. alter 'table_test1','test001','test002' //新增列族test002
2. alter 'table_test1','test002' //新增列族test002
3. alter 'table_test1','test001',{NAME=> 'test002',IN_MEMORY =>true} //新增列族test002//修改列族名稱,該列族下已存有數據,需要對數據進行修改
4. alter 'table_test1',{NAME=> 'test001',IN_MEMORY =>true}//刪除一個列族,以及其中的數據(前提是至少要有一個列族)
5. alter 'table_test1','delete'=>'test001'
6. alter 'table_test1',{NAME=> 'test002',METHOD=>'delete'}eg:
[haishu@cs010 bin]$ . /hbash shell
hbase(main):001:0> list
TABLE
table_test1
1 row(s) in 0.1710 secondshbase(main):002:0> alter 'table_test1','delete'=>'test001'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.9480 secondshbase(main):003:0> alter 'table_test1',{NAME=>'test002',METHOD=>'delete'}
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.8710 seconds刪除表?
//先禁用表,再刪除表
disable 'table1' //禁用表table1
is_disable 'table1'//查看是否禁用成功
drop 'table1'//刪除表//順序完成禁用、刪除表、刪除所有數據、重新建立空表,即清空表中所有的數據
truncate 'table1'數據更新
HBase Shell 增刪改查命令:

數據插入?
//數據插入,參數依次顯示為:表名、行鍵名稱、列族:列的名稱、單元格的值、時間戳或數據版本號,數值越大表示時間或版本越新,如果省略,默認顯示當前時間戳
put 'table_test','001','basic:test001','micheal jordan',1
put 'table_test','002','basic:test002','kobe'數據更新?
//數據更新,put語句行鍵、列族已存在,但不考慮時間戳。建表時設定VERSIONS=>n,則用戶可以查詢到同一個cell,最新的n個數據版本
put 'table_test','001','basic:test001','air jordan',2數據刪除
HBase 的刪除操作并不會立即將數據從磁盤上刪除,刪除操作主要是對要被刪除的數據打上標記。
當執行刪除操作時,HBase 新插入一條相同的 KeyValue 數據,但是使 keytype=Delete,這便意味著數據被刪除了,直到發生 Major compaction 操作時,數據才會被真正的從磁盤上刪除,刪除標記也會從StoreFile刪除。
//數據刪除,用delete,必須指明表名和列族名稱
delete 'table_test','001','basic'
delete 'table_test','002','basic:test002'
delete 'table_test','002','basic:test002',2
//如果指明了版本,默認刪除的是所有版本<=2的數據
//delete命令的最小粒度是cell,且不能跨列族刪除。//刪除表中所有列族在某個行鍵上的數據,即刪除一個邏輯行,則需要使用deleteall命令
deleteall 'table_test','001'
deleteall 'table_test','002',1
//hbase并不能做實時刪除數據,當hbase刪除數據時,可以看作為這條數據put了新的版本,有一個刪除標記(tombstone)計數器?
//incr命令可以將cell的數值在原值上加入指定數值
incr 'table_test','001','basic:scores',10//get_counter命令可以查看計數器的當前值
get_counter 'table_test','001','basic:scores' 數據查詢?
