Rust 的設計靈感來源于很多現存的語言和技術。其中一個顯著的影響就是?函數式編程(functional programming)。函數式編程風格通常包含將函數作為參數值或其他函數的返回值、將函數賦值給變量以供之后執行等等。
更具體的,我們將要涉及:
- 閉包(Closures),一個可以儲存在變量里的類似函數的結構
- 迭代器(Iterators),一種處理元素序列的方式
- 如何使用這些功能來改進第十二章的 I/O 項目。
- 這兩個功能的性能。(劇透警告:?他們的速度超乎你的想象!)
13.1?閉包:可以捕獲環境的匿名函數
Rust 的?閉包(closures)是可以保存進變量或作為參數傳遞給其他函數的匿名函數。可以在一個地方創建閉包,然后在不同的上下文中執行閉包運算。不同于函數,閉包允許捕獲調用者作用域中的值。我們將展示閉包的這些功能如何復用代碼和自定義行為。
使用閉包創建行為的抽象
看一個存儲稍后要執行的閉包的示例。
考慮一下這個假想的情況:我們在一個通過 app 生成自定義健身計劃的初創企業工作。其后端使用 Rust 編寫,而生成健身計劃的算法需要考慮很多不同的因素,比如用戶的年齡、身體質量指數(Body Mass Index)、用戶喜好、最近的健身活動和用戶指定的強度系數。本例中實際的算法并不重要,重要的是這個計算只花費幾秒鐘。我們只希望在需要時調用算法,并且只希望調用一次,這樣就不會讓用戶等得太久。
這里將通過調用?simulated_expensive_calculation?函數來模擬調用假象的算法,它會打印出?calculating slowly...,等待兩秒,并接著返回傳遞給它的數字:
use std::thread;
use std::time::Duration;fn main() {}fn simulate_expensive_calculation(intensity: u32) -> u32 {println!("calculating slowly...");thread::sleep(Duration::from_secs(2)); // 休眠2sintensity
}
接下來,main?函數中將會包含本例的健身 app 中的重要部分。這代表當用戶請求健身計劃時 app 會調用的代碼。因為與 app 前端的交互與閉包的使用并不相關,所以我們將硬編碼代表程序輸入的值并打印輸出。
所需的輸入有這些:
- 一個來自用戶的 intensity 數字,請求健身計劃時指定,它代表用戶喜好低強度還是高強度健身。
- 一個隨機數,其會在健身計劃中生成變化。
fn main() {let simulated_user_specified_value = 10;let simulated_random_number = 7;generate_workout(simulated_user_specified_value, simulated_random_number);
}出于簡單考慮這里硬編碼了?simulated_user_specified_value?變量的值為 10 和?simulated_random_number?變量的值為 7;一個實際的程序會從 app 前端獲取強度系數并使用?rand?crate 來生成隨機數,正如第二章的猜猜看游戲所做的那樣。main?函數使用模擬的輸入值調用?generate_workout?函數:
fn generate_workout(intensity: u32, random_number: u32) {if intensity < 25 {println!("Today, do {}, pushups", simulate_expensive_calculation(intensity));println!("Next do {}, situps", simulate_expensive_calculation(intensity));} else {if random_number == 3 {println!("Take a break today, remember to stay hydrated");} else {println!("today, run for {} minutes", simulate_expensive_calculation(intensity));}}
}上述代碼有多處調用了慢計算函數?simulated_expensive_calculation?。第一個?if?塊調用了?simulated_expensive_calculation?兩次,?else?中的?if?沒有調用它,而第二個?else?中的代碼調用了它一次。
generate_workout?函數的期望行為是首先檢查用戶需要低強度(由小于 25 的系數表示)鍛煉還是高強度(25 或以上)鍛煉。
低強度鍛煉計劃會根據由?simulated_expensive_calculation?函數所模擬的復雜算法建議一定數量的俯臥撐和仰臥起坐。
如果用戶需要高強度鍛煉,這里有一些額外的邏輯:如果 app 生成的隨機數剛好是 3,app 相反會建議用戶稍做休息并補充水分。如果不是,則用戶會從復雜算法中得到數分鐘跑步的高強度鍛煉計劃。
現在這份代碼能夠應對我們的需求了,但數據科學部門的同學告知我們將來會對調用?simulated_expensive_calculation?的方式做出一些改變。為了在要做這些改動的時候簡化更新步驟,我們將重構代碼來讓它只調用?simulated_expensive_calculation?一次。同時還希望去掉目前多余的連續兩次函數調用,并不希望在計算過程中增加任何其他此函數的調用。也就是說,我們不希望在完全無需其結果的情況調用函數,不過仍然希望只調用函數一次。
使用函數重構
首先嘗試的是將重復的?simulated_expensive_calculation?函數調用提取到一個變量中
fn generate_workout(intensity: u32, random_number: u32) {// 先提取出來let expensive_result =simulate_expensive_calculation(intensity);if intensity < 25 {println!("Today, do {}, pushups", expensive_result);println!("Next do {}, situps", expensive_result);} else {if random_number == 3 {println!("Take a break today, remember to stay hydrated");} else {println!("today, run for {} minutes", expensive_result);}}
}
不幸的是,現在所有的情況下都需要調用函數并等待結果,包括那個完全不需要這一結果的內部?if?塊。
我們希望能夠在程序的一個位置指定某些代碼,并只在程序的某處實際需要結果的時候?執行?這些代碼。這正是閉包的用武之地!
