8.排序
8.1排序的概念
什么是排序?
- 排序:將一組雜亂無章的數據按一定規律順序排列起來。即,將無序序列排成一個有序序列(由小到大或由大到小)的運算。
- 如果參加排序的數據結點包含多個數據域,那么排序往往是針對其中某個域而言。
排序方法的分類
-
按存儲介質可分為:
-
內部排序:數據量不大、數據在內存,無需內外存交換數據
-
外部排序:數據量較大、數據在外存(文件排序)
? 外部排序時,要將數據分批調入內存在排序,中間結果還要及時放入外存,顯然外部排序要復雜得多。
-
-
按比較器個數可分為:
- 串行排序:單處理機(同一時刻比較一對元素)
- 并行排序:多處理機(同一時刻比較多對元素)
-
按主要操作可分為:
-
比較排序:用比較的方法
? 插入排序、交換排序、選擇排序、歸并排序
-
基數排序:不比較元素的大小,僅僅根據元素本身的取值確定其有序位置。
-
-
按輔助空間可分為:
-
原地排序:輔助空間用量為O(1)的排序方法。
? (所占的輔助存儲空間與參加排序的數據量大小無關)
-
非原地排序:輔助空間用量超過O(1)的排序方法。
-
-
按穩定性可分為:
- 穩定排序:能夠使任何數值相等的元素,排序以后相對次序不變。
- 非穩定性排序:不是穩定排序的方法。
-
按自然性可分為:
- 自然排序:輸入數據越有序,排序的速度越快的排序方法。
- 非自然排序:不是自然排序的方法。
存儲結構——記錄序列以順序表存儲
#define MAXSIZE 20
typedef int KeyType;//設關鍵字為整型量(int型)
Typedef struct{//定義每個記錄(數據元素)的結構KeyType key;//關鍵字InfoType otherinfo;//其他數據項
}RedType;
Typedef struct{//定義順序表的結構RedType r[MAXSIZE+1];//存儲順序表的向量int length;//r[0]一般作哨兵或緩沖區
}SqList;
8.2插入排序
基本思想:每一步將一個待排序的對象,按其關鍵碼大小,插入到前面已經排好序的一組對象的適當位置上,直到對象全部插入為止。
即邊插遍排序,保證子序列中隨時都是排好序的
基本操作:有序插入
- 在有序序列中插入一個元素,保持序列有序,有序長度不斷增加。
- 起初,a[0]是長度為1的子序列。然后,逐一將a[1]至a[n-1]插入到有序子序列中。
有序插入方法:
- 在插入a[i]前,數組a的前半段(a[0]~a[i-1])是有序段,后半段(a[i] ~a[n-1])是停留于輸入次序的無序段。
- 在插入a[i]使a[0]~a[i-1]有序,也就是要為a[i]找到有序位置j(0≤j≤i),將a[i]插入在a[j]的位置上。
插入排序的種類:
? 順序法定位插入位置————直接插入排序
? 二分法定位插入位置————二分插入排序
? 縮小增量多遍插入排序————希爾排序
8.2.1直接插入排序
- 直接插入排序——采用順序查找法查找插入位置

- 復制插入元素
- 記錄后移,查找插入位置
- 插入到正確位置
x=a[i];
for(j=i-1;j>=0&&x<a[j];j--)a[j+1]=a[j];
a[j-1]=x;
- 直接插入排序,使用“哨兵”

- 復制為哨兵
- 記錄后移,查找插入位置
- 插入到正確位置
L.r[0]=L.r[i];
for(j=i-1;L.r[0].key<L.r[j].key;--j)L.r[j+1]=L.r[j];
L.r[j+1]=L.r[0];
void InsertSort(SqList &L){int i,j;for(i=2;i<=L.length;++i){if(L.r[i].key<L.r[i-1].key){//若“<”,需將L.r[i]插入有序子表L.r[0]=L.r[i];//復制為哨兵for(j=i-1;L.r[0].key<L.r[j].key;--j){L.r[j+1]=L.r[j];//記錄后移}L.r[j+1]=L.r[0];//插入到正確位置}}
}
實現排序的基本操作有兩個:
- 比較序列中兩個關鍵字的大小;
- 移動記錄。
直接插入排序在什么情況下效率比較高?