hbase有2種基本的數據查詢方法:
1.get:按行鍵獲取一條數據
2.scan:掃描一個表,可以指定行鍵范圍或使用過濾器限制范圍。
3.count:采用count指令計算表的邏輯行數
//get命令的必選參數為表名和行鍵名
get 'table_test','001'
//可選項,指明列族名稱、時間戳的范圍、數據版本數、使用過濾器
get 'table_test','001',{COLUMN=>'basic'}
get 'table_test','001',{COLUMN=>'basic',TIMERANGE=>[1,21]}
get 'table_test','001',{COLUMN=>'basic',VERSIONS=>3}
get 'table_test','001',{COLUMN=>'basic',TIMERANG=>[1,2],VERSION=>3}
get 'table_test','001',{FILTER=>"ValueFilter(=,'binary:Michael Jordan 1')"}//scan數據掃描,不指定行鍵,hbase只能通過全表掃描的方式查詢數據
scan 'table_test'
//指定列族名稱
scan 'table_test' ,{COLUMN =>'basic'}
//指定列族和列名
scan 'table_test' ,{COLUMN =>'basic:name'}
//指定輸出行數
scan 'table_test' ,{LIMIT => 1}
//指定行鍵的范圍,中間用逗號隔開
scan 'table_test' ,{LIMIT =>'001',LIMIT => '003'}
//指定時間戳或時間范圍
scan 'table_test' ,{TIMESTAMP => 1}
scan 'table_test' ,{TIMESTAMP => [1,3]}
//使用過濾器
scan 'table_test' ,FILTER=>"RowFilter(=,substring:0')"
//指定對同一個鍵值返回的最多歷史版本數量
scan 'table_test' ,{version=> 1}//采用count指令可以計算表的邏輯行數
count 'table_test' 過濾查詢?
無論是在get方法還是scan方法,均可以使用過濾器(filter)來顯示掃描或輸出的范圍。
//過濾器進行過濾查詢,配合比較運算符或比較器共同使用:>、<、=、>=、<=、!= show_filters
比較器:
- BinaryComparator:完整字節比較器,如:binary:001,表示用字典順序依次比較數據的所有字節。
- BinaryPrefixComparator:前綴字節比較器,如:binaryprefix:001,表示用字典順序依次比較數據的前3個字節。
- RegexStringComparator:正則表達式比較器,如regexstring:a*c,表示字符串'a'開頭,'c'結構的所有字符串。只可以用=或!=兩種運算符。
- SubstringComparator:子字符串比較器,如substring:00.只可以用=或!=兩種運算符。
- BitComparator:比特位比較器。只可以用=或!=兩種運算符。
- NullComparator:空值比較器。
//比較器語法使用,用FILTER=> "過濾器(比較方式)"的方式指明所使用的過濾方法
//在語法格式上,過濾的方法用雙引號引用,而比較方式用小括號引用
scan 'table_test',FILTER=>"RowFilter(=,'substring:0')"
scan 'table_test',{FILTER=>"RowFilter(=,'substring:0')"}
?過濾器的用途:
- 行鍵過濾器
- 列族和列過濾器
- 值過濾器
- 其他過濾器
行鍵過濾器:
//行鍵過濾器,RowFilter:可以配合比較器及運算符,實現行鍵字符串的比較和過濾。
//需求:顯示行鍵前綴為0開頭的鍵值對,進行子串過濾只能用=或!=兩種方式,不支持采用大于或小于
scan 'table_test',FILTER=>"RowFilter(=,'Substring:0')"
scan 'table_test',FILTER=>"RowFilter(>=,'BinaryPrefix:0')"
//行鍵前綴比較器,PrefixFilter:比較行鍵前綴(等值比較)的命令
scan 'table_test',FILTER=>"PrefixFilter('0')"
//KeyOnlyFilter:只對cell的鍵進行過濾和顯示,不顯示值,掃描效率比RowFilter高
scan 'table_test',{FILTER=>"KeyOnlyFilter()"}//FirstKeyFilter:只掃描相同鍵的第一個cell,其鍵值對都會顯示出來,如果有重復的行鍵則跳過。可以用來實現對行鍵(邏輯行)的計數,和其他計數方式相比。
scan 'table_test',{FILTER=>"FirstKeyFilter()"}//InclusiveStopFilter:使用STARTROW和ENDROW進行設定范圍的scan時,結果會包含STARTROW行,但不包括ENDROW,使用該過濾器替代ENDROW條件
scan 'table_test',{STARTROW=>'001',ENDROW=>'002'}
scan 'table_test',{STARTROW=>'001',FILTER=>"InclusiveStopFilter ('binary:002')",ENDROW=>'002'}?列族和列過濾器:
//列族和列過濾器
//列族過濾器:FamilyFilter
scan 'table_test',FILTER=>"FamilyFilter(=,'substring:test001')"