重構使用閉包儲存代碼
不同于總是在?if?塊之前調用?simulated_expensive_calculation?函數并儲存其結果,我們可以定義一個閉包并將其儲存在變量中,實際上可以選擇將整個?simulated_expensive_calculation?函數體移動到這里引入的閉包中:
// 定義閉包
let expensive_closure = |num| {println!("calculating slowly...");thread::sleep(Duration::from_secs(2));num
};類似lambda表達式?
閉包定義是?expensive_closure?賦值的?=?之后的部分。閉包的定義以一對豎線(|)開始,在豎線中指定閉包的參數;之所以選擇這個語法是因為它與 Smalltalk 和 Ruby 的閉包定義類似。這個閉包有一個參數?num;如果有多于一個參數,可以使用逗號分隔,比如?|param1, param2|。
參數之后是存放閉包體的大括號 —— 如果閉包體只有一行則大括號是可以省略的。大括號之后閉包的結尾,需要用于?let?語句的分號。因為閉包體的最后一行沒有分號(正如函數體一樣),所以閉包體(num)最后一行的返回值作為調用閉包時的返回值 。
注意這個?let?語句意味著?expensive_closure?包含一個匿名函數的?定義,不是調用匿名函數的?返回值。回憶一下使用閉包的原因是我們需要在一個位置定義代碼,儲存代碼,并在之后的位置實際調用它;期望調用的代碼現在儲存在?expensive_closure?中。
fn generate_workout(intensity: u32, random_number: u32) {// 定義閉包let expensive_closure = |num| {println!("calculating slowly...");thread::sleep(Duration::from_secs(2));num};if intensity < 25 {println!("Today, do {}, pushups", expensive_closure(intensity));println!("Next do {}, situps", expensive_closure(intensity));} else {if random_number == 3 {println!("Take a break today, remember to stay hydrated");} else {println!("today, run for {} minutes", expensive_closure(intensity));}}
}
現在耗時的計算只在一個地方被調用,并只會在需要結果的時候執行改代碼。
閉包類型推斷和注解
閉包不要求像fn函數那樣在參數和返回值上注明類型。函數中需要類型注解是因為他們是暴露給用戶的顯式接口的一部分。嚴格的定義這些接口對于保證所有人都認同函數使用和返回值的類型來說是很重要的。但是閉包并不用于這樣暴露在外的接口:他們儲存在變量中并被使用,不用命名他們或暴露給庫的用戶調用。
閉包通常很短并只與對應相對任意的場景較小的上下文中。在這些有限制的上下文中,編譯器能可靠的推斷參數和返回值的類型,類似于它是如何能夠推斷大部分變量的類型—樣。
強制在這些小的匿名函數中注明類型是很惱人的,并且與編譯器已知的信息存在大量的重復。
類似于變量,如果相比嚴格的必要性你更希望增加明確性并變得更啰嗦,可以選擇增加類型注解;
// 定義閉包
let expensive_closure = |num: u32| -> u32 {println!("calculating slowly...");thread::sleep(Duration::from_secs(2));num
};有了類型注解閉包的語法就更類似函數了。如下是一個對其參數加一的函數的定義與擁有相同行為閉包語法的縱向對比。這里增加了一些空格來對齊相應部分。這展示了閉包語法如何類似于函數語法,除了使用豎線而不是括號以及幾個可選的語法之外:
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;
第一行展示了一個函數定義,而第二行展示了一個完整標注的閉包定義。第三行閉包定義中省略了類型注解,而第四行去掉了可選的大括號,因為閉包體只有一行。這些都是有效的閉包定義,并在調用時產生相同的行為。
閉包定義會為每個參數和返回值推斷一個具體類型。除了作為示例的目的這個閉包并不是很實用。注意其定義并沒有增加任何類型注解:如果嘗試調用閉包兩次,第一次使用?String?類型作為參數而第二次使用?u32,則會得到一個錯誤:
fn test() {let example_closure = |x| x;let s = example_closure(String::from("hello"));let n = example_closure(5);}
結果

第一次使用?String?值調用?example_closure?時,編譯器推斷?x?和此閉包返回值的類型為?String。接著這些類型被鎖定進閉包?example_closure?中,如果嘗試對同一閉包使用不同類型則會得到類型錯誤。
使用帶有泛型和Fn trait的閉包
回到我們的健身計劃生成 app ,在示例中的代碼仍然調用了多于需要的慢計算閉包。解決這個問題的一個方法是在全部代碼中的每一個需要多個慢計算閉包結果的地方,可以將結果保存進變量以供復用,這樣就可以使用變量而不是再次調用閉包。但是這樣就會有很多重復的保存結果變量的地方。
幸運的是,還有另一個可用的方案。可以創建一個存放閉包和調用閉包結果的結構體。該結構體只會在需要結果時執行閉包,并會緩存結果值,這樣余下的代碼就不必再負責保存結果并可以復用該值。你可能見過這種模式被稱?memoization?或?lazy evaluation。
為了讓結構體存放閉包,我們需要指定閉包的類型,因為結構體定義需要知道其每一個字段的類型。每一個閉包實例有其自己獨有的匿名類型:也就是說,即便兩個閉包有著相同的簽名,他們的類型仍然可以被認為是不同。
Fn?系列 trait 由標準庫提供。所有的閉包都實現了 trait?Fn、FnMut?或?FnOnce?中的一個。
為了滿足?Fn?trait bound 我們增加了代表閉包所必須的參數和返回值類型的類型。在這個例子中,閉包有一個?u32?的參數并返回一個?u32,這樣所指定的 trait bound 就是?Fn(u32) -> u32。
struct Cacher<T>where T: Fn(u32) -> u32
{calculation: T,value: Option<u32>,
}結構體?Cacher?有一個泛型?T?的字段?calculation。T?的 trait bound 指定了?T?是一個使用?Fn?的閉包。任何我們希望儲存到?Cacher?實例的?calculation?字段的閉包必須有一個?u32?參數(由?Fn?之后的括號的內容指定)并必須返回一個?u32(由?->?之后的內容)。
注意:函數也都實現了這三個?