? 直接插入排序在基本有序時,效率較高
? 在待排序的記錄個數較少時,效率較高
8.2.2折半插入排序
查找插入位置時采用折半查找法

void BInsertSort(SqList &L){for(i=2;i<=L.length;++i){//依次插入第2~第n個元素L.r[0]=L.r[i];//當前插入元素存到“哨兵”位置low=1;high=i-1;while(low<=high){mid=(mid+high)/2;if(L.r[0].key<L.r[mid].key)high=mid-1;else low=mid+1;}//循環結束,high+1則為插入位置for(j=i-1;j>=high+1;--j)L.r[j+1]=L.r[j];L.r[high+1]=L.r[0];}
}
算法分析:
- 折半查找比順序查找快,所以折半插入排序就平均性能來說比直接插入排序要快;
- 它所需要的關鍵碼比較次數與待排序對象序列的初始排序無關,僅依賴于對象個數。在插入第i個對象時,需要經過[log2i]+1次關鍵碼比較,才能確定它應插入的位置;
- 當n較大時,總關鍵碼比較次數比直接插入排序的最壞情況要好得多,但比其最好情況要差;
- 在對象的初始排序已經按關鍵碼排好序或接近有序時,直接插入排序比折半插入排序執行的關鍵碼比較次數要少;
- 折半插入排序的對象移動次數與直接插入排序相同,依賴于對象的初始排列
- 減少了比價次數,但沒有減少移動次數
- 平均性能優于直接插入排序
8.2.3希爾排序
基本思想:先將整個待排記錄序列分割成若干個系列,分別進行直接插入排序,待整個序列中的記錄“基本有序”時,再對全體記錄進行一次直接插入排序。
希爾排序算法,特點:
- 縮小增量
- 多遍插入排序
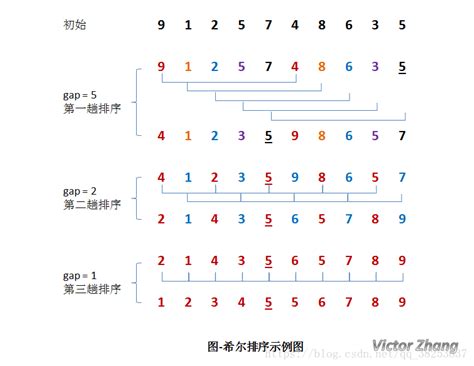
希爾排序特點
- 一次移動,移動位置較大,跳躍式地接近排序后的最終位置
- 最后一次只需要少量移動
- 增量序列必須是遞減的,最后一個必須是1
- 增量序列應該是互質的
希爾排序算法(主程序)
void ShellSort(Sqlist &L,int dlta[],int t){//按增量序列dlta[0..t-1]對順序表L作希爾排序。for(k=0;k<t;++k)ShellInsert(L,dlta[k]);//一趟增量為dlta[k]的插入排序
}
void ShellInsert(SqList &L,int dk){//對順序表L進行一趟增量為dk的Shell排序,dk為步長因子for(i=dk+1;i<=L.length;++i){if(r[i].key<r[i-dk].key){r[0]=r[i];for(j=i-dk;j>0&&(r[0].key<r[j].key);j=j-dk)r[j+dk]=r[j];r[j+dk]=r[0];}}
}
希爾排序算法分析
希爾排序是一種不穩定的排序方法
- 如何選擇最佳d序列,目前尚未解決
- 最后一個增量值必須為1,無除了1之外的公因子
- 不宜在鏈式存儲結構上實現
8.3交換排序
基本思想:兩兩比較,如果發生逆序則交換,直到所有記錄都排好序為止。
常見額交換排序方法:
? 冒泡排序O(n2)
? 快速排序O(nlog2n)
8.3.1冒泡排序
冒泡排序——基于簡單交換思想
基本思想:每趟不斷將記錄兩兩比較,并按“前小后大”規則交換
總結:n個記錄,總共需要n-1趟
第m趟需要比較 n-m次
void bubble_sort(SqList &L){int m,i,j;RedType x;//交換時臨時存儲for(m=1;m<=n-1;m++){//總共需m趟for(j=1;j<=n-m;j++)if(L.r[j].key>L.r[j+i].key){//發生逆序x=L.r[j];L.r[j]=L.r[j+1];L.r[j+1]=x;//交換}}
}
優點:每趟結束時,不僅能擠出一個最大值到最后面位置,還能同時部分理順其他元素;
如何提高效率?