//列名(列標識符)過濾器:QualifierFilter
scan 'table_test',FILTER=>"QualifierFilter(=,'substring:test001')"
//列名前綴過濾器:ColumnPrefixFilter
scan 'table_test',FILTER=>"ColumnPrefixFilter('f')"
//指定多個前綴的ColumnPrefixFilter:MultipleColumnPrefixFilter
scan 'table_test',FILTER=>"MultipleColumnPrefixFilter('f','l')"
//時間戳過濾器:TimestampsFilter
scan 'table_test',{FILTER=>"TimestampsFilter(1,2)"}
//列名范圍過濾器:ColumnRangeFilter
scan 'table_test',{FILTER=>"ColumnRangeFilter('f',false,'lastname',true)"}
//參考列過濾器:DependentColumnFilter,設定一個參考列(即列名),如果某個邏輯行包含該列,則返回該行中和參考列時間戳相同的所有鍵值對
//過濾器參數中,第一項是需要過濾數據的列族名,第二項是參考列名,第三項是false說明掃描包含"basic:firstname",如果是true則說明在basic列族的其他列中進行掃描。
scan 'table_test',{FILTER=>"DependentColumnFilter('basic','firstname',false)"}?值過濾器:
/ValueFilter:值過濾器,get或者scan方法找到符合值條件的鍵值對,變量=值:Michael Jordanget 'table_test','001',{FILTER=>"ValueFilter(=,'binary:Michael Jordan')"} scan 'table_test',{FILTER=>"ValueFilter(=,'binary:Michael Jordan')"}
//SingleColumnValueFilter:在指定的列族和列中進行比較的值過濾器,使用該過濾器時盡量在前面加上一個獨立的列名限定
scan 'table_test',{ COLUMN => 'basic:palyername' , FILTER => "SingleColumnValueExcludeFilter('basic','playername',=,'binary:Micheal Jordan 3')"}
//SingleColumnValueExcludeFilter:和SingleColumnValueFilter類似,但功能正好相反,即排除匹配成功的值
scan 'table_test', FILTER => "SingleColumnValueExcludeFilter( 'basic' , 'playername' ,=,'binary:Micheal Jordan 3')"
SingleColumnValueFilter和SingleColumnValueExcludeFilter區別: Value = "Micheal Jordan "的鍵值對,或者返回除此之外的其他所有鍵值對。
//其他過濾器
1. ColumnCountGetFilter:限制每個邏輯行最多返回多少個鍵值對(cell),一般用get,不用scan.
2. PageFilter:對顯示結果按行進行分頁顯示
3. ColumnPaginationFilter:對顯示結果按列進行分頁顯示
4. 自定義過濾器:hbase允許采用Java編程的方式開發新的過濾器
eg: scan 'table_test', FILTER => "ColumnPrefixFilter( 'first' ) AND ValueFilter(=, 'substring:kobe')"eg:
hbase(main):012:0> get 'Test','002',{FILTER=>"ValueFilter(=,'binary:test004')"}
COLUMN CELL
zhangsan:wendy001 timestamp=1587208488702, value=test004
zhangsan:wendy002 timestamp=1587208582262, value=test004
1 row(s) in 0.0100 secondshbase(main):013:0> scan 'Test',{FILTER=>"ValueFilter(=,'binary:test004')"}
ROW COLUMN+CELL
001 column=zhangsan:wendy001, timestamp=1587208452109, value=test004
002 column=zhangsan:wendy001, timestamp=1587208488702, value=test004
002 column=zhangsan:wendy002, timestamp=1587208582262, value=test004
2 row(s) in 0.0100 secondshbase(main):018:0> scan 'Test',{ COLUMN => 'zhangsan:wendy002' , FILTER => "SingleColumnValueExcludeFilter('zhangsan','wendy002',=,'binary:test004')"}
ROW COLUMN+CELL
0 row(s) in 0.0040 secondshbase(main):019:0> scan 'Test',{COLUMN=>'zhangsan:wendy002',FILTER=>"SingleColumnValueFilter('zhangsan','wendy002',=,'binary:test004')"}