Fn?trait。如果不需要捕獲環境中的值,則可以使用實現了?Fn?trait 的函數而不是閉包。
字段?value?是?Option<u32>?類型的。在執行閉包之前,value?將是?None。如果使用?Cacher?的代碼請求閉包的結果,這時會執行閉包并將結果儲存在?value?字段的?Some?成員中。接著如果代碼再次請求閉包的結果,這時不再執行閉包,而是會返回存放在?Some?成員中的結果。
impl<T> Cacher<T>where T: Fn(u32) -> u32
{fn new(calculation: T) -> Cacher<T> {Cacher {calculation, value: None, }}fn value(&mut self, arg: u32) -> u32 {match self.value {Some(v) => v,None => {let v = (self.calculation)(arg);self.value = Some(v);v},}}
}
Cacher?結構體的字段是私有的,因為我們希望?Cacher?管理這些值而不是任由調用代碼潛在的直接改變他們。
Cacher::new?函數獲取一個泛型參數?T,它定義于?impl?塊上下文中并與?Cacher?結構體有著相同的 trait bound。Cacher::new?返回一個在?calculation?字段中存放了指定閉包和在?value?字段中存放了?None?值的?Cacher?實例,因為我們還未執行閉包。
當調用代碼需要閉包的執行結果時,不同于直接調用閉包,它會調用?value?方法。這個方法會檢查?self.value?是否已經有了一個?Some?的結果值;如果有,它返回?Some?中的值并不會再次執行閉包。
如果?self.value?是?None,則會調用?self.calculation?中儲存的閉包,將結果保存到?self.value?以便將來使用,并同時返回結果值。
fn generate_workout(intensity: u32, random_number: u32) {let mut expensive_result = Cacher::new(|num| {println!("calculating slowly...");thread::sleep(Duration::from_secs(2));num});if intensity < 25 {println!("Today, do {}, pushups", expensive_result.value(intensity));println!("Next do {}, situps", expensive_result.value(intensity));} else {if random_number == 3 {println!("Take a break today, remember to stay hydrated");} else {println!("today, run for {} minutes", expensive_result.value(intensity));}}
}不同于直接將閉包保存進一個變量,我們保存一個新的?Cacher?實例來存放閉包。接著,在每一個需要結果的地方,調用?Cacher?實例的?value?方法。可以調用?value?方法任意多次,或者一次也不調用,而慢計算最多只會運行一次。
Cacher實現的限制
值緩存是一種更加廣泛的實用行為,我們可能希望在代碼中的其他閉包中也使用他們。然而,目前?Cacher?的實現存在兩個小問題,這使得在不同上下文中復用變得很困難。
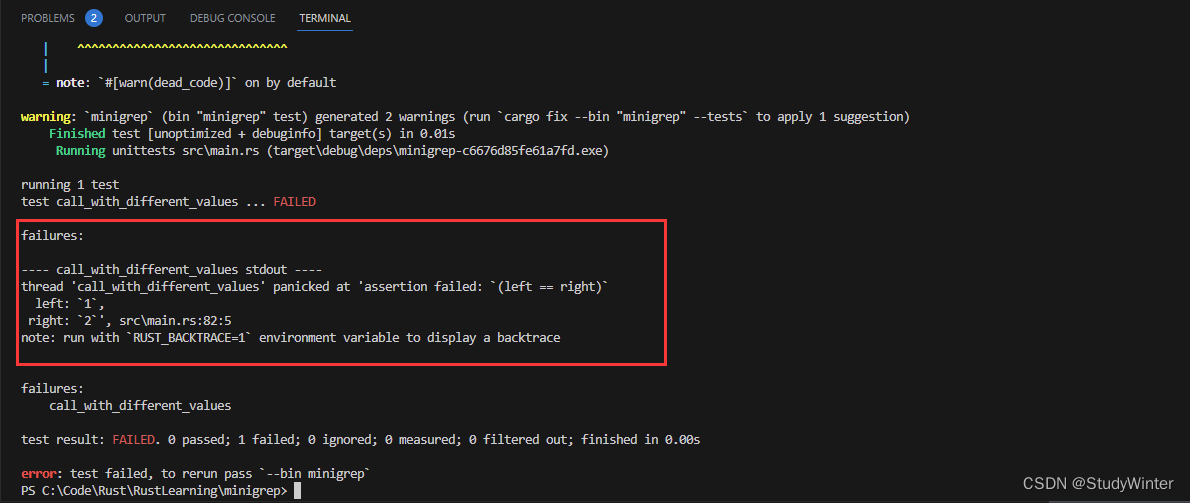
第一個問題是?Cacher?實例假設對于?value?方法的任何?arg?參數值總是會返回相同的值。也就是說,這個?Cacher?的測試會失敗:
#[test]
