本章重點
一、鏈表的分類

實際中鏈表的結構非常多樣,以下情況組合起來就有8種鏈表結構:
1. 單向或者雙向

2. 帶頭或者不帶頭
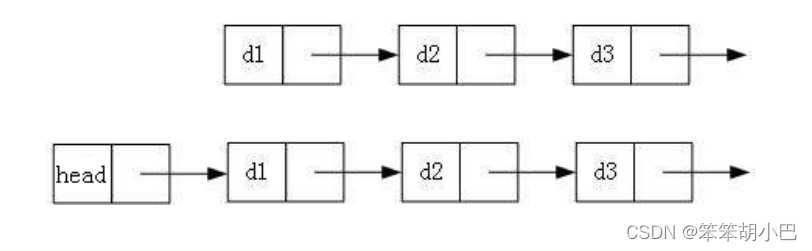 3. 循環或者非循環?
3. 循環或者非循環?

雖然有這么多的鏈表的結構,但是我們實際中最常用還是兩種結構:
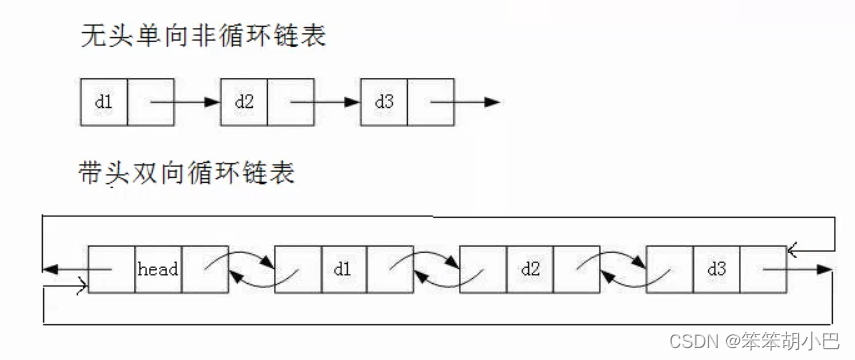
- 無頭單向非循環鏈表:結構簡單,一般不會單獨用來存數據。實際中更多是作為其他數據結構的子結構,如哈希桶、圖的鄰接表等等。另外這種結構在筆試面試中出現很多。
- 帶頭雙向循環鏈表:結構最復雜,一般用在單獨存儲數據。實際中使用的鏈表數據結構,都 是帶頭雙向循環鏈表。另外這個結構雖然結構復雜,但是使用代碼實現以后會發現結構會帶 來很多優勢,實現反而簡單了,后面我們代碼實現了就知道了。

二、帶頭雙向循環鏈表接口實現
1.申請結點:struct ListNode* BuyLTNode(LTDataType x)
動態申請結點,函數返回的是一個指針類型,用malloc開辟一個LTNode大小的空間,并用node指向這個空間,再判斷是否為空,如為空就perror,顯示錯誤信息。反之則把要存的數據x存到newnode指向的空間里面,把指針置為空。
// 申請結點
struct ListNode* BuyLTNode(LTDataType x)
{struct ListNode* node = (struct ListNode*)malloc(sizeof(struct ListNode));if (node == NULL){perror("malloc fail");exit(-1);}node->data = x;node->prev = node;node->next = node;return node;
}
2.初始化:struct ListNode* LTInit()
// 初始化
void LTInit(struct ListNode* phead)
{phead = BuyLTNode(-1);phead->prev = phead;phead->next = phead;
}
我們首先看看這個初始化有什么問題嘛?