ROW COLUMN+CELL
002 column=zhangsan:wendy002, timestamp=1587208582262, value=test004
1 row(s) in 0.0060 seconds?快照操作
快照:一種不復制數據就能建立表副本的方法,可以用于數據恢復,構建每日、每周或每月的數據報告,并在測試中使用等。
快照前提:Hbase的配置文件hbase-site.xml中配置hbase.snpashot.enabled屬性為true。一般情況下,HBase的默認選項即為true。
//建立表的快照p1
snapshot 'test001','p1'
//顯示快照列表
List_snapshots
//刪除快照
delete_snapshot 'p1'
PS:注意刪除快照后,原表的數據仍然存在。刪除原表,快照的數據也仍然存在。//通過快照生成新表play_1,注意用此種方法生成新表,不會發生數據復制,只會進行元數據操作
clone_snapshot 'p1','play_1'
//快照恢復原表格,將拋棄快照之后的所有變化
restore_snapshot 'p1'//利用快照實現表改名,方法:制作一個快照,再將快照生成為新表,最后將不需要的舊表和快照刪除
snapshot 'player','p1'
clone_snapshot 'p1','play_1'
disable 'player'
drop 'player'
delete_snapshot 'p1'?批量導入導出
場景:put方法用于逐條采集數據,但如果需要將大量數據一次性寫入HBase,則需要進行批量操作。此外,如果需要將數據備份到HDFS等位置,也需要進行批量操作,基于hadoopde的MapReduce方法實現,而數據的導入源頭和備份目的,通常是在HDFS之上。
批量導入數據,有兩種方式:
1、第一種是并行化的數據插入,利用MapReduce等方式將數據發給多個RegionServer。
2、第二種是根據表信息直接將原始數據轉換成HFile,并將數據復制到HDFS的相應位置,再將文件中的數據納入管理。
方法1,利用ImportTsv類方法:將存儲在HDFS上的文本文件導入到HBase的指定表,TXT文件當中應當有明確的列分隔符,比如利用'\t'(TAB鍵)分割的TSV格式,或逗號分割的CSV格式。
原理:執行機制是掃描整個文件,逐條將數據寫入。使用MapReduce方法在多個節點上啟動多個進程,同時讀取多個HDFS上的文件分塊。數據根據所屬分區不同,被發向不同的Regionserver,利用分布式并行讀寫的方式,加快數據導入的速度。
//在linux的命令行通過HBase指令調用ImportTsv類
//player為表名,hdfs://namenode:8020/input/為導入文件所在的目錄,這里不需要指定文件名,導入時會遍歷目錄中的所有文件。
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns= HBASE_ROW_KEY,basic:playername,advance:scores -Dimporttsv.skip.bad.lines =true player hdfs://namenode:8020/input/
//-Dimporttsv.columns=HBASE_ROW_KEY,參數依次為:第一個關鍵字HBASE_ROW_KEY是指定文本文件中的行鍵,第二個是寫入列族basic下名為playername的列,第三個是寫入advance列族下的scores列,這一參數一般為必選項。
//-Dimporttsv.skip.bad.lines=true表示略過無效的行,如果設置為false,則遇到無效行會導入報告失敗 //可選參數
//-Dimporttsv.separator=',',用逗號作為分隔符,也可以指定為其他形式的分隔符,例如'\0',默認情況下分隔符為'\t'。
//-Dimporttsv.timestamp =1298529542218,導入時使用指定的時間戳,如果不指定則采用當前時間。 方法二,利用bulk-load方法:直接將原始數據轉換成HFile,并將數據復制到HDFS的相應位置,再將文件中的數據納入管理,分為2個步驟。
//前提:表結構已經建立好,并且在命令中指定了表名,因為要根據表結構和分區狀況準備文件
//第一步:利用ImportTsv生成文件
//第二步:復制//第一步:利用ImportTsv生成文件
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns= HBASE_ROW_KEY,basic:playername,advance:scores -Dimporttsv.skip.bad.lines =true -Dimporttsv.bulk.output=hdfs://namenode:8020/bulkload/ player hdfs://namenode:8020/input/
//-Dimporttsv.bulk.output 參數,設定了HDFS路徑,準備好HFile文件的存放地址:hdfs://namenode:8020/bulkload/,由于MapReduce的特性,該路徑不能提前存在
//第二步:復制,利用MapReduce實現,參數為HFile文件所在路徑和表名。
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles
hdfs://namenode:8020/bulkload player方法三,從關系型數據庫中導入數據到HBase:Hadoop系列組件中,有名為Sqoop的組件可以實現Hadoop、Hive、HBase等大數據工具與關系型數據庫(例如MySQL、Oracle)之間的數據導入、導出。
