內容
科大訊飛AI開發者大賽NLP賽道題目:
基于論文摘要的文本分類與關鍵詞抽取挑戰賽
任務:
1.機器通過對論文摘要等信息的理解,判斷該論文是否屬于醫學領域的文獻。
2.提取出該論文關鍵詞。
數據集的獲取
訓練集:
這里讀取title、abstract、author、keywords拼接在一起作為text,也就是輸入數據。

# 導入pandas用于讀取表格數據
import pandas as pd# 導入BOW(詞袋模型),可以選擇將CountVectorizer替換為TfidfVectorizer(TF-IDF(詞頻-逆文檔頻率)),注意上下文要同時修改,親測后者效果更佳
from sklearn.feature_extraction.text import CountVectorizer# 導入LogisticRegression回歸模型
from sklearn.linear_model import LogisticRegression# 過濾警告消息
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)# 讀取數據集
train = pd.read_csv('/home/aistudio/data/data231041/train.csv')
train['title'] = train['title'].fillna('')
train['abstract'] = train['abstract'].fillna('')test = pd.read_csv('/home/aistudio/data/data231041/testB.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')# 提取文本特征,生成訓練集與測試集
train['text'] = train['title'].fillna('') + ' ' + train['author'].fillna('') + ' ' + train['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
test['text'] = test['title'].fillna('') + ' ' + test['author'].fillna('') + ' ' + test['abstract'].fillna('')
特征工程
這里將對應的文本token轉化為vector,方便后面進行計算,這里的CountVectorizer()使用的是BOW模型,所以編碼后的維度應該是詞表的大小。
vector = CountVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])
其中,train[‘text’]的shape是[6000,]
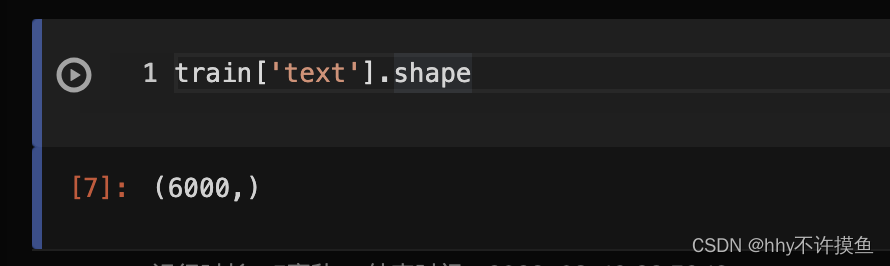
所以對應的train_vector的shape就是(6000, 67855)
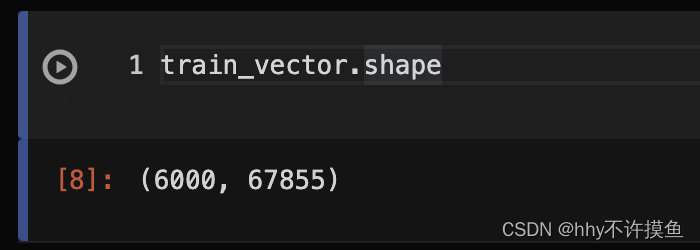
test_vector是(2000, 67855)
訓練
這里使用的是邏輯回歸的方法。本質上是在線性層上堆疊了一個非線性layer,sigmoid將最終結果scale到0-1之間,方便我們進行二分類任務。
# 引入模型
model = LogisticRegression()# 開始訓練,這里可以考慮修改默認的batch_size與epoch來取得更好的效果
model.fit(train_vector, train['label'])
驗證
用測試集進行驗證。
# 利用模型對測試集label標簽進行預測
test['label'] = model.predict(test_vector)
test['Keywords'] = test['title'].fillna('')
test[['uuid','Keywords','label']].to_csv('submit_task1.csv', index=None)
提交結果,分數如下。

改進
當然這還沒完,之前的CountVectorizer()是基于BOW模型的。我們也可以基于 TF-IDF 進行提取。
TF 指 term frequence,即詞頻,指某個詞在文章中出現次數與文章總次數的比值;
IDF 指 inverse document frequence,即逆文檔頻率,指包含某個詞的文檔數占語料庫總文檔數的比例
每個詞最終的 IF-IDF 即為 TF 值乘以 IDF 值。計算出每個詞的 TF-IDF 值后,使用 TF-IDF 計算得到的數值向量替代原文本即可實現基于 TF-IDF 的文本特征提取。
from sklearn.feature_extraction.text import TfidfVectorizer
vector = TfidfVectorizer().fit(train["text"])
# vector = CountVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])
結果也會有顯而易見的提高。




)




鏈路追蹤zipkin)



的基本原理(一))



)
)