phead為空指針,說明我們的初始化沒有效果,這是因為phead是函數里面的形參,出了作用域就銷毀,plsit仍然是空指針,形參的改變不能影響實參,但是我們可以通過返回phead的地址解決問題。
單鏈表開始是沒有節點的,可以定義一個指向空指針的結點指針,但是此鏈表不同,需要在初始化函數中創建個頭結點,它不用存儲有效數據。因為鏈表是循環的,在最開始需要讓頭結點的next和pre指向頭結點自己。
因為其他函數也不需要用二級指針(因為頭結點指針是不會變的,變的是next和pre,改變的是結構體,只需要用結構體針即可,也就是一級指針)為了保持一致此函數也不用二級指針,把返回類型設置為結構體指針類型。
// 初始化 - 改變實參plsit
struct ListNode* LTInit()
{struct ListNode* phead = BuyLTNode(-1);phead->prev = phead;phead->next = phead;return phead;
}3.尾插:void LTPushBack(struct ListNode* phead, LTDataType x)
尾插首先要找到尾結點,再將要尾插的結點與尾結點和帶頭結點鏈接,由于是帶頭結點,所以此處不需要關注頭結點為空的問題。
// 尾插
void LTPushBack(struct ListNode* phead, LTDataType x)
{assert(phead);struct ListNode* tail = phead->prev;struct ListNode* newnode = BuyLTNode(x);newnode->prev = tail;tail->next = newnode;newnode->next = phead;phead->prev = newnode;}
4.尾刪:void LTPopBack(struct ListNode* phead)
尾刪只需要找到尾結點的前驅結點,再把帶頭結點和前驅結點鏈接,釋放尾結點就完成了尾刪。
不過這里需要處理一下只有帶頭結點的刪除,此時真正的鏈表為空,此時就不能刪除了。
// 尾刪
void LTPopBack(struct ListNode* phead)
{assert(phead);assert(phead->next != phead);//鏈表為空struct ListNode* tail = phead->prev;struct ListNode* tailPrev = tail->prev;free(tail);tailPrev->next = phead;phead->next = tailPrev;}