Sqoop分為1和2兩個版本,Sqoop1使用較為簡單,Sqoo2則繼承了更多功能,架構也更復雜。
//以sqoop1為例,其安裝過程基本為解壓。
//訪問MySQL等數據庫,則需要自行下載數據庫連接組件(mysql-connector-java-x.jar),并復制到其lib目錄中。
sqoop import --connect jdbc:mysql://node1:3306/database1 --table table1 --hbase-table player --column-family f1 --hbase-row-key playername --hbase-create-table --username 'root' -password '123456'
//從mysql中導入數據(import),之后指明了作為數據源的mysql的訪問地址(node1)、端口(3306)、數據庫名(database1)、表名(table1)。
//數據導入名為player的HBase表,并存入名為f1的列族,列名則和MySQL中保持一致,行鍵為MySQL表中名為playername的列。
//--hbase-create-table :HBase中建立這個表,最后指明了訪問mysql的用戶名和密碼。備份和恢復?
HBase支持將表或快照復制到HDFS,支持將數據復制到其他HBase集群,以實現數據備份和恢復功能。有四種方式:
//Export、Import、ExportSnapshot、CopyTable
//Export:將HBase的數據導出到HDFS。目的;備份,文件并不能直接以文本方式查看。
//參數中<tablename>為表名,<outputdir>為HDFS路徑。
hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir>//Import:導出的數據可以恢復到HBase。
hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <outputdir>//ExportSnapshot
hbase org.apache.hadoop.hbase.mapreduce.ExportSnapshot -snapshot <snapshot name> -copy-to <outputdir>
//snapshot 快照名 ;outputdir為HDFS路徑,導出的快照文件可以利用Import方法恢復到表中。//CopyTable:可以將一個表的內容復制到新表中,新表和原表可以在同一個集群內,也可以在不同的集群上。復制過程利用MapReduce進行。
//前提:新表已經建立起來
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=<NEW_TABLE_NAME> -peer.adr=<zookeeper_peer:2181:/hbase> <TABLE_NAME>
//--new.name=<NEW_TABLE_NAME>參數描述新表的名字,如果不指定則默認和原表名相同。
//-peer.adr=<zookeeper_peer:2181:/hbase>參數指向目標集群Zookeeper服務中的hbase數據入口(包括meta表的地址信息等)//CopyTable幫助
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --helpHappyBase API 實踐
連接HBase
# _*_ coding : UTF-8_*_
# 開發者 : zhuozhiwengang
# 開發時間 : 2023/8/14 22:56
# 文件名稱 : python_hbase_1.py
# 開發工具 : PyCharm
import happybasecon = happybase.Connection('192.168.43.11')
con.open() # 打開傳輸
print(con.tables()) # 輸出所有表名
con.close() # 關閉傳輸效果截圖:

表操作
創建表
# _*_ coding : UTF-8_*_
# 開發者 : zhuozhiwengang
# 開發時間 : 2023/8/16 15:11
# 文件名稱 : python_hbase_2
# 開發工具 : PyCharm
import happybasecon = happybase.Connection('192.168.43.11') # 默認9090端口
con.open() # 打開thrift傳輸,TCP連接families = {'wangzherongyao': dict(max_versions=2), # 設置最大版本為2'hepingjingying': dict(max_versions=1, block_cache_enabled=False),'xiaoxiaole': dict(), # 使用默認值.版本默認為3
}
con.create_table('games', families) # games是表名,families是列簇,列簇使用字典的形式表示,每個列簇要添加配置選項,配置選項也要用字典表示print(con.tables()) # 輸出表
con.close() # 關閉傳輸
配置選項:
- max_versions (int類型)
- compression (str類型)
- in_memory (bool類型)
- bloom_filter_type (str類型)
- bloom_filter_vector_size (int類型)
- bloom_filter_nb_hashes (int類型)
- block_cache_enabled (bool類型)
- time_to_live (int類型)
?啟動或禁用表?