? 一旦某一趟比較時不出現記錄交換,說明已排好序了,就可以結束本算法。
改進的冒泡排序算法
void bubble_sort(SqList &L){int m,i,j,flag=1;RedType x;//flag作為是否有交換的標記for(m=1;m<=n-1&&flag==1;m++){flag=0;for(j=1;j<=m;j++)if(L.r[j].key>L.r[j+1].key){//發生逆序flag=1;//發生交換,flag置為1,若本趟沒發生交換,flag保持為0x=L.r[j];L.r[j]=L.r[j+1];L.r[j+1]=x;//交換}}
}
8.3.2快速排序
快速排序——改進的交換排序
基本思想:
- 任取一個元素(如:第一個)為中心
- 所有比它小的元素一律前放,比它大的元素一律后放,形成左右兩個子表;
- 對各子表重新選擇中心元素并依次規則調整
- 直到每個子表的元素只剩一個
基本思想:通過一趟排序,將待排序記錄分割成獨立的兩部分,其中一部分記錄的關鍵字均比另一部分記錄的關鍵字小,則可分別對這兩部分記錄進行排序,以達到整個序列有序。
具體實現:選定一個中間數作為參考,所有元素與之比較,小的調到其左邊,大的調到其右邊。
(樞軸)中間數:可以是第一個數、最后一個數、最中間一個數、任選一個數等。

- 每一趟的子表的形成是采用從兩頭向中間交替式逼近法;
- 由于每趟中對各子表的操作都相似,可采用遞歸算法
void main(){QSort(L,1,L.length);
}
void QSort(SqList &L,int low,int high){if(low<high){//長度大于1pivotloc=Partition(L,low,high);//將L.r[low..high]一分為二,pivotloc為樞軸元素排好序的位置QSort(L,low,pivotloc-1);//對低子表遞歸排序QSort(L,pivotloc+1,high);//對高子表遞歸排序}
}
