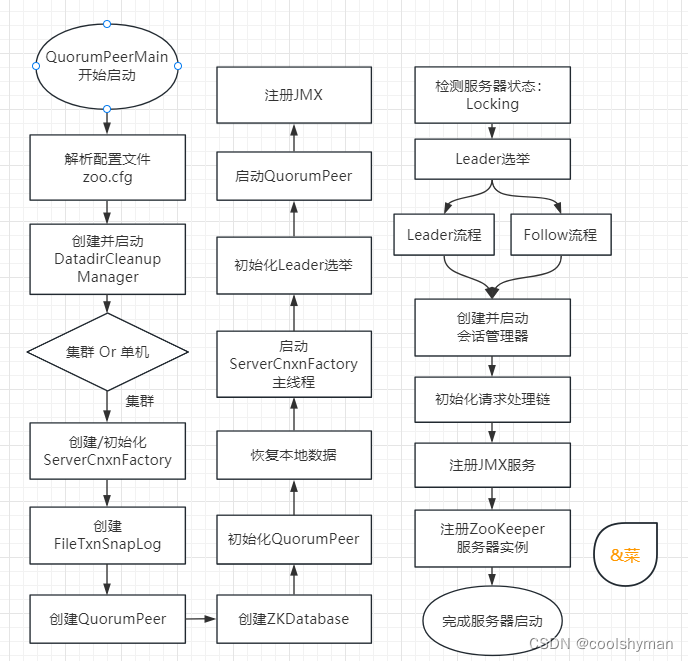
在本文中,我們將對集群版ZooKeeper服務器的啟動過程做詳細講解。集群和單機ZooKeeper服務器的啟動過程在很多地方都是一致的,因此本節只會對有差異的地方展開進行講解。下圖所示是集群版ZooKeeper服務器的啟動流程圖。
?
預啟動
預啟動的步驟如下。
(1)統一由QuorumPeerMain作為啟動類。
(2)解析配置文件zoo.cfg。
(3)創建并啟動歷史文件清理器DatadirCleanupManager。
(4)判斷當前是集群模式還是單機模式的啟動。
在集群模式中,由于已經在zoo.cfg中配置了多個服務器地址,因此此處選擇集群模式啟動ZooKeeper。
初始化
初始化的步驟如下。
(1)創建ServerCnxnFactory。
(2)初始化ServerCnxnFactory。
(3)創建ZooKeeper數據管理器FileTxnSnapLog。
(4)創建QuorumPeer實例。
Quorum是集群模式下特有的對象,是ZooKeeper服務器實例(ZooKeeperServer)的托管者,從集群層面看,QuorumPeer代表了ZooKeeper集群中的一臺機器。在運行期間,QuorumPeer會不斷檢測當前服務器實例的運行狀態,同時根據情況發起Leader選舉。
(5)創建內存數據庫ZKDatabase。
ZKDatabase是ZooKeeper的內存數據庫,負責管理ZooKeeper的所有會話記錄以及DataTree和事務日志的存儲。
(6)初始化QuorumPeer。
在步驟5中我們已經提到,QuorumPeer是ZooKeeperServer的托管者,因此需要將一些核心組件注冊到QuorumPeer中去,包括FileTxnSnapLog、ServerCnxnFactory和ZKDatabase。同時ZooKeeper還會對QuorumPeer配置一些參數,包括服務器地址列表、Leader選舉算法和會話超時時間限制等。
(7)恢復本地數據。
(8)啟動ServerCnxnFactory主線程。
Leader選舉
Leader選舉的步驟如下。
(1)初始化Leader選舉。
Leader選舉可以說是集群和單機模式啟動ZooKeeper最大的不同點。ZooKeeper首先會根據自身的SID (服務器ID)、lastLoggedZxid (最新的ZXID)和當前的服務器epoch(currentEpoch)來生成一個初始化的投票一簡單地講,在初始化過程中,每個服務器都會給自己投票。
然后,ZooKeeper會根據zoo.cfg中的配置,創建相應的Leader選舉算法實現。在ZooKeeper中,默認提供了三種Leader選舉算法的實現,分別是LeaderElection、AuthFastLeaderElection和FastLeaderElection,可以通過在配置文件(zoo.cfg)中使用electionAlg屬性來指定,分別使用數字0~3來表示。從3.4.0版本開始,ZooKeeper廢棄了前兩種Leader選舉算法,只支持FastLeaderElection選舉算法了。
在初始化階段,ZooKeeper會首先創建Leader選舉所需的網絡I/O層QuorumCnxManager,
同時啟動對Leader選舉端口的監聽,等待集群中其他服務器創建連接。
(2)注冊JMX服務。
(3)檢測當前服務器狀態。
在上文中,我們已經提到QuorumPeer是ZooKeeper服務器實例的托管者,在運行期間,QuorumPeer的核心工作就是不斷地檢測當前服務器的狀態,并做出相應的處理。在正常情況下,ZooKeeper 服務器的狀態在LOOKING、LEADING和FOLLOWING/OBSERVING之間進行切換。而在啟動階段,QuorumPeer的初始狀態是LOOKING,因此開始進行Leader選舉。
(4)Leader選舉:
ZooKeeper的Leader選舉過程,簡單地講,就是一個集群中所有的機器相互之間進行一系列投票,選舉產生最合適的機器成為Leader,同時其余機器成為Follower或是Observer的集群機器角色初始化過程。關于Leader選舉算法,簡而言之,就是集群中哪個機器處理的數據越新(通常我們根據每個服務器處理過的最大ZXID來比較確定其數據是否更新),其越有可能成為Leader。當然,如果集群中的所有機器處理的ZXID一致的話,那么SID最大的服務器成為Leader。