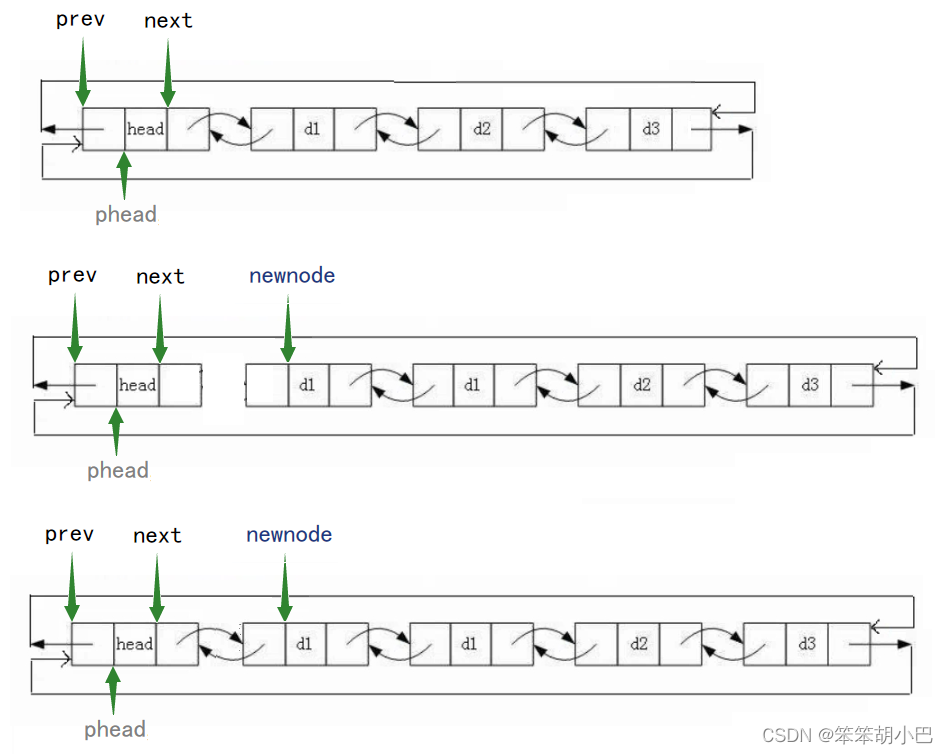
5.頭插:void LTPushFront(struct ListNode* phead, LTDataType x)
頭插需要注意順序,如果先讓phead和newnode鏈接,那么就找不到phead結點的后續結點,這樣就無法讓newnode和phead結點的后續結點鏈接。
// 頭插
void LTPushFront(struct ListNode* phead, LTDataType x)
{assert(phead);struct ListNode* newnode = BuyLTNode(x);//順序不可顛倒newnode->next = phead->next;phead->next->prev = newnode;phead->next = newnode;newnode->prev = phead;
}
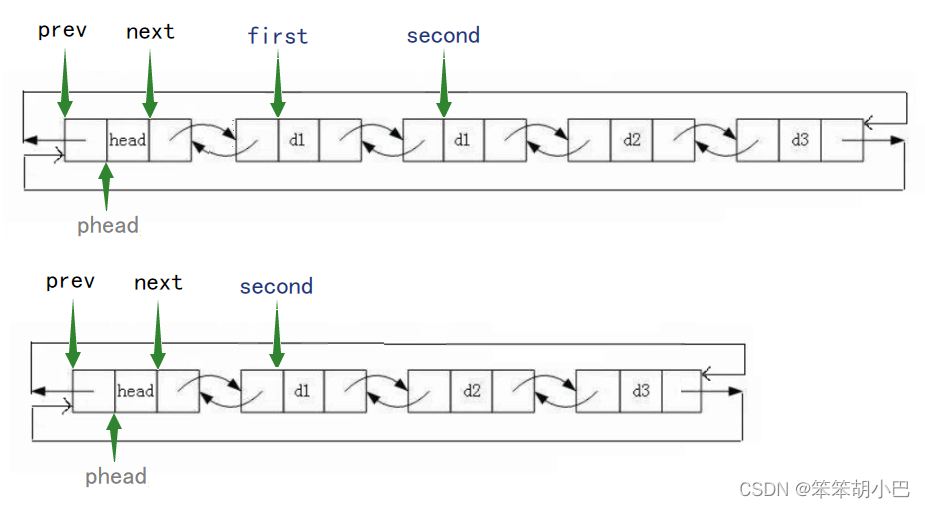
6.頭刪:void LTPopFront(struct ListNode* phead)
// 頭刪
void LTPopFront(struct ListNode* phead)
{assert(phead);assert(phead->next != phead);//鏈表為空struct ListNode* first = phead->next;struct ListNode* second = first->next;free(first);phead->next = second;second->prev = phead;
}
7.鏈表長度:int LTSize(struct ListNode* phead)
????????求鏈表長度,先把頭結點下一個結點存到cur中,再用while循環遍歷終止條件是cur等于頭結點,用size++記錄長度,并更新cur,最后返回size,32位機器下是無符號整型size_t。
( 此類型可以提高代碼的可移植性,有效性,可讀性。此鏈表長度可能是字符型或者數組整型,他可以提供一種可移植方法來聲明與系統中可尋址的內存區域一致的長度,而且被設計的足夠大,能表示內存中任意對象的大小)
????????注意這里求鏈表長度不需要求帶頭結點,我們有時也經常看到由于帶頭結點的數據沒有使用,就有的書上會把該數據存儲上鏈表的長度size=phead->data,然后插入數據phead->data++,刪除phead->--,但是這有個限制,這種寫法只適合int類型,如果我們寫出char類型的數據,存儲幾個數據char就保存不了,char類型的phead->data一直++最后就會溢出,所以不建議這種寫法。
