Transformer詳解 - mathor

atten之后經過一個全連接層+殘差+層歸一化
class BertSelfOutput(nn.Module):def __init__(self, config):super().__init__()self.dense = nn.Linear(config.hidden_size, config.hidden_size)self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)self.dropout = nn.Dropout(config.hidden_dropout_prob)def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:hidden_states = self.dense(hidden_states) # 全連接 768->768hidden_states = self.dropout(hidden_states)hidden_states = self.LayerNorm(hidden_states + input_tensor) # 殘差和層歸一化return hidden_states殘差的作用:避免梯度消失
歸一化的作用:避免梯度消失和爆炸,加速收斂
然后再送入一個兩層的前饋神經網絡
class BertIntermediate(nn.Module):def __init__(self, config):super().__init__()self.dense = nn.Linear(config.hidden_size, config.intermediate_size)if isinstance(config.hidden_act, str):self.intermediate_act_fn = ACT2FN[config.hidden_act]else:self.intermediate_act_fn = config.hidden_actdef forward(self, hidden_states: torch.Tensor) -> torch.Tensor:hidden_states = self.dense(hidden_states) # [1, 16, 3072] 映射到高維空間:768 -> 3072hidden_states = self.intermediate_act_fn(hidden_states)return hidden_states
class BertOutput(nn.Module):def __init__(self, config):super().__init__()self.dense = nn.Linear(config.intermediate_size, config.hidden_size)self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)self.dropout = nn.Dropout(config.hidden_dropout_prob)def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:hidden_states = self.dense(hidden_states) # 3072 -> 768hidden_states = self.dropout(hidden_states)hidden_states = self.LayerNorm(hidden_states + input_tensor) # 殘差和層歸一化return hidden_states?
面試題:為什么注意力機制中要除以根號dk
答:因為q和k做點積后值會很大,會導致反向傳播時softmax函數的梯度很小。除以根號dk是為了保持點積后的值均值為0,方差為1.(q和k都是向量)
證明:已知q和k相互獨立,且是均值為0,方差為1。
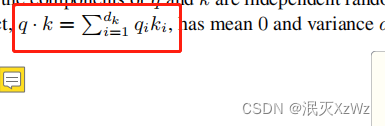
則D(qi*ki)=D(qi)*D(ki)=1
?除以dk則D((qi*ki)/根號dk)=1/dk,每一項是這個值,但是根據上面紅框的公式,一共有dk項求和,值為1
所以(q*k)/dk的方差就等1
?
(背景知識)方差性質:
D(CX)=C^2D(X)? ?,其中C是常量

?
?
?


——CentOS7開機自動執行腳本(以MySQL為例))




)










)