int Partition(SqList &L,int low,int high){L.r[0]=L.r[low];pivotkey=L.r[low].key;while(low<high){while(low<high&&L.r[high].key>=pivotkey)--high;L.r[low]=L.r[high];while(low<high&&L.r[low].key<=pivotkey)++low;L.r[high]=L.r[low];}L.r[low]=L.r[0];return low;
}
快速排序算法分析
-
時間復雜度
- 可以證明,平均計算時間是0(nlog2n)。
- Qsort():O(log2n)
- Partition():O(n)
- 實驗結果表明:就平均計算時間而言,快速排序是我們所討論的所有排序方法中最好的一個
- 可以證明,平均計算時間是0(nlog2n)。
-
空間排序
快速排序不是原地排序
? 由于程序中使用了遞歸,需要遞歸調用棧的支持,而棧的長度取決于遞歸調用的深度。(即使不用遞歸,也需要用用戶棧)
- 在平均情況下:需要O(logn)的棧空間
- 最壞情況下:棧空間可達O(n)
-
穩定性:快速排序是一種不穩定的排序方法
? 由于每次樞軸記錄的關鍵字都是大于其它所有記錄的關鍵字,致使一次劃分之后得到的子序列(1)的長度為0,這時已經退化成為沒有改進措施的冒泡排序。
-
快速排序不適于對原本有序或基本有序的記錄序列進行排序。
-
劃分元素的選取是影響時間性能的關鍵
-
輸入數據次序越亂,所選劃分元素值的隨機性越好,排序適度越快,快速排序不是自然排序方法。
-
改變劃分元素的選取方法,至多只能改變算法平均情況下的世界性能,無法改變最壞情況下的時間性能。即最壞情況下,快速排序的時間復雜性總是O(n2)
-
8.4選擇排序
8.4.1簡單選擇排序
基本思想:在待排序的數據中選出最大(小)的元素放在其最終的位置。
基本操作:
- 首先通過n-1次關鍵字比較,從n個記錄中找出關鍵字最小的記錄,將它與第一個記錄交換
- 再通過n-2次比較,從剩余的n-1個記錄中找出關鍵字次小的記錄,將它與第二個記錄交換
- 重復上述操作,共進行n-1趟排序后,排序結束