// 鏈表長度
int LTSize(struct ListNode* phead)
{assert(phead);int size = 0;struct ListNode* cur = phead->next;while (cur != phead){size++;cur = cur->next;}return size;
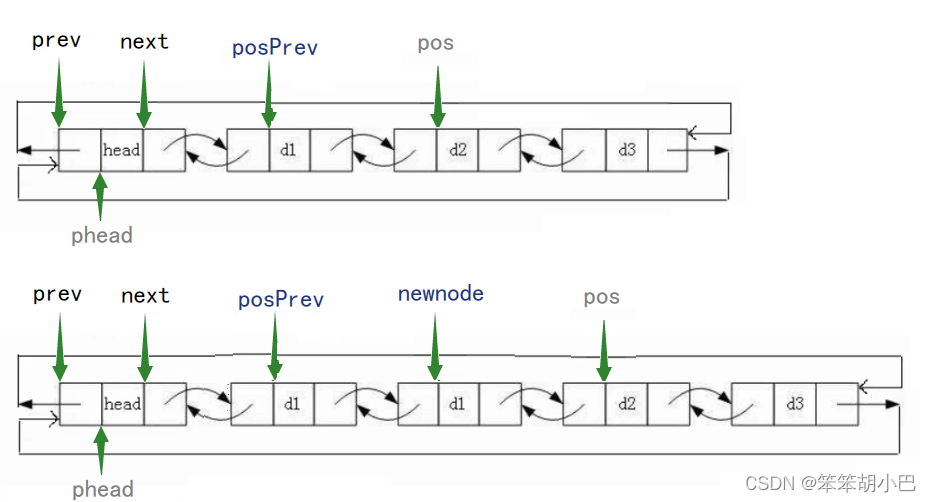
}8.在pos的前面進行插入:void LTInsert(struct ListNode* pos, LTDataType x)
斷言pos,不能為空,插入數據先申請一結點放到定義的newnode指針變量中,為了不用考慮插入順序,先把pos前面的存到posPrev中,然后就可以隨意鏈接:
posPrev指向新節點,新節點前驅指針指向posPrev,新節點指向pos,pos前驅指針指向新節點。
// 在pos的前面進行插入
void LTInsert(struct ListNode* pos, LTDataType x)
{assert(pos);struct ListNode* posPrev = pos->prev;struct ListNode* newnode = BuyLTNode(x);posPrev->next = newnode;newnode->prev = posPrev;newnode->next = pos;pos->prev = newnode;
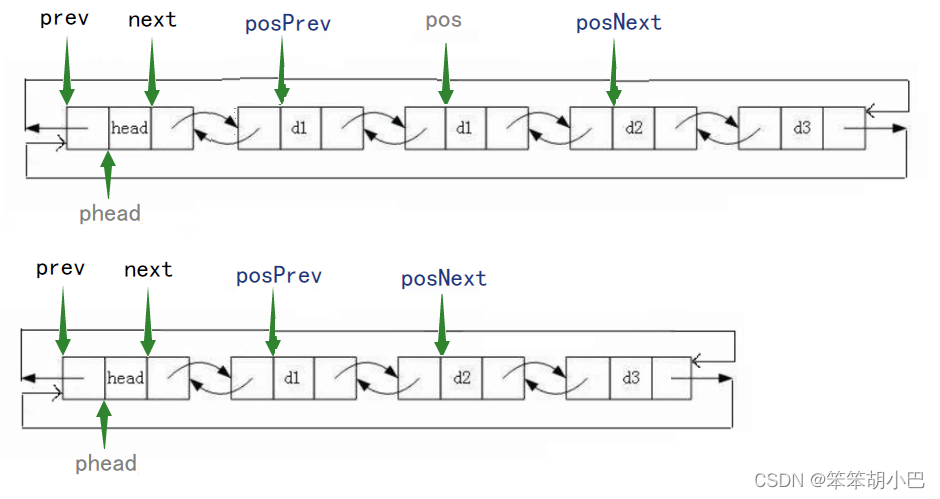
} 9.刪除pos位置的結點:void LTErase(struct ListNode* pos)
9.刪除pos位置的結點:void LTErase(struct ListNode* pos)
刪除把pos位置之前的結點直接指向pos的下一個結點,把pos下一個結點的前驅指針指向pos之前的結點。
// 刪除pos位置的結點
void LTErase(struct ListNode* pos)
{assert(pos);struct ListNode* posPrev = pos->prev;struct ListNode* posNext = pos->next;free(pos);posPrev->next = posNext;posNext->prev = posPrev;
}?