fn call_with_different_values() {let mut c = Cacher::new(|a| a);let v1 = c.value(1);let v2 = c.value(2);assert_eq!(v2, 2);
}
這個測試使用返回傳遞給它的值的閉包創建了一個新的?Cacher?實例。使用為 1 的?arg?和為 2 的?arg?調用?Cacher?實例的?value?方法,同時我們期望使用為 2 的?arg?調用?value?會返回 2。
這里的問題是第一次使用 1 調用?c.value,Cacher?實例將?Some(1)?保存進?self.value。在這之后,無論傳遞什么值調用?value,它總是會返回 1。
嘗試修改?Cacher?存放一個哈希 map 而不是單獨一個值。哈希 map 的 key 將是傳遞進來的?arg?值,而 value 則是對應 key 調用閉包的結果值。相比之前檢查?self.value?直接是?Some?還是?None?值,現在?value?函數會在哈希 map 中尋找?arg,如果找到的話就返回其對應的值。如果不存在,Cacher?會調用閉包并將結果值保存在哈希 map 對應?arg?值的位置。
當前?Cacher?實現的第二個問題是它的應用被限制為只接受獲取一個?u32?值并返回一個?u32?值的閉包。比如說,我們可能需要能夠緩存一個獲取字符串 slice 并返回?usize?值的閉包的結果。請嘗試引入更多泛型參數來增加?Cacher?功能的靈活性。
閉包會捕獲其環境
在健身計劃生成器的例子中,我們只將閉包作為內聯匿名函數來使用。不過閉包還有另一個函數所沒有的功能:他們可以捕獲其環境并訪問其被定義的作用域的變量。
fn main() {let x = 4;let equal_to_x = |z| z == x;let y = 4;assert!(equal_to_x(y));
}
這里,即便?x?并不是?equal_to_x?的一個參數,equal_to_x?閉包也被允許使用變量?x,因為它與?equal_to_x?定義于相同的作用域。
函數則不能做到同樣的事,如果嘗試如下例子,它并不能編譯:
fn main() {let x = 4;fn equal_to_x(z: i32) -> bool { z == x }let y = 4;assert!(equal_to_x(y));
}
結果

編譯器甚至會提示我們這只能用于閉包!
當閉包從環境中捕獲一個值,閉包會在閉包體中儲存這個值以供使用。這會使用內存并產生額外的開銷,在更一般的場景中,當我們不需要閉包來捕獲環境時,我們不希望產生這些開銷。因為函數從未允許捕獲環境,定義和使用函數也就從不會有這些額外開銷。
閉包可以通過三種方式捕獲其環境,他們直接對應函數的三種獲取參數的方式:獲取所有權,可變借用和不可變借用。這三種捕獲值的方式被編碼為如下三個?Fn?trait:
FnOnce?消費從周圍作用域捕獲的變量,閉包周圍的作用域被稱為其?環境,environment。為了消費捕獲到的變量,閉包必須獲取其所有權并在定義閉包時將其移動進閉包。其名稱的?Once?部分代表了閉包不能多次獲取相同變量的所有權的事實,所以它只能被調用一次。FnMut?獲取可變的借用值所以可以改變其環境Fn?從其環境獲取不可變的借用值
當創建一個閉包時,Rust 根據其如何使用環境中變量來推斷我們希望如何引用環境。由于所有閉包都可以被調用至少一次,所以所有閉包都實現了?FnOnce?。那些并沒有移動被捕獲變量的所有權到閉包內的閉包也實現了?FnMut?,而不需要對被捕獲的變量進行可變訪問的閉包則也實現了?Fn?。
如果你希望強制閉包獲取其使用的環境值的所有權,可以在參數列表前使用?move?關鍵字。
fn main() {let x = vec![1, 2, 3];let equal_to_x = move |z| z == x;println!("can not use x here: {:?}", x);let y = vec![1, 2, 3];assert!(equal_to_x(y));
