什么是回歸
????????回歸樹,隨機森林的回歸,無一例外他們都是區別于分類算法們,用來處理和預測連續型標簽的算法。然而邏輯回歸,是一種名為“回歸”的線性分類器,其本質是由線性回歸變化而來的,一種廣泛使用于分類問題中的廣義回歸算法。要理解邏輯回歸從何而來,得要先理解線性回歸。線 性回歸是機器學習中最簡單的的回歸算法,它寫作一個幾乎人人熟悉的方程:
![]()
?????????0為截距,?1~?n為系數;
如上方程,構建成矩陣如下,現在的目標就是構建?T的值。

????????于是,我們就可以得到一個觀點,即:線性回歸的任務,就是構造一個預測函數來映射輸入的特征矩陣x和標簽值y的線性關系,而構造預測函數的核心就是找出模型的參數:?T和?0;
????????通過函數Z?,線性回歸使用輸入的特征矩陣X來輸出一組連續型的標簽值y_pred,以完成各種預測連續型變量的任務,那如果我們的標簽是離散型變量。
? ? ? ? 這是引申了一個概念,連續型變量和離散型變量:?連續性變量是指可以取任何數值的變量,通常以測量或計量方式獲得,例如身高、體重、溫度等。離散型變量是指只能取有限個數值或整數的變量,通常以計數方式獲得,例如家庭成員人數、投擲骰子點數等。
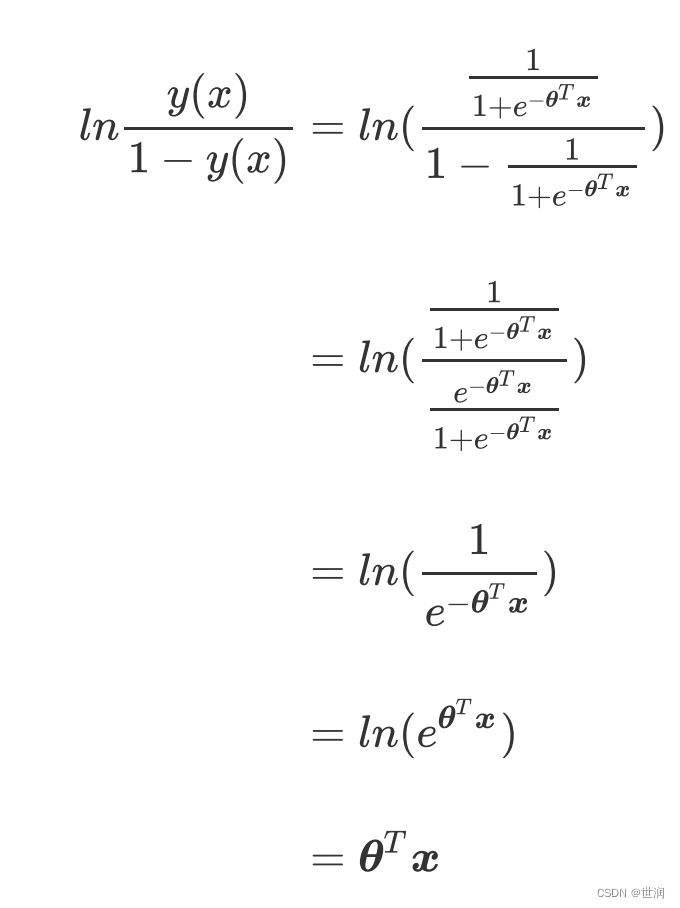
? ? ? ? 這時就會產生一個問題,如果是滿足0-1分布的離散型變量,我們要怎么辦呢?我們可以通過引入聯系函數(link function)。聯系函數即一種將線性預測器轉換為概率的函數。就是將線性回歸方程z變換為g(z),并且令g(z)的值分布在(0,1)之間,且當g(z)接近0時樣本的標簽為類別0,當g(z)接近1時樣本的標簽為類別1,這樣就得到了一個分類模型。而這個聯系函數對于邏輯回歸來說,就是Sigmoid函數:

????????這時又引申了一個概念,即歸一化,歸一化是一種數據預處理技術,用于將不同規模的數據轉換為相同的比例。它通常是將數據縮放到特定的范圍,例如0到1或-1到1之間。歸一化可以消除不同變量之間的量綱影響,使得它們可以在相同的尺度下進行比較和分析。常用的歸一化方法包括MinMaxScaler,而MinMaxScaler是可以取到0和1的(最大值歸一化后就是1,最小值歸一化后就是0),但Sigmoid函數只是無限趨近于0和1。







——CentOS7開機自動執行腳本(以MySQL為例))




)