10.雙向鏈表查找:struct ListNode* ListFind(struct ListNode* phead, LTDataType x)
查找把頭結點下一個結點存到cur,然后用while循環遍歷,終止條件是cur等于頭結點指針,如果cur等于x,直接返回cur指針,再更新cur,最后遍歷完返回NULL,表示沒有該數據。
// 雙向鏈表查找
struct ListNode* ListFind(struct ListNode* phead, LTDataType x)
{assert(phead);struct ListNode* cur = phead->next;while (cur != phead){if (cur->data == x)return cur;cur = cur->next;}return NULL;
}11.銷毀:void LTDestroy(struct ListNode* phead)
釋放鏈表從頭開始釋放,把頭結點下一個結點存到cur中,再用用while循環,終止條件是cur不等于頭指針,在里面把cur下一個指針存到next中,釋放掉cur,再把next更新為cur。最后頭結點也是申請的,也得釋放。
這里需要注意,由于形參的改變不會影響實參,我們在函數內部將phead置空是無意義的,我們需要在函數外面調用LTDestroy函數后,需要手動將phead置空。
// 銷毀
void LTDestroy(struct ListNode* phead)
{assert(phead);struct ListNode* cur = phead->next;while (cur != phead){struct ListNode* next = cur->next;free(cur);cur = next;}free(phead);
}12.打印:void LTPrint(struct ListNode* phead)
打印鏈表,先斷言phead,它不能為空,再把頭結點下個地址存到cur中,用while循環去遍歷,終止條件是等于頭指針停止,因為他是循環的,并更新cur。
// 打印
void LTPrint(struct ListNode* phead)
{assert(phead);printf("phead<=>");struct ListNode* cur = phead->next;while (cur != phead){printf("%d<=>", cur->data);cur = cur->next;}
}三、順序表和鏈表的區別

| 不同點 | 順序表 | 鏈表 |
| 存儲空間上 | 物理上一定連續 | 邏輯上連續,但物理上不一定 連續 |
| 隨機訪問 | 支持O(1) | 不支持:O(N) |
| 任意位置插入或者刪除 元素 | 可能需要搬移元素,效率低 O(N) | 只需修改指針指向 |
| 插入 | 動態順序表,空間不夠時需要 擴容 | 沒有容量的概念 |
| 應用場景 | 元素高效存儲+頻繁訪問 | 任意位置插入和刪除頻繁 |
| 緩存利用率 | 高 | 低 |
四、緩存利用率參考存儲體系結構 以及 局部原理性。
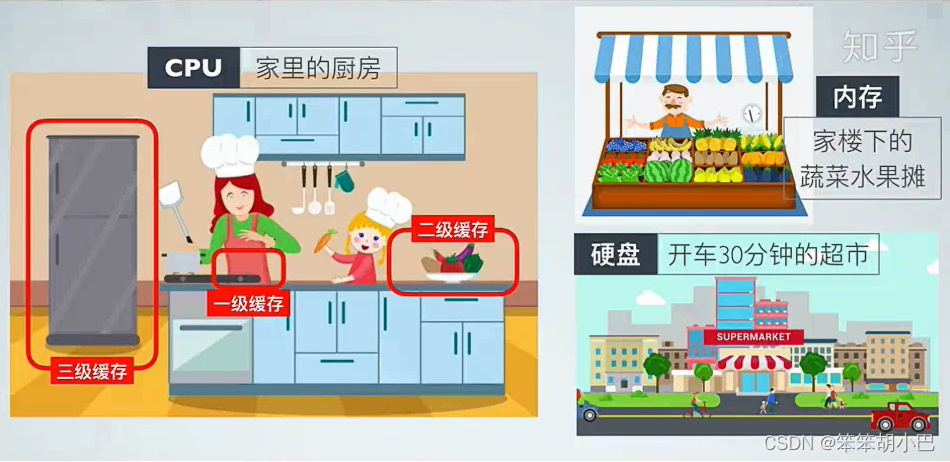
1.存儲體系結構

寄存器(Registers):寄存器是CPU內部的最快速存儲,用于存儲最常用的數據和指令。它們在執行指令時起著重要作用,速度非常快。
高速緩存(Cache):高速緩存是位于中央處理器(CPU)和主存儲器之間的一層快速存儲,用于臨時存放經常訪問的數據和指令。它可以分為多個層次,如L1、L2和L3緩存,隨著級別的升高,容量逐漸增大,但速度逐漸降低。