溫馨提示:設置或者刪除表時,必須得先禁用表,再刪除。只能禁用或啟動一次,不能重復,否則報錯。
# _*_ coding : UTF-8_*_
# 開發者 : zhuozhiwengang
# 開發時間 : 2023/8/16 15:15
# 文件名稱 : python_hbase_3
# 開發工具 : PyCharm
# 禁用表
import happybasecon = happybase.Connection('192.168.43.11') # 默認9090端口
con.open() # 打開thrift傳輸,TCP連接con.disable_table('games') # 禁用表,games代表表名
print(con.is_table_enabled('games')) # 查看表的狀態,False代表禁用,True代表啟動
print(con.tables()) # 即使禁用了該表,該表還是存在的,只是狀態改變了con.close() # 關閉傳輸
?效果截圖:

# _*_ coding : UTF-8_*_
# 開發者 : zhuozhiwengang
# 開發時間 : 2023/8/16 15:16
# 文件名稱 : python_hbase_4
# 開發工具 : PyCharm# 啟動表
import happybasecon = happybase.Connection('192.168.43.11') # 默認9090端口
con.open() # 打開thrift傳輸,TCP連接con.enable_table('games') # 啟動該表
print(con.is_table_enabled('games')) # 查看表的狀態,False代表禁用,True代表啟動
print(con.tables()) # 即使禁用了該表,該表還是存在的,只是狀態改變了con.close() # 關閉傳輸
效果截圖:?

刪除表
刪除一個表要先將該表禁用,之后才能刪除。HappyBase 的delete_table函數不但可以禁用表還可以刪除表。如果前面已經禁用了該表,delete_table函數就可以不用加第二個參數,默認為False
# _*_ coding : UTF-8_*_
# 開發者 : zhuozhiwengang
# 開發時間 : 2023/8/16 15:20
# 文件名稱 : python_hbase_5.py
# 開發工具 : PyCharm
import happybasecon = happybase.Connection('192.168.43.11') # 默認9090端口
con.open() # 打開thrift傳輸,TCP連接con.delete_table('games', disable=True) # 第一個參數表名,第二個參數表示是否禁用該表print(con.tables())con.close()?效果截圖:

數據操作?
建立數據
注意:如果寫數據時沒有這個列名,就新建這樣的列名,再寫數據。
在 hbase shell 中,使用put命令,一次只能寫入一個單元格,而happybase庫的put函數能寫入多個。
# _*_ coding : UTF-8_*_
# 開發者 : zhuozhiwengang
# 開發時間 : 2023/8/16 15:24
# 文件名稱 : python_hbase_6.py
# 開發工具 : PyCharmimport happybasecon = happybase.Connection('192.168.43.11') # 默認9090端口
con.open() # 打開傳輸biao = con.table('games') # games是表名,table('games')獲取某一個表對象wangzhe = {'wangzherongyao:名字': '別出大輔助','wangzherongyao:等級': '30','wangzherongyao:段位': '最強王者',
}
biao.put('0001', wangzhe) # 提交數據,0001代表行鍵,寫入的數據要使用字典形式表示# 下面是查看信息,如果不懂可以繼續看下一個
one_row = biao.row('0001') # 獲取一行數據,0001是行鍵
for value in one_row.keys(): # 遍歷字典print(value.decode('utf-8'), one_row[value].decode('utf-8')) # 可能有中文,使用encode轉碼con.close() # 關閉傳輸
效果截圖:

查看操作?