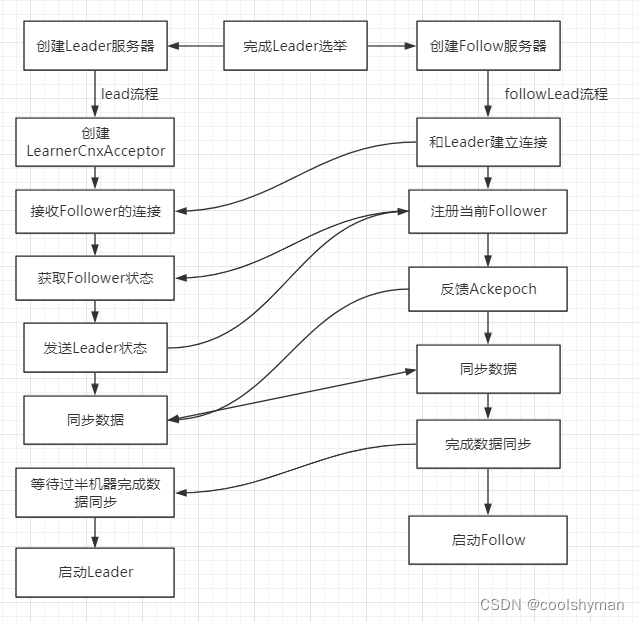
Leader和Follower啟動期交互過程
到這里為止,ZooKeeper已經完成了Leader選舉,并且集群中每個服務器都已經確定了自己的角色一通常情況下就分為Leader 和Follower兩種角色。下面我們來對Leader和Follower在啟動期間的工作原理進行講解,其大致交互流程如下圖所示。
?
Leader和Follower服務器啟動期交互過程包括如下步驟。
(1)創建Leader服務器和Follower服務器。
完成Leader選舉之后,每個服務器都會根據自己的服務器角色創建相應的服務器實例,并開始進入各自角色的主流程。
(2)Leader服務器啟動Follower接收器LearnerCnxAcceptor。
在ZooKeeper集群運行期間,Leader 服務器需要和所有其余的服務器(本文余下部分,我們使用“Learner”來指代這類機器)保持連接以確定集群的機器存活情況。LearnerCnxAcceptor接收器用于負責接收所有非Leader服務器的連接請求。
(3)Learner服務器開始和Leader建立連接。
所有的Learner服務器在啟動完畢后,會從Leader選舉的投票結果中找到當前集群中的Leader服務器,然后與其建立連接。
(4)Leader服務器創建LearnerHandler。
Leader接收到來自其他機器的連接創建請求后,會創建一個LearnerHandler實例。每個LearnerHandler實例都對應了一個Leader與Learner服務器之間的連接,其負責Leader和Learner服務器之間幾乎所有的消息通信和數據同步。
(5)向Leader注冊。
當和Leader建立起連接后,Learner就會開始向Leader進行注冊一所謂的注冊,其實就是將Learner 服務器自己的基本信息發送給Leader 服務器,我們稱之為LearnerInfo,包括當前服務器的SID和服務器處理的最新的ZXID。
(6)Leader解析Learner信息,計算新的epoch。
Leader服務器在接收到Learner的基本信息后,會解析出該Learner的SID和ZXID,然后根據該Learner的ZXID解析出其對應的epoch_of_learner,和當前Leader服務器的epoch_of_leader進行比較,如果該Learner的epoch_of_learner更大的話,那么就更新Leader的epoch:
epoch_of_leader = epoch_of_learner + 1
然后,LearnerHandler會進行等待,直到過半的Learner已經向Leader 進行了注冊,同時更新了epoch_of_leader之后,Leader就可以確定當前集群的epoch了。
(7)發送Leader狀態。
計算出新的epoch之后,Leader會將該信息以一個LEADERINFO消息的形式發送給Learner,同時等待Learner的響應。
(8)Learner發送ACK消息。
Follower在收到來自Leader的LEADERINFO消息后,會解析出epoch和ZXID,然后向Leader反饋一個ACKEPOCH響應。
(9)數據同步。
Leader服務器接收到Learner的這個ACK消息后,就可以開始與其進行數據同步了。
(10)啟動Leader和Learner服務器。
當有過半的Learner已經完成了數據同步,那么Leader和Learner服務器實例就可以開始啟動了。
Leader和Follower啟動
Leader和Follower啟動的步驟如下。
(1)創建并啟動會話管理器。
(2)初始化ZooKeeper的請求處理鏈。
和單機版服務器一樣,集群模式下,每個服務器都會在啟動階段串聯請求處理鏈,只是根據服務器角色不同,會有不同的請求處理鏈路。
(3)注冊JMX服務。
至此,集群ZooKeeper服務器啟動完畢。






)
)
)


—模型選擇與調優》)




_網絡編程與打包發布)

![[保研/考研機試] KY43 全排列 北京大學復試上機題 C++實現](http://pic.xiahunao.cn/[保研/考研機試] KY43 全排列 北京大學復試上機題 C++實現)