void SelectSort(SqList &K){for(i=1;i<L.length;++i){k=i;for(j=i+1;j<=L.length;j++)if(L.r[j].key<L.r[k].key) k=j;//記錄最小值位置if(k!=i)L.r[i]←→L.r[k];//交換}
}
時間復雜度
- 記錄移動次數
- 最好情況:0
- 最壞情況:3(n-1)
- 比較次數:無論待排序處于什么狀態,選擇排序所需進行的“比較”次數都相同
算法穩定性
- 簡單選擇排序是不穩定排序
8.4.2堆排序

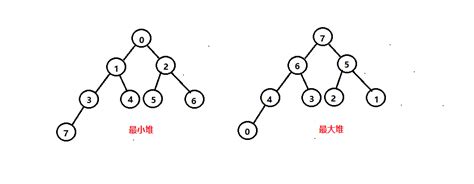
則分別稱該序列{a1 a2 … an}為小根堆和大根堆。
? 從堆的定義可以看出,堆實質是滿足如下性質的完全二叉樹:二叉樹中任一非葉子結點均小于(大于)它的孩子結點。。
堆排序:若在輸出堆頂的最小值(最大值)后,使得剩余n-1個元素的序列重新又建成一個堆,則得到n個元素的次小值(次大值)……如此反復,便能得到一個有序序列,這個過程稱之為堆排序。
實現堆排序需解決兩個問題:
- 如何由一個無序序列建成一個堆?
- 如何在輸出堆頂元素后,調整剩余元素為一個新的堆?
小根堆:
- 輸出堆頂元素之后,以堆中最后一個元素替代之;
- 然后將根節點值與左、右子樹的根結點值進行比較,并與其中小者進行交換;
- 重復上述操作,直至葉子結點,將得到新的堆,稱這個從堆頂至葉子的調整過程為“篩選”
堆的調整
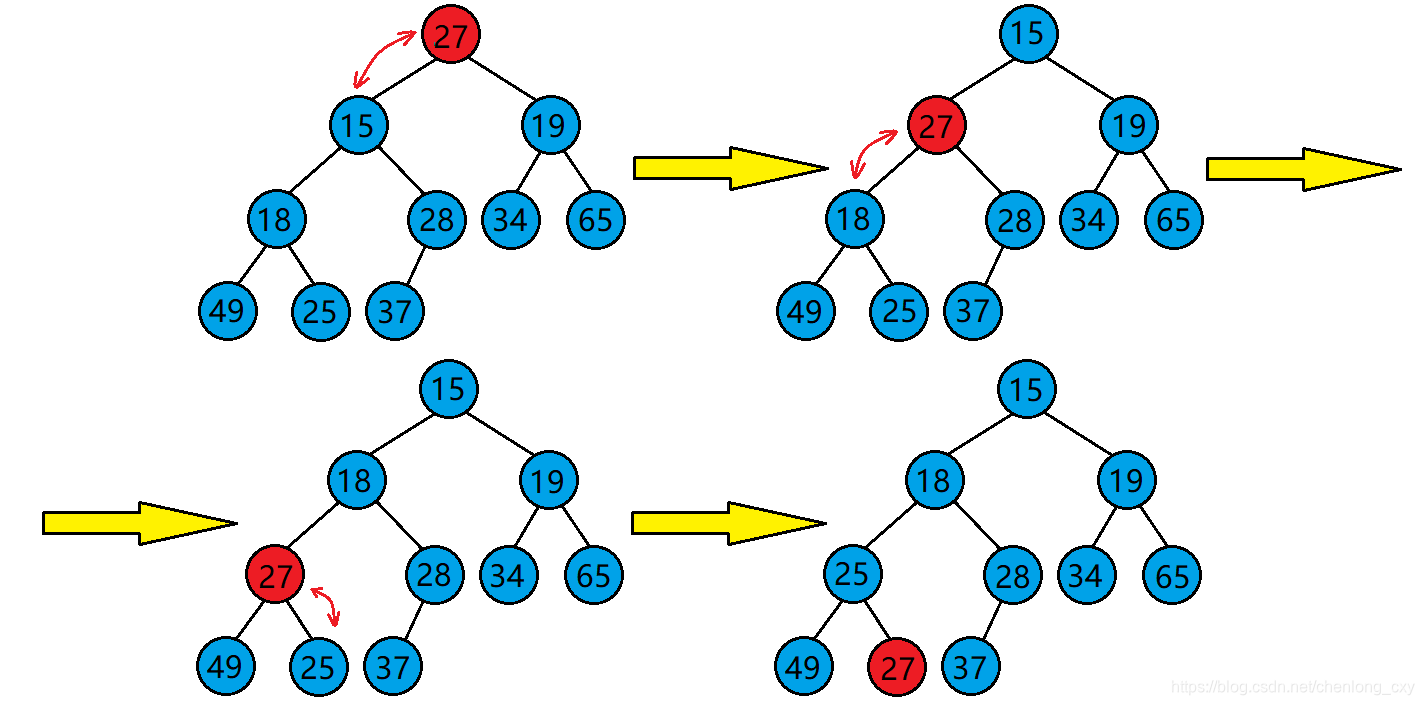
篩選過程的算法描述為:
void HeapAdjust(elem R[],int s,int m){/*已知R[s..m]中記錄的關鍵字除R[s]之外均滿足堆的定義,本函數調整R[s]的關鍵字,使R[s..m]成為一個大根堆*/rc=R[s];for(j=2*s;j<=m;j*=2){//沿key較大的孩子結點向下篩選if(j<m&&R[j]<R[j+1])//j為key較大的記錄的下標++j;if(rc>=R[j]) break;R[s]=R[j];//rc應該插入在位置s上s=j;}R[s]=rc;//插入
}
可以看出:
? 對一個無序序列反復“篩選”就可以得到一個堆;即:從一個無序序列建堆的過程就是一個反復“篩選”的過程。
如何由無序序列建成一個堆?