}
這個例子并不能編譯,會產生以下錯誤:
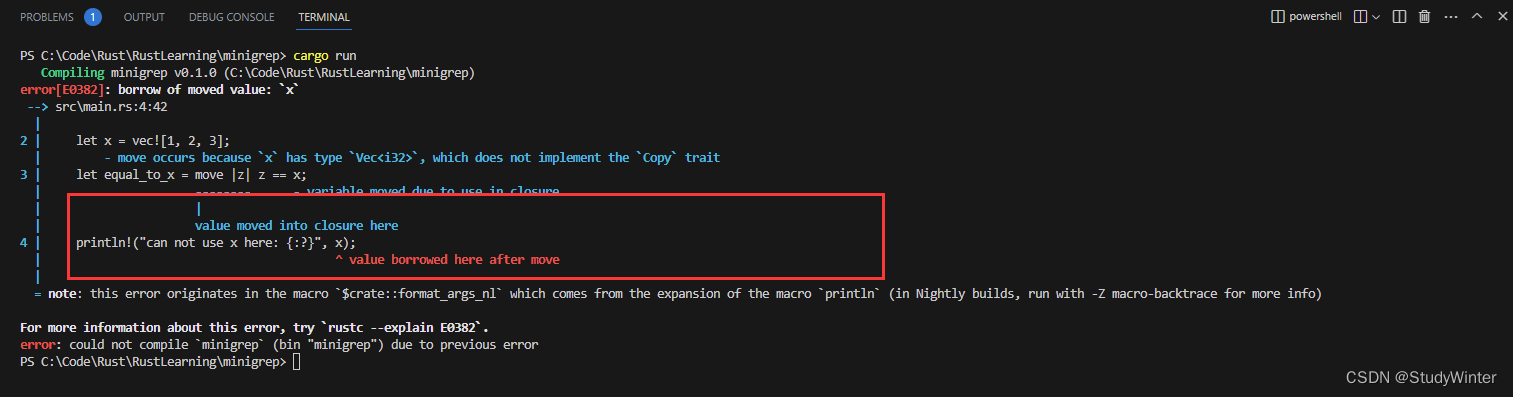
x?被移動進了閉包,因為閉包使用?move?關鍵字定義。接著閉包獲取了?x?的所有權,同時?main?就不再允許在?println!?語句中使用?x?了。去掉?println!?即可修復問題。
大部分需要指定一個?Fn?系列 trait bound 的時候,可以從?Fn?開始,而編譯器會根據閉包體中的情況告訴你是否需要?FnMut?或?FnOnce。
13.2?使用迭代器處理元素序列
迭代器模式允許你對一個項的序列進行某些處理。迭代器(iterator)負責遍歷序列中的每一項和決定序列何時結束的邏輯。當使用迭代器時,我們無需重新實現這些邏輯。
在 Rust 中,迭代器是?惰性的(lazy),這意味著在調用方法使用迭代器之前它都不會有效果。
fn main() {let v1 = vec![1, 2, 3];let v1_iter = v1.iter();
}
一旦創建迭代器之后,可以選擇用多種方式利用它。
fn main() {let v1 = vec![1, 2, 3];let v1_iter = v1.iter();for val in v1_iter {println!("got: {}", val);}
}
在標準庫中沒有提供迭代器的語言中,我們可能會使用一個從 0 開始的索引變量,使用這個變量索引 vector 中的值,并循環增加其值直到達到 vector 的元素數量。
迭代器為我們處理了所有這些邏輯,這減少了重復代碼并消除了潛在的混亂。另外,迭代器的實現方式提供了對多種不同的序列使用相同邏輯的靈活性,而不僅僅是像 vector 這樣可索引的數據結構.讓我們看看迭代器是如何做到這些的。
Iterator trait和next方法
迭代器都實現了一個叫做?Iterator?的定義于標準庫的 trait。這個 trait 的定義看起來像這樣:
pub trait Iterator {type Item;fn next(&mut self)-> Option<Self::Item>;// 此處省略了方法的默認實現}
注意這里有一下我們還未講到的新語法:type Item?和?Self::Item,他們定義了 trait 的?關聯類型(associated type)。不過現在只需知道這段代碼表明實現?Iterator?trait 要求同時定義一個?Item?類型,這個?Item?類型被用作?next?方法的返回值類型。換句話說,Item?類型將是迭代器返回元素的類型。
next?是?Iterator?實現者被要求定義的唯一方法。next?一次返回迭代器中的一個項,封裝在?Some?中,當迭代器結束時,它返回?None。可以直接調用迭代器的?next?方法。
fn main() {iterator_demonstration();
}fn iterator_demonstration() {let v1 = vec![1, 2, 3];let mut v1_iter = v1.iter();// 迭代器移動assert_eq!(v1_iter.next(), Some(&1));assert_eq!(v1_iter.next(), Some(&2));assert_eq!(v1_iter.next(), Some(&3));assert_eq!(v1_iter.next(), None);
}注意?v1_iter?需要是可變的:在迭代器上調用?next?方法改變了迭代器中用來記錄序列位置的狀態。換句話說,代碼?消費(consume)了,或使用了迭代器。每一個?next?調用都會從迭代器中消費一個項。使用?for?循環時無需使?v1_iter?可變因為?for?循環會獲取?v1_iter?的所有權并在后臺使?v1_iter?可變。