主存儲器(Main Memory):也稱為RAM(Random Access Memory),主存儲器是計算機中用于存放運行中程序和數據的地方。它是CPU能夠直接訪問的存儲設備,速度比較快,但容量通常相對有限。
輔助存儲器(Secondary Storage):這包括各種長期存儲設備,如硬盤驅動器、固態硬盤、光盤、磁帶等。這些設備的容量通常很大,但速度較慢,用于持久性存儲和備份。
虛擬內存(Virtual Memory):虛擬內存是一種在主存和輔助存儲之間創建的抽象層,允許程序使用比主存更大的地址空間。操作系統可以根據需要將數據從主存移到輔助存儲,以優化內存使用。
2.局部性原理
????????存儲體系結構的局部性原理是指在計算機程序執行過程中,訪問內存的模式往往呈現出一定的規律性,即數據和指令的訪問并不是完全隨機的,而是傾向于集中在某些特定的內存區域或者特定的數據塊上。這個原理分為兩種類型:時間局部性和空間局部性。
時間局部性(Temporal Locality):時間局部性指的是一個被訪問過的內存位置在未來的一段時間內很可能會再次被訪問。這意味著程序在不久的將來可能會多次使用相同的數據或指令。時間局部性的實現依賴于高速緩存,因為緩存可以暫時存儲最近使用過的數據,從而在未來的訪問中加速存取。
空間局部性(Spatial Locality):空間局部性指的是在訪問某個內存位置時,附近的內存位置也很可能會被訪問。這種情況在程序中存在連續存儲、數組訪問等情況下特別明顯。空間局部性的實現同樣依賴于高速緩存,因為緩存可以在一個較小的區域內存儲多個相鄰的數據塊。
????????局部性原理對計算機性能具有重要意義。通過充分利用局部性,計算機系統可以更有效地使用高速緩存,減少主存訪問次數,從而提高數據訪問的速度和效率。這對于減少存儲層次之間的數據傳輸時間以及提高程序的整體性能至關重要。
????????舉例來說,如果一個循環中多次使用相同的數組元素,由于時間局部性,這些數組元素會被緩存在高速緩存中,從而避免了多次訪問主存。同樣,如果一個算法中需要順序訪問數組的各個元素,由于空間局部性,緩存中可能會存儲這些相鄰的數據塊,從而加速了后續的訪問。
3.為什么順序表的效率比鏈表效率高
順序表:順序表是一種將元素順序存儲在一塊連續的內存區域中的數據結構。由于順序表的元素在內存中是相鄰存儲的,因此它充分利用了空間局部性。當訪問一個元素時,由于它的相鄰元素也在內存中,這些相鄰元素很可能也會被加載到高速緩存中,從而減少了主存訪問的次數。此外,由于順序表的元素是連續存儲的,通過數組索引可以直接計算出元素的地址,避免了鏈表節點的跳轉操作。
鏈表:鏈表是一種通過節點和指針連接元素的數據結構,它的元素在內存中不一定是連續存儲的。在鏈表中,每個節點都包含了數據以及指向下一個節點的指針。這種非連續的存儲方式可能導致空間局部性較差,因為在訪問一個節點時,并不保證它的相鄰節點會被加載到高速緩存中。這會導致更頻繁的主存訪問,從而降低了效率。
????????綜上所述,順序表相比鏈表具有更好的空間局部性。它的元素連續存儲,使得訪問一個元素時,附近的元素也可能在緩存中,從而減少了主存訪問的需求,提高了數據訪問的速度和效率。而鏈表的節點之間不一定相鄰存儲,導致空間局部性不如順序表,因此鏈表在訪問數據時可能需要更多的主存訪問操作,從而效率相對較低。
????????需要注意的是,對于插入、刪除等操作,鏈表在某些情況下可能更加靈活,因為它們不需要移動大量的數據,而順序表在插入、刪除操作時可能需要進行元素的移動,可能會帶來一些開銷。所以,在選擇使用順序表還是鏈表時,需要根據具體的應用場景和操作需求綜合考慮。
本章結束啦!!!




















】對Linux權限的理解)