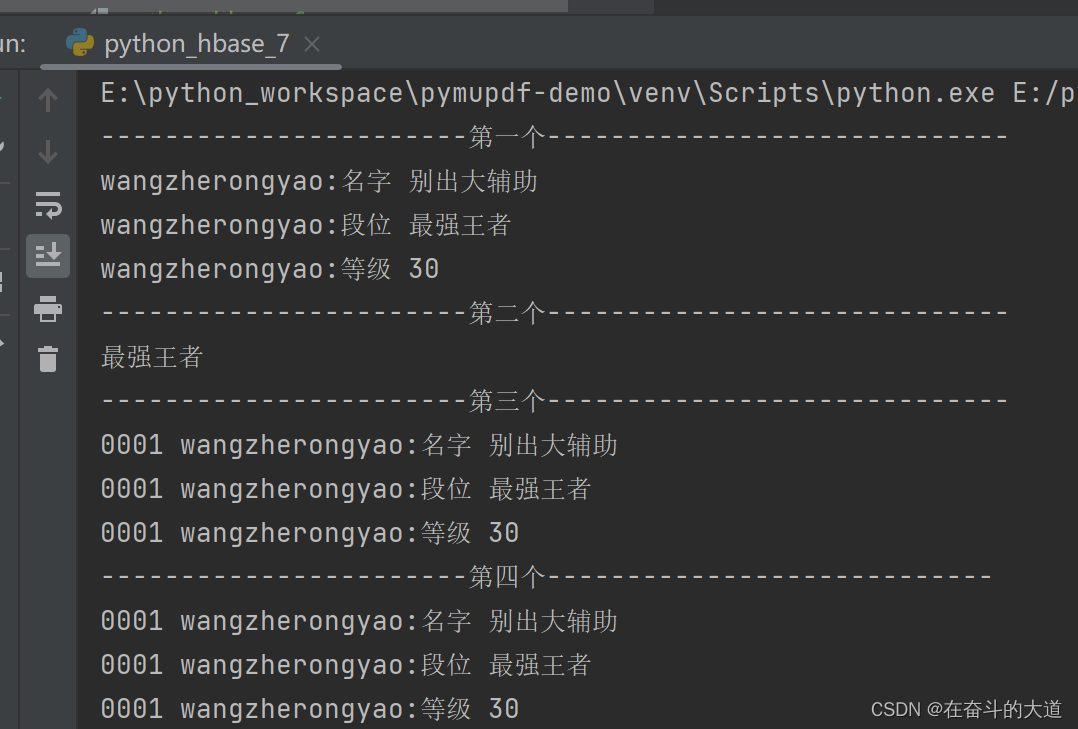
下面連接之后,就創建一個表對象,然后對這個表對象進行操作,這里演示了多種查看操作,第一個是查看一行的數據,第二個是查看一個單元格的數據,因為我存儲時使用了中文,在hbase中存儲的不是中文,而是utf-8的編碼,這里接收了hbase傳過來的編碼數據之后對它進行解碼,第三個是獲取多行的數據,第四個是使用掃描器獲取整個表的數據。
# _*_ coding : UTF-8_*_
# 開發者 : zhuozhiwengang
# 開發時間 : 2023/8/16 15:34
# 文件名稱 : python_hbase_7.py
# 開發工具 : PyCharm
import happybasecon = happybase.Connection('192.168.43.11') # 默認9090端口
con.open() # 打開傳輸biao = con.table('games') # games是表名,table('games')獲取某一個表對象print('-----------------------第一個-----------------------------')
one_row = biao.row('0001') # 獲取一行數據,0001是行鍵
for value in one_row.keys(): # 遍歷字典print(value.decode('utf-8'), one_row[value].decode('utf-8')) # 可能有中文,使用encode內置函數轉碼print('-----------------------第二個-----------------------------')
print(biao.cells('0001', 'wangzherongyao:段位')[0].decode('utf-8')) # 獲取一個單元格信息,返回列表,轉碼輸出,0001是行鍵,wangzherongyao是列簇名,是列名print('-----------------------第三個-----------------------------')
for key, value in biao.rows(['0001', '0002']): # 獲取多行的數據,列表或元組中可以寫入多個行鍵# print(key, '<=====>', value) # 由于0002我沒有寫入數據,就查不到,也不返回信息for index in value.keys(): # 遍歷字典print(key.decode('utf-8'), index.decode('utf-8'), value[index].decode('utf-8')) # 可能有中文,使用encode轉碼print('-----------------------第四個----------------------------')
for rowkey, liecu in biao.scan(): # 獲取掃描器對象,該對象是可迭代對象。掃描器記錄了一個表的結構# print(rowkey, '<=====>', liecu)for index in liecu.keys(): # 遍歷字典print(rowkey.decode('utf-8'), index.decode('utf-8'), liecu[index].decode('utf-8')) # 可能有中文,使用encode轉碼con.close() # 關閉傳輸
效果截圖:
?刪除數據