另外需要注意到從?next?調用中得到的值是 vector 的不可變引用。iter?方法生成一個不可變引用的迭代器。如果我們需要一個獲取?v1?所有權并返回擁有所有權的迭代器,則可以調用?into_iter?而不是?iter。類似的,如果我們希望迭代可變引用,則可以調用?iter_mut?而不是?iter。
消費迭代器的方法
Iterator?trait 有一系列不同的由標準庫提供默認實現的方法;你可以在?Iterator?trait 的標準庫 API 文檔中找到所有這些方法。一些方法在其定義中調用了?next?方法,這也就是為什么在實現?Iterator?trait 時要求實現?next?方法的原因。
這些調用?next?方法的方法被稱為?消費適配器(consuming adaptors),因為調用他們會消耗迭代器。一個消費適配器的例子是?sum?方法。這個方法獲取迭代器的所有權并反復調用?next?來遍歷迭代器,因而會消費迭代器。
當其遍歷每一個項時,它將每一個項加總到一個總和并在迭代完成時返回總和。
fn main() {iterator_demonstration();
}fn iterator_demonstration() {let v1 = vec![1, 2, 3];let v1_iter = v1.iter();let total: i32 = v1_iter.sum(); // 求和assert_eq!(total, 6);}
調用?sum?之后不再允許使用?v1_iter,?因為調用?sum?時它會獲取迭代器的所有權。
產生其他迭代器的方法
Iterator?trait 中定義了另一類方法,被稱為?迭代器適配器(iterator adaptors),他們允許我們將當前迭代器變為不同類型的迭代器。可以鏈式調用多個迭代器適配器。不過因為所有的迭代器都是惰性的,必須調用一個消費適配器方法以便獲取迭代器適配器調用的結果。
下面展示了一個調用迭代器適配器方法?map?的例子,該?map?方法使用閉包來調用每個元素以生成新的迭代器。 這里的閉包創建了一個新的迭代器,對其中 vector 中的每個元素都被加 1。不過這些代碼會產生一個警告:
fn main() {let v1: Vec<i32> = vec![1, 2, 3];v1.iter().map(|x| x + 1);}
得到的警告是:
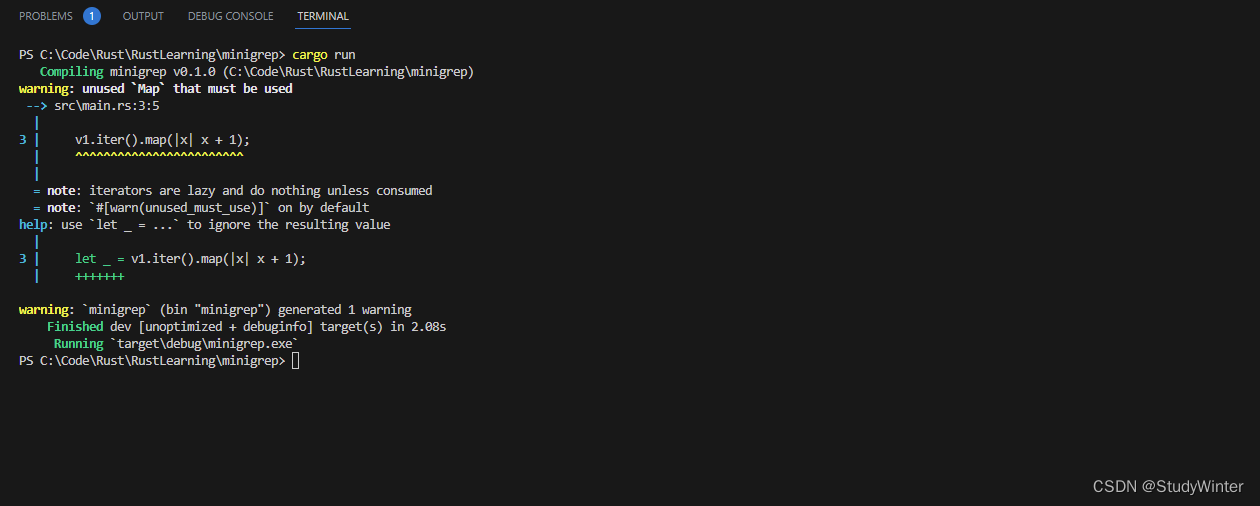
代碼實際上并沒有做任何事;所指定的閉包從未被調用過。警告提醒了我們為什么:迭代器適配器是惰性的,而這里我們需要消費迭代器。
為了修復這個警告并消費迭代器獲取有用的結果,我們將使用第十二章結合?env::args?使用的?collect?方法。這個方法消費迭代器并將結果收集到一個數據結構中。
在示例,我們將遍歷由?map?調用生成的迭代器的結果收集到一個 vector 中,它將會含有原始 vector 中每個元素加 1 的結果:
fn main() {let v1: Vec<i32> = vec![1, 2, 3];let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();assert_eq!(v2, vec![2, 3, 4]);}
調用?map?方法創建一個新迭代器,接著調用?collect?方法消費新迭代器并創建一個 vector
因為?map?獲取一個閉包,可以指定任何希望在遍歷的每個元素上執行的操作。這是一個展示如何使用閉包來自定義行為同時又復用?Iterator?trait 提供的迭代行為的絕佳例子。
實現Iterator trait 來創建自定義迭代器
之前已經展示了可以通過在 vector 上調用?iter、into_iter?或?iter_mut?來創建一個迭代器。也可以用標準庫中其他的集合類型創建迭代器,比如哈希 map。另外,可以實現?Iterator?trait 來創建任何我們希望的迭代器。正如之前提到的,定義中唯一要求提供的方法就是?next?方法。一旦定義了它,就可以使用所有其他由?Iterator?trait 提供的擁有默認實現的方法來創建自定義迭代器了!