? 單結點的二叉樹是堆;
? 在完全二叉樹中所有以葉子結點(序號i>n/2)為根的子樹是堆。
? 這樣,我們只需依次將以序號為n/2,n/2-1,……,1的結點為根的子樹均調整為堆即可。
? 即:對應由n個元素組成的無序序列,“篩選”只需從第n/2個元素開始。
由于堆實質上是一個線性表,那么我們可以順序存儲一個堆。
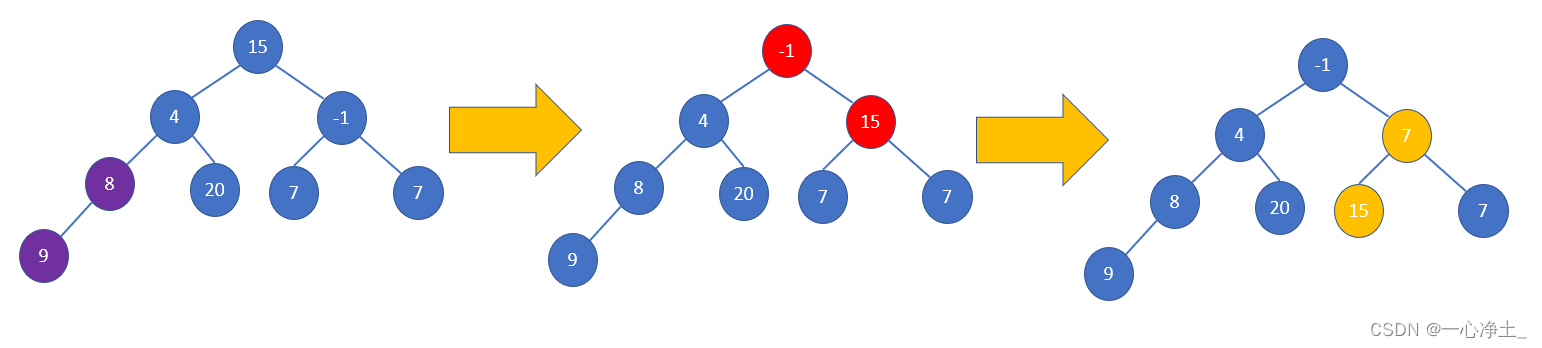
從最后一個非葉子結點開始,以此向前調整:
- 調整從第n/2個元素開始,將以該元素為根的二叉樹調整為堆
- 將以序號為n/2-1的結點為根的二叉樹調整為堆
- 再將以序號為n/2-2的結點為根的二叉樹調整為堆;
- 再將以序號為n/2-3的結點為根的二叉樹調整為堆
由以上分析知:
? 若對一個無序序列建堆,然后輸出根;重復該過程就可以由一個無序序列輸出有序序列。
? 實質上,堆排序就是利用完成二叉樹中父結點與孩子結點之間的內在關系來排序的。
堆排序算法如下:
void HeapSort(elem R[]){//對R[1]到R[n]進行堆排序int i;for(i=n/2;i>=i;i--)HeapAdjust(R,i,n);//建初始堆for(i=n;i>1;i--){//進行n-1趟排序Swap(R[1],R[i]);//根與最后一個元素交換HeapAdjust(R,1,i-1);//對R[1]到R[i-1]重新建堆}
}
- 堆排序的時間主要耗費在建初始堆和調整建新堆時進行的反復篩選上。堆排序在最壞情況下,其時間復雜度也為O(nlog2n),這是堆排序的最大優點。無論待排序中的記錄是正序還是逆序排序,都不會使堆排序處于“最好”或“最壞”的狀態。