# _*_ coding : UTF-8_*_
# 開發者 : zhuozhiwengang
# 開發時間 : 2023/8/16 15:38
# 文件名稱 : python_hbase_8.py
# 開發工具 : PyCharmimport happybasecon = happybase.Connection('192.168.43.11') # 默認9090端口
con.open() # 打開傳輸biao = con.table('games') # games是表名,table('games')獲取某一個表對象biao.delete('0003', ['wangzherongyao:段位']) # 刪除一個單元格信息
# biao.delete('0003', ['wangzherongyao:名字', 'wangzherongyao:等級']) # 刪除多個單元個信息
# biao.delete('0003', ['wangzherongyao']) # 刪除一列簇信息
# biao.delete('0003') # 刪除一整行信息# 查看數據,看看是否還在
for rowkey, liecu in biao.scan(): # 獲取掃描器對象,該對象是可迭代對象。掃描器記錄了一個表的結構# print(rowkey, '<=====>', liecu)for index in liecu.keys(): # 遍歷字典print(rowkey.decode('utf-8'), index.decode('utf-8'), liecu[index].decode('utf-8')) # 可能有中文,使用encode轉碼
con.close() # 關閉傳輸前面說過,刪除是根據時間戳來刪除最近的版本,再次查看時顯示的下一個時間戳最近的版本,那么下面測試一下是不是這樣。
# _*_ coding : UTF-8_*_
# 開發者 : zhuozhiwengang
# 開發時間 : 2023/8/16 15:45
# 文件名稱 : python_hbase_9
# 開發工具 : PyCharm
import happybasecon = happybase.Connection('192.168.43.11') # 默認9090端口
con.open() # 打開傳輸biao = con.table('games') # games是表名,table('games')獲取某一個表對象
biao.put('0001', {'wangzherongyao:段位': '最強王者'})
biao.put('0001', {'wangzherongyao:段位': '永恒鉆石V'})
biao.put('0001', {'wangzherongyao:段位': '尊貴鉑金I'}) # 重復寫三個值
print(biao.cells('0001', 'wangzherongyao:段位')) # 查看單元格的數據顯示為最后一個時間戳的版本,即尊貴鉑金Ibiao.delete('0001', ['wangzherongyao:段位']) # 刪除單元格的信息,按照正常的理論查看時顯示永恒鉆石V
print(biao.cells('0001', 'wangzherongyao:段位')) # 查看單元格的信息,顯示為空con.close() # 關閉傳輸問題描述:使用happybase.delete? 刪除指定單元格數據 ,清空了全部指定單元格記錄。按照理論應該刪除最近一條單元格記錄。
原因:happybase庫的 delete 函數封裝的是 hbase shell 中的 deleteall 函數,所以調用要delete函數時要謹慎。
批處理
batch()函數可以創建一個可執行對象,然后在進行批處理操作,其實該函數返回了Batch對象,Batch對象支持上下文管理協議,可以執行批量寫put操作、批量刪delete操作,然后還要使用發送send函數提交到服務器
參考文章:HBase Shell 及其命令操作
? ? ? ? ? ? ? ? ?HappyBase 官方文檔?
)
)
的商品數據如何收集?)
