作為展示,讓我們創建一個只會從 1 數到 5 的迭代器。首先,創建一個結構體來存放一些值,接著實現?Iterator?trait 將這個結構體放入迭代器中并在此實現中使用其值。
struct Counter {count: u32,
}impl Counter {fn new() -> Counter {Counter { count: 0 }}
}
Counter?結構體有一個字段?count。這個字段存放一個?u32?值,它會記錄處理 1 到 5 的迭代過程中的位置。count?是私有的因為我們希望?Counter?的實現來管理這個值。new?函數通過總是從為 0 的?count?字段開始新實例來確保我們需要的行為。
impl Iterator for Counter {type Item = u32;fn next(&mut self) -> Option<Self::Item> {self.count += 1;if self.count < 6 {Some(self.count)} else {None}}
}
這里將迭代器的關聯類型?Item?設置為?u32,意味著迭代器會返回?u32?值集合。
我們希望迭代器對其內部狀態加一,這也就是為何將?count?初始化為 0:我們希望迭代器首先返回 1。如果?count?值小于 6,next?會返回封裝在?Some?中的當前值,不過如果?count?大于或等于 6,迭代器會返回?None。
使用Counter送代器的next方法
一旦實現了?Iterator?trait,我們就有了一個迭代器!
#[test]
fn calling_next_directly() {let mut counter = Counter::new();assert_eq!(counter.next(), Some(1));assert_eq!(counter.next(), Some(2));assert_eq!(counter.next(), Some(3));assert_eq!(counter.next(), Some(4));assert_eq!(counter.next(), Some(5));assert_eq!(counter.next(), None);
}
這個測試在?counter?變量中新建了一個?Counter?實例并接著反復調用?next?方法,來驗證我們實現的行為符合這個迭代器返回從 1 到 5 的值的預期。
使用自定義送代器中其他工terator trait方法
通過定義?next?方法實現?Iterator?trait,我們現在就可以使用任何標準庫定義的擁有默認實現的?Iterator?trait 方法了,因為他們都使用了?next?方法的功能。
例如,出于某種原因我們希望獲取?Counter?實例產生的值,將這些值與另一個?Counter?實例在省略了第一個值之后產生的值配對,將每一對值相乘,只保留那些可以被三整除的結果,然后將所有保留的結果相加。
#[test]
fn using_other_iterator_trait_methods() {let sum: u32 = Counter::new().zip(Counter::new().skip(1)).map(|(a, b)|a * b).filter(|x| x % 3 == 0).sum();assert_eq!(18, sum);
}
注意?zip?只產生四對值;理論上第五對值?(5, None)?從未被產生,因為?zip?在任一輸入迭代器返回?None?時也返回?None。
所有這些方法調用都是可能的,因為我們指定了?next?方法如何工作,而標準庫則提供了其它調用?next?的方法的默認實現。
13.3 改進I/O項目
有了這些關于迭代器的新知識,我們可以使用迭代器來改進第十二章中 I/O 項目的實現來使得代碼更簡潔明了。
使用迭代器并去掉clone
impl Config {pub fn new(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let filename = args[2].clone();let case_sensitive = env::var("CASE_INSENSITIVE").is_err();Ok(Config { query, filename, case_sensitive })}
}
那時我們說過不必擔心低效的?clone?調用了,因為將來可以對他們進行改進。好吧,就是現在!
起初這里需要?clone?的原因是參數?args?中有一個?String?元素的 slice,而?new?函數并不擁有?args。為了能夠返回?Config?實例的所有權,我們需要克隆?Config?中字段?query?和?filename?的值,這樣?Config?實例就能擁有這些值。
在學習了迭代器之后,我們可以將?new?函數改為獲取一個有所有權的迭代器作為參數而不是借用 slice。我們將使用迭代器功能之前檢查 slice 長度和索引特定位置的代碼。這會明確?Config::new?的工作因為迭代器會負責訪問這些值。
一旦?Config::new?獲取了迭代器的所有權并不再使用借用的索引操作,就可以將迭代器中的?String?值移動到?Config?中,而不是調用?clone?分配新的空間。
直接使用env : : args返回的迭代器
打開 I/O 項目的?src/main.rs?文件,它看起來應該像這樣:
fn main() {let args: Vec<String> = env::args().collect();let config = Config::new(&args).unwrap_or_else(|err| {eprintln!("Problem parsing arguments: {}", err);process::exit(1);});// --snip--
}
在更新?Config::new?之前這些代碼還不能編譯:
fn main() {let config = Config::new(env::args()).unwrap_or_else(|err| {eprintln!("Problem parsing arguments: {}", err);process::exit(1);});// --snip--
}
env::args?函數返回一個迭代器!不同于將迭代器的值收集到一個 vector 中接著傳遞一個 slice 給?Config::new,現在我們直接將?env::args?返回的迭代器的所有權傳遞給?Config::new。
impl Config {pub fn new(mut args: std::env::Args) -> Result<Config, &'static str> {// --snip--
env::args?函數的標準庫文檔顯示,它返回的迭代器的類型為?std::env::Args。我們已經更新了?Config :: new?函數的簽名,因此參數?args?的類型為?std::env::Args?而不是?&[String]。因為我們擁有?args?的所有權,并且將通過對其進行迭代來改變?args?,所以我們可以將?mut?關鍵字添加到?args?參數的規范中以使其可變。
使用Iterator trait 代替索引
接下來,我們將修改?Config::new?的內容。標準庫文檔還提到?std::env::Args?實現了?Iterator?trait,因此我們知道可以對其調用?next?方法!