- 另外,堆排序僅需一個記錄大小供交換用的輔助存儲空間。
- 然而堆排序是一種不穩定的排序方法,它不使用于待排序記錄個數n較少的情況,但對于n較大的文件還是很有效的。
8.5歸并排序
-
基本思想:將兩個或兩個以上的有序子序列“歸并”為一個有序序列。
-
在內部排序中,通常采用的是2-路歸并排序。
- 即:將兩個位置相鄰的有序子序列R[l…m]和R[m+1…n]歸并為一個有序序列R[l…n]

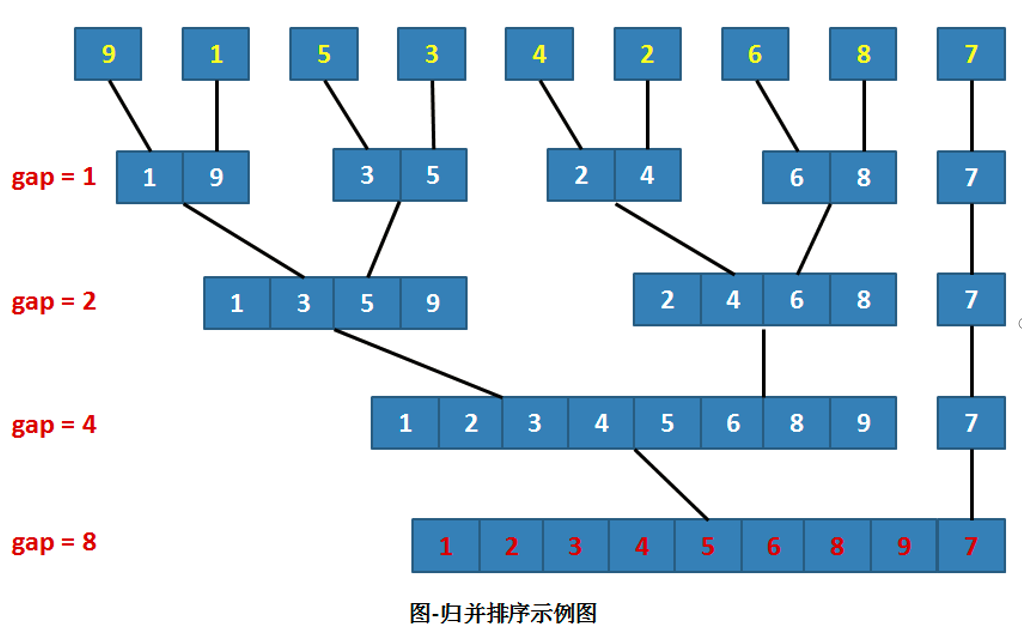
關鍵問題:如何將兩個有序序列合成一個有序序列?
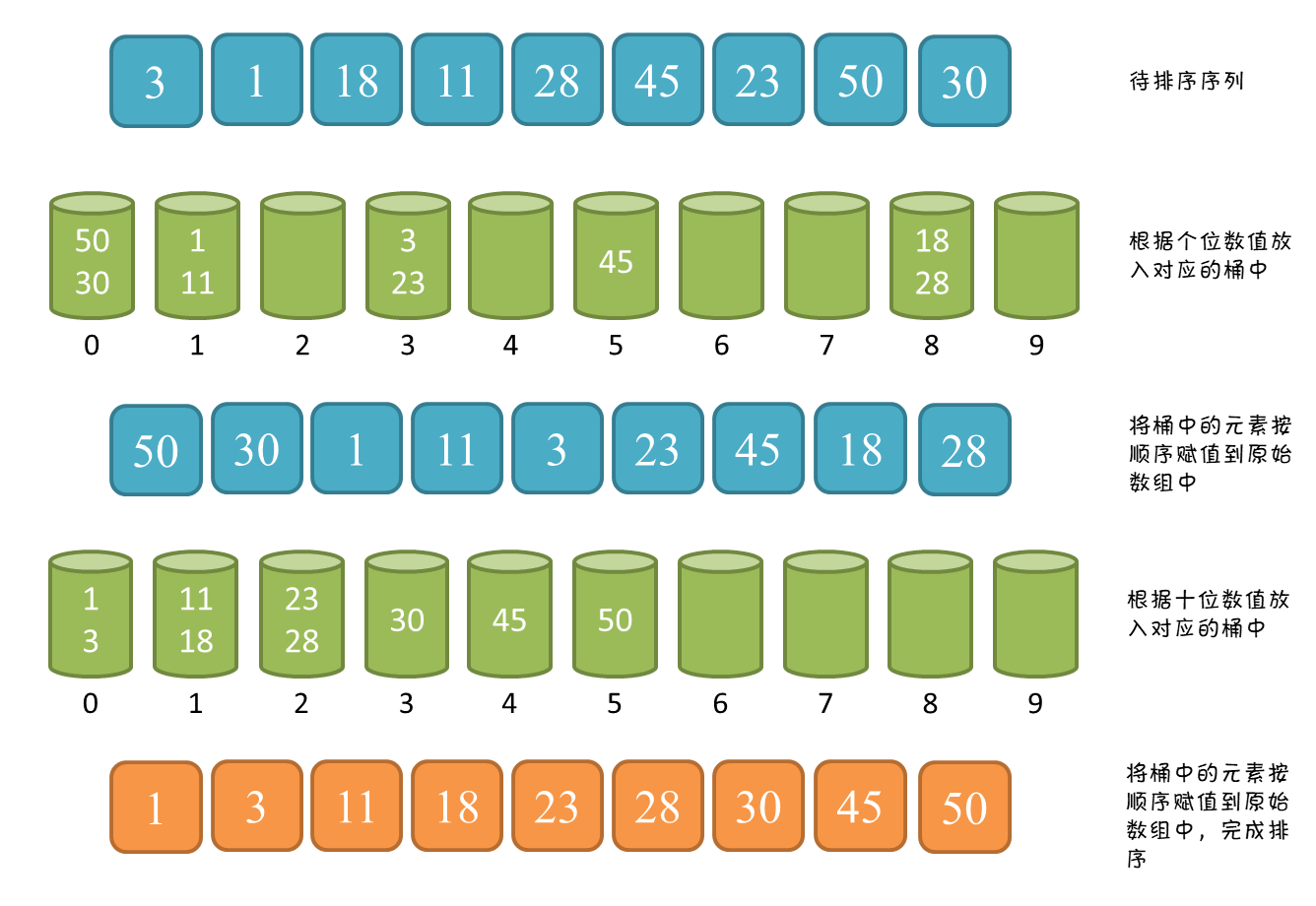
8.6基數排序
基本思想:分配+收集
也叫桶排序或箱排序:設置若干個箱子,將關鍵字為k的記錄放入第k個箱子,然后在按序號將非空的連接。
基數排序:數字是有范圍的,均由0-9這十個數字組成,則只需設置十個箱子,相繼按個、十、百…進行排序。
8.7各種排序方法比較
一、時間性能
- 按平均的時間性能來分,有三類排序方法:
- 時間復雜度為O(nlogn)的方法有:、
- 快速排序、堆排序和歸并排序,其中以快速排序為最好;
- 時間復雜度為O(n2)的有:
- 直接插入排序、冒泡排序和簡單選擇排序,其中以直接插入為最好,特別是對那些對關鍵字近似有序的記錄序列尤為如此;
- 時間復雜度為O(n)的排序方法只有:基數排序。
- 時間復雜度為O(nlogn)的方法有:、
- 當待排記錄序列按關鍵字順序有序時,直接插入排序和冒泡排序能達到O(n)的時間復雜度;而對于快速排序而言,這是最不好的情況,此時的時間性能退化為O(n2),因此是應該盡量避免的情況。
- 簡單選擇排序、堆排序和歸并排序的時間性能不隨記錄序列中關鍵字的分布而改變。
二、空間性能
? 指的是排序過程中所需的輔助空間大小
- 所有的簡單排序方法(包括:直接插入、冒泡和簡單選擇)和堆排序的空間復雜度為O(1)
- 快速排序為O(logn),為棧所需的輔助空間
- 歸并排序所需輔助空間最多,其空間復雜度為O(n)
- 鏈式基數排序需附設隊列首尾指針,則空間復雜度為O(rd)
三、排序方法的穩定性能
- 穩定的排序方法指的是,對于兩個關鍵字相等的記錄,它們在序列中的相對位置,在排序之前和經過排序之后,沒有改變。
- 當對多關鍵字的記錄序列進行LSD方法排序時,必須采用穩定的排序方法。
- 對于不穩定的排序方法,只要能舉出一個實例說明即可。
- 快速排序和堆排序是不穩定的排序方法。
四、關于“排序方法的時間復雜度的下限”
-
本章討論的各種排序方法,除基數排序外,其它方法都是基于“比較關鍵字”進行排序的排序方法,可以證明,這類排序法可能達到的最快的時間復雜度為O(nlogn)。
(基數排序不是基于“比較關鍵字”的排序方法,所以它不受這個限制)
-
可以用一棵判定樹來描述這類基于“比較關鍵字”進行排序的排序方法。




京東商品列表頁面數據獲取方法,京東API實現批量商品數據抓取示例)







_正則表達式)