fn main() {}
use std::env;struct Config {query: String,filename: String,case_sensitive: bool,
}impl Config {pub fn new(mut args: std::env::Args) -> Result<Config, &'static str> {args.next();let query = match args.next() {Some(arg) => arg,None => return Err("Didn't get a query string"),};let filename = match args.next() {Some(arg) => arg,None => return Err("Didn't get a file name"),};let case_sensitive = env::var("CASE_INSENSITIVE").is_err();Ok(Config { query, filename, case_sensitive })}
}
請記住?env::args?返回值的第一個值是程序的名稱。我們希望忽略它并獲取下一個值,所以首先調用?next?并不對返回值做任何操作。之后對希望放入?Config?中字段?query?調用?next。如果?next?返回?Some,使用?match?來提取其值。如果它返回?None,則意味著沒有提供足夠的參數并通過?Err?值提早返回。對?filename?值進行同樣的操作。
使用迭代器適配器來使代碼更簡明
I/O 項目中其他可以利用迭代器的地方是?search?函數
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {let mut results = Vec::new();for line in contents.lines() {if line.contains(query) {results.push(line);}}results
}
可以通過使用迭代器適配器方法來編寫更簡明的代碼。這也避免了一個可變的中間?results?vector 的使用。函數式編程風格傾向于最小化可變狀態的數量來使代碼更簡潔。去掉可變狀態可能會使得將來進行并行搜索的增強變得更容易,因為我們不必管理?results?vector 的并發訪問。
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {contents.lines().filter(|line| line.contains(query)).collect()
}
回憶?search?函數的目的是返回所有?contents?中包含?query?的行。可以使用?filter?適配器只保留?line.contains(query)?返回?true?的那些行。接著使用?collect?將匹配行收集到另一個 vector 中。這樣就容易多了!嘗試對?search_case_insensitive?函數做出同樣的使用迭代器方法的修改吧。
13.4?性能對比:循環VS迭代器
結果迭代器版本還要稍微快一點!這里我們將不會查看性能測試的代碼,我們的目的并不是為了證明他們是完全等同的,而是得出一個怎樣比較這兩種實現方式性能的基本思路。
對于一個更全面的性能測試,將會檢查不同長度的文本、不同的搜索單詞、不同長度的單詞和所有其他的可變情況。這里所要表達的是:迭代器,作為一個高級的抽象,被編譯成了與手寫的底層代碼大體一致性能代碼。迭代器是 Rust 的?零成本抽象(zero-cost abstractions)之一,它意味著抽象并不會引入運行時開銷,它與本賈尼·斯特勞斯特盧普(C++ 的設計和實現者)在 “Foundations of C++”(2012) 中所定義的?零開銷(zero-overhead)如出一轍:
像音頻解碼器這樣的程序通常最看重計算的性能。這里,我們創建了一個迭代器,使用了兩個適配器,接著消費了其值。Rust 代碼將會被編譯為什么樣的匯編代碼呢?好吧,在編寫本書的這個時候,它被編譯成與手寫的相同的匯編代碼。遍歷?coefficients?的值完全用不到循環:Rust 知道這里會迭代 12 次,所以它“展開”(unroll)了循環。展開是一種移除循環控制代碼的開銷并替換為每個迭代中的重復代碼的優化。
所有的系數都被儲存在了寄存器中,這意味著訪問他們非常快。這里也沒有運行時數組訪問邊界檢查。所有這些 Rust 能夠提供的優化使得結果代碼極為高效。現在知道這些了,請放心大膽的使用迭代器和閉包吧!他們使得代碼看起來更高級,但并不為此引入運行時性能損失。
總結
閉包和迭代器是 Rust 受函數式編程語言觀念所啟發的功能。他們對 Rust 以底層的性能來明確的表達高級概念的能力有很大貢獻。閉包和迭代器的實現達到了不影響運行時性能的程度。這正是 Rust 竭力提供零成本抽象的目標的一部分。
參考:Rust 中的函數式語言功能:迭代器與閉包 - Rust 程序設計語言 簡體中文版 (bootcss.com)



——CentOS7開機自動執行腳本(以MySQL為例))




)










